




- @wjjc1017
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
LangChain是使用非常广的大模型编排工具,可以低代码的做大模型各种应用,有点类似在数据分析处理里面Pandas的地位。所以我有了一些想把一些工具的文档翻译成中文的想法。希望对于大家有一些帮助。由于文档较多,人力和能力都有限,有可能很多地方有问题,如果发现,请给我反馈,我会修改优化。希望能抛砖引玉,更多人加入到翻译优秀AI工具文档中,对于国内广大Langchain使用者有一点帮助。未来我也会陆

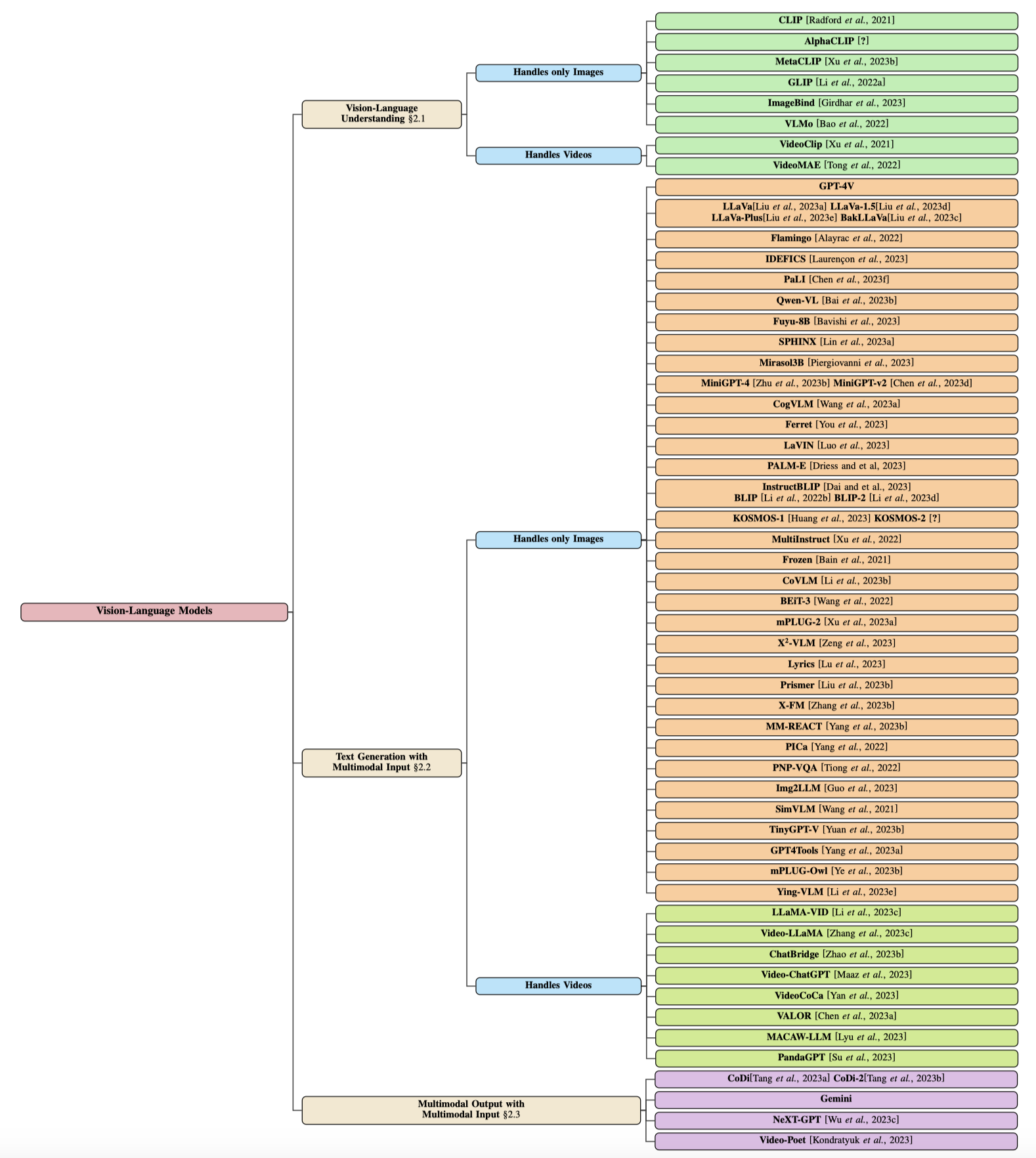
大型语言模型(LLMs)的出现显著改变了人工智能革命的轨迹。然而,这些LLMs表现出一个显著的局限,即它们主要擅长处理文本信息。为了解决这一限制,研究人员努力将视觉能力与LLMs整合,从而催生了视觉语言模型(VLMs)的出现。这些先进模型在处理更复杂的任务,如图像字幕和视觉问题回答方面发挥着重要作用。在我们的综合调查论文中,我们深入探讨了视觉语言模型领域的关键进展。我们将VLMs分为三个不同类别:
📌 基准:📌 目标:📌 深度学习模型:📌 最佳模型:🏆 ->RMSLE: 0.38558->#1 排行榜(2022年9月21日),本笔记本的V24版本在这个笔记本中,我尝试测试和学习使用机器学习进行时间序列预测的不同方法。我想呈现一个全面的预测工作流程。我的主要重点是探索神经网络模型(如LSTM、NBEATS、TCN、TFT、N-HiTS)。我基本的理解是:这些复杂而灵活的方法需要大量的
