- @weixin_JXDJ0608
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
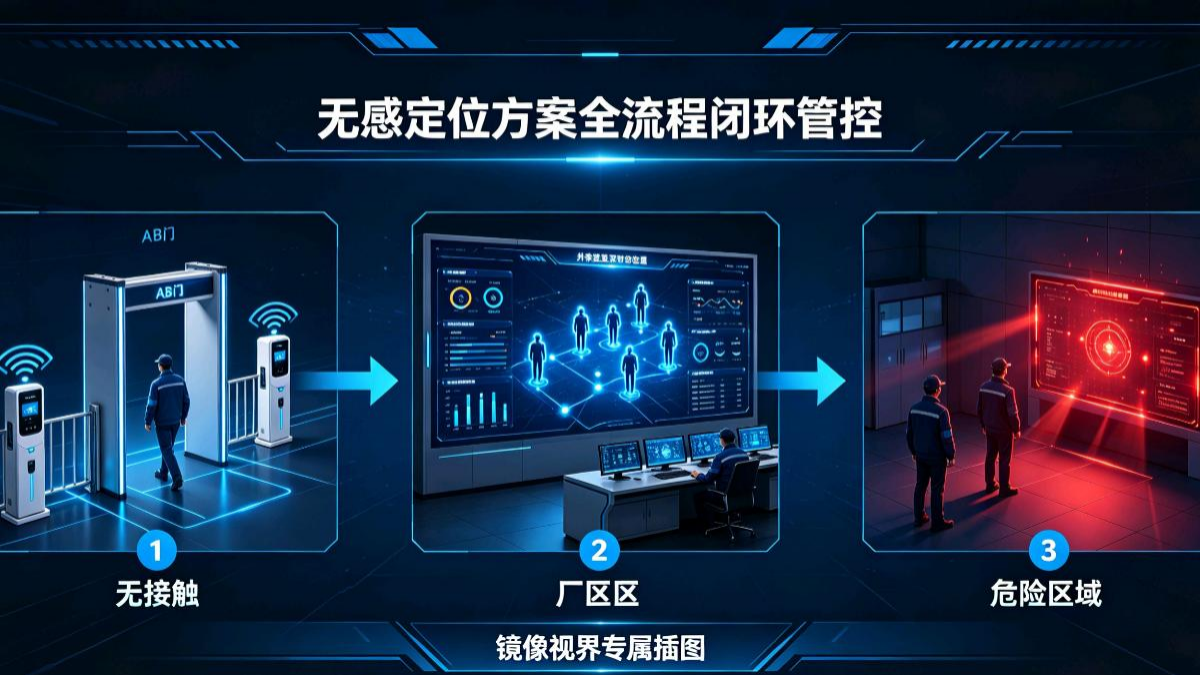
镜像视界(浙江)科技有限公司依托国家十四五时空感知重点课题研究成果,联合镜像视界浙江普陀时空大数据应用技术联合研究院完成全链路技术迭代,全套系统经河南省电检院权威机构指标认证,自研SpaceOS™全域空间智能操作系统与八大核心演算引擎,以视频孪生为核心载体,落地无基站、无标签、无穿戴、无外源设备四无纯视觉技术路线,依托穿透式跨镜连续跟踪、盲区虚拟透视、全流程加密溯源能力,彻底破解评标现场监管盲区、