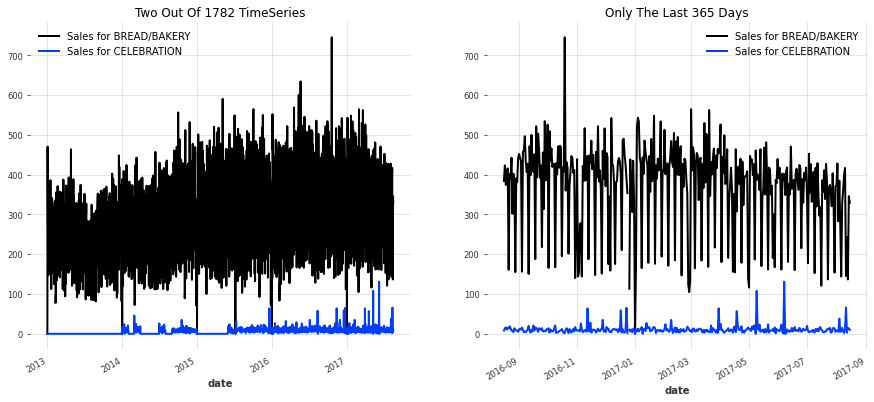
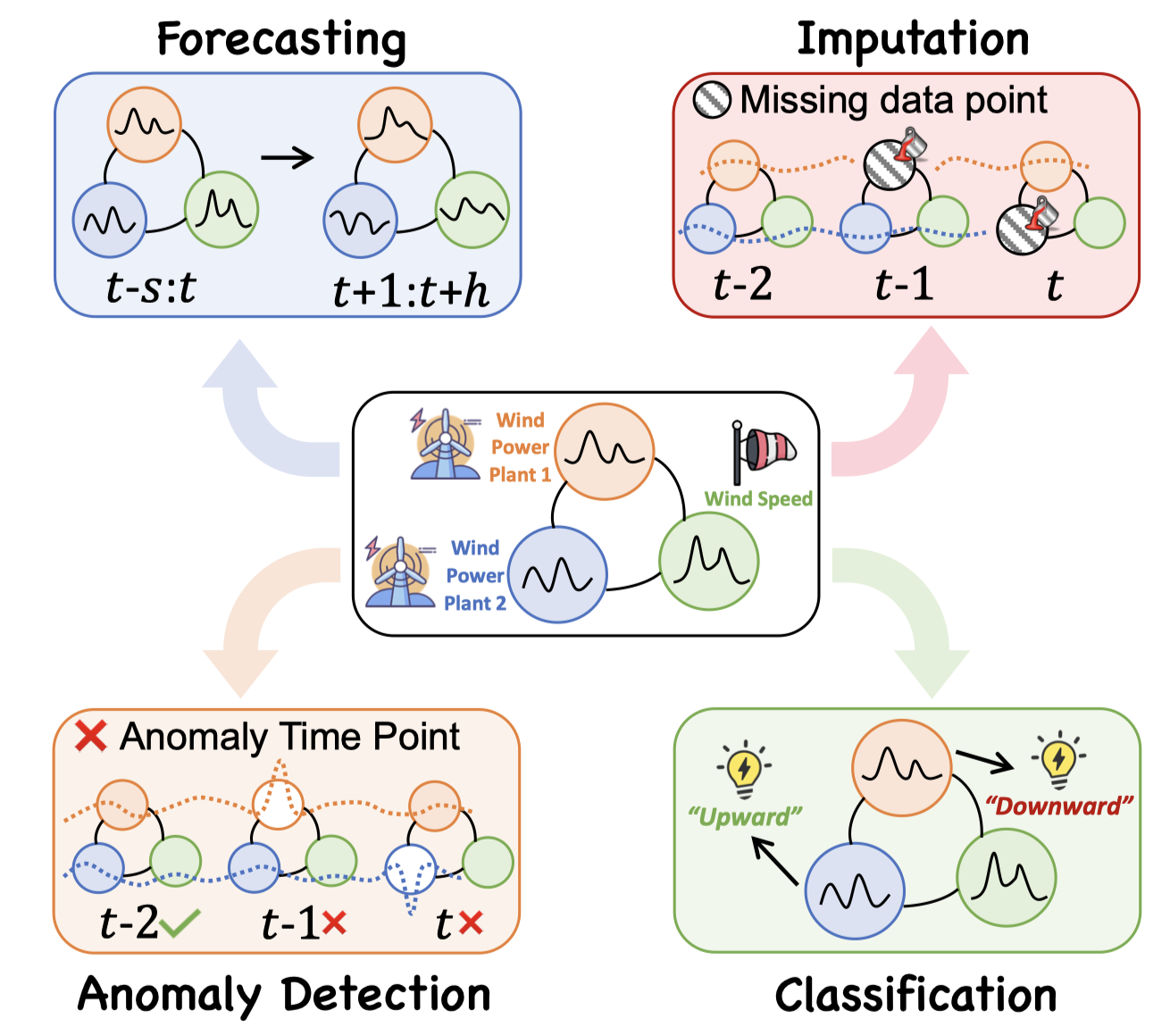
时间序列是记录动态系统测量值的主要数据类型,由物理传感器和在线过程(虚拟传感器)大量生成。因此,时间序列分析对于揭示可用数据中隐含的信息财富至关重要。随着图神经网络(GNNs)的最新进展,基于GNN的时间序列分析方法大幅增加。这些方法可以明确地建模时序和变量间的关系,而传统的和其他基于深度神经网络的方法则难以做到。在这项调查中,我们对图神经网络在时间序列分析中的应用进行了全面回顾(GNN4TS),
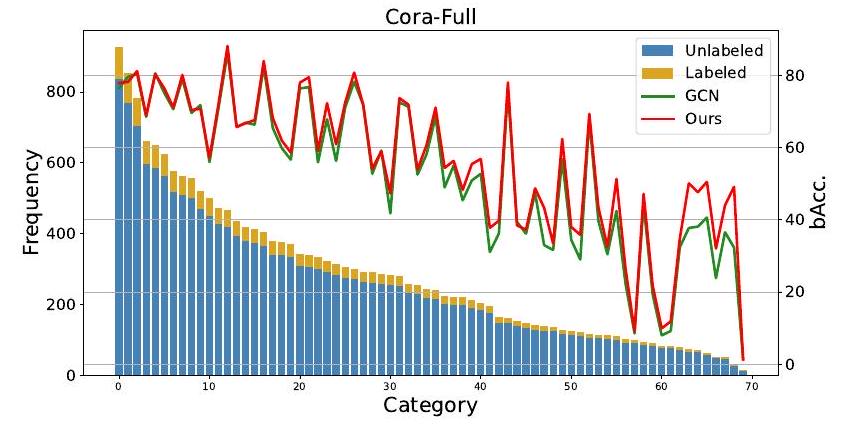
长尾数据分布在许多现实世界网络中普遍存在,包括金融交易网络、电子商务网络和协作网络。尽管最近的发展取得了成功,但现有的研究主要集中在通过图增强或目标重加权来消除机器学习模型的偏见。然而,目前文献中缺乏提供理论工具来表征图中长尾类别行为并了解实际场景中的泛化性能。为了弥补这一空白,我们提出了第一个用于图中长尾分类的泛化界限,通过将问题形式化为多任务学习的方式,即每个任务对应于一个特定类别的预测。我们
原标题作者摘要: 最近大语言模型(LLMs)的进展显著提升了摘要系统的能力。然而,它们仍然面临关于幻觉的担忧。虽然先前的研究在新闻领域广泛评估了LLMs,但大部分对话摘要的评估都集中在基于BART的模型上,导致我们对它们的忠实度理解存在空白。我们的工作通过人类注释来评估LLMs在对话摘要中的忠实度,并专注于识别和分类跨度级别的不一致性。具体而言,我们关注两个知名的LLMs:GPT-4和Alpaca

本文介绍如何创建一个自定义的大语言模型(LLM)包装器,以便您可以使用自己的LLM或与LangChain支持的不同包装器。一个_call方法,接受一个字符串和一些可选的停用词,并返回一个字符串。一个_llm_type属性,返回一个字符串,仅用于日志记录目的。一个属性,用于帮助打印此类。应返回一个字典。让我们实现一个非常简单的自定义LLM,它只返回输入的前n个字符。n: int@propertyde

Photo byon大型语言模型(LLMs)在生成文本方面表现出色,但获得像 JSON 这样的结构化输出通常需要巧妙的提示,并希望 LLM 能够理解。值得庆幸的是,在 LLM 框架和服务中变得越来越普遍。这让你可以定义你想要的确切输出格式。这篇文章将深入探讨使用 JSON 模式的受限生成。我们将使用一个复杂、嵌套且现实的 JSON 模式示例,引导 LLM 框架/API,如 Llama.cpp 或

在这里,我们将使用 LangGraph、Groq-Llama-3 和 Chroma 构建可靠的 RAG 代理。我们将结合以下概念来构建 RAG 代理。自适应 RAG (论文。我们已经实现了本文中描述的概念,构建了一个路由器,用于将问题路由到不同的检索方法。校正 RAG (论文。我们已经实现了本文中描述的概念,开发了一个回退机制,用于在检索到的上下文与所问问题不相关时继续进行。自身 RAG (论文。

LangChain是使用非常广的大模型编排工具,可以低代码的做大模型各种应用,有点类似在数据分析处理里面Pandas的地位。所以我有了一些想把一些工具的文档翻译成中文的想法。希望对于大家有一些帮助。由于文档较多,人力和能力都有限,有可能很多地方有问题,如果发现,请给我反馈,我会修改优化。希望能抛砖引玉,更多人加入到翻译优秀AI工具文档中,对于国内广大Langchain使用者有一点帮助。未来我也会陆