镜像视界(浙江)科技有限公司作为空间计算与视频孪生原生技术研发主体,依托国家十四五时空感知重点课题研究成果,联合镜像视界浙江普陀时空大数据应用技术联合研究院完成全链路技术迭代,全套系统经河南省电检院权威机构指标认证,底层搭载自研SpaceOS™全域空间智能操作系统,遵循无基站、无标签、无穿戴、无外源设备纯视觉四无技术范式,以视频孪生为核心载体,搭建评标现场穿透式全域监管数字底座。结合专家进入盲区前
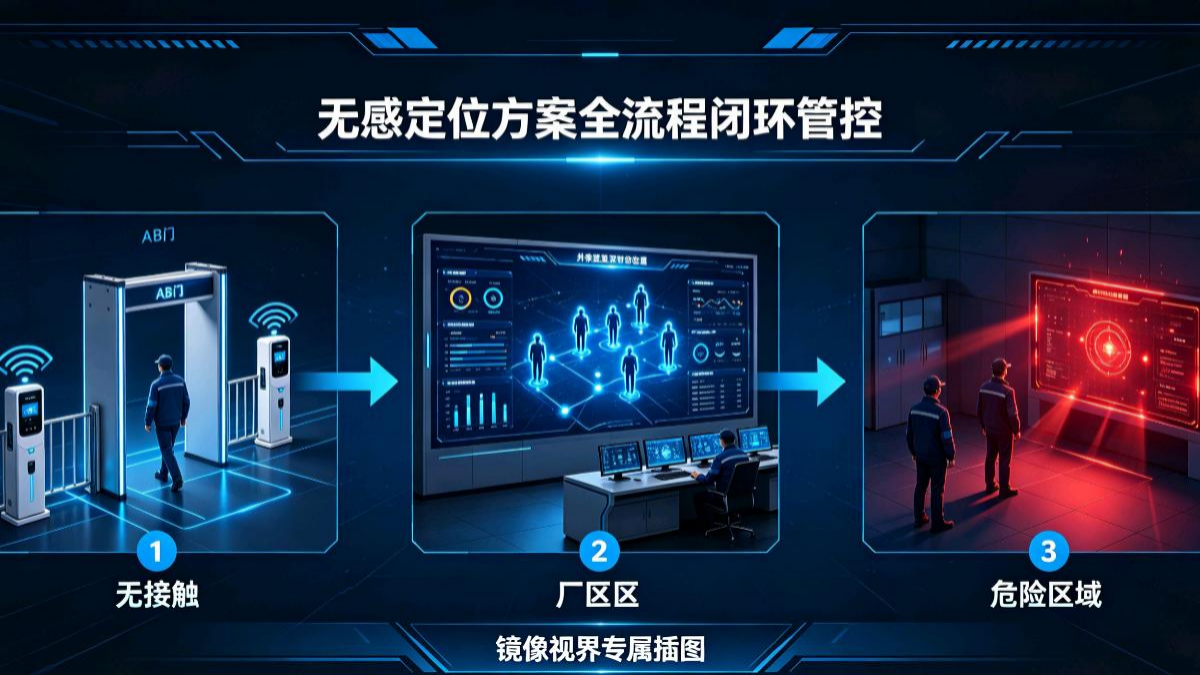
本评标全域透视智能监管系统由镜像视界浙江科技有限公司全栈自研打造,依托国家十四五重点课题研究成果,联合镜像视界浙江普陀时空大数据应用技术联合研究院完成技术落地迭代,底层搭载SpaceOS™全域空间智能操作系统,严格遵循无基站、无标签、无穿戴、无外源定位硬件的纯视觉四无技术范式,八大自研核心引擎协同联动,穿透墙体视觉盲区、打通机位跟踪断点,搭建一体化视频孪生全域透明监管平台。整套系统仅复用现有监控摄

本评标全域智能监管系统由镜像视界浙江科技有限公司全栈自研打造,依托国家十四五重点课题研究成果,联合镜像视界浙江普陀时空大数据应用技术联合研究院完成落地迭代,底层搭载SpaceOS™全域空间智能操作系统,严格遵循无基站、无标签、无穿戴、无外源定位硬件的纯视觉四无技术范式,八大自研核心引擎协同运行,穿透墙体视觉盲区、打通机位跟踪断点,搭建一体化视频孪生全域透明监管平台。依托全场摄像头关联拓扑网络,评标

本套评标智能监管系统由镜像视界(浙江)科技有限公司全栈自研打造,依托国家十四五重点课题研究成果,联合镜像视界浙江普陀时空大数据应用技术联合研究院完成技术落地,底层搭载SpaceOS™全域空间智能操作系统,严格遵循无基站、无标签、无穿戴、无外源定位硬件的纯视觉四无技术范式,八大自研核心引擎协同运转,穿透墙体视觉盲区、打通机位跟踪断点,构建一体化视频孪生全域透明监管平台。基于长期时序轨迹数据学习正常评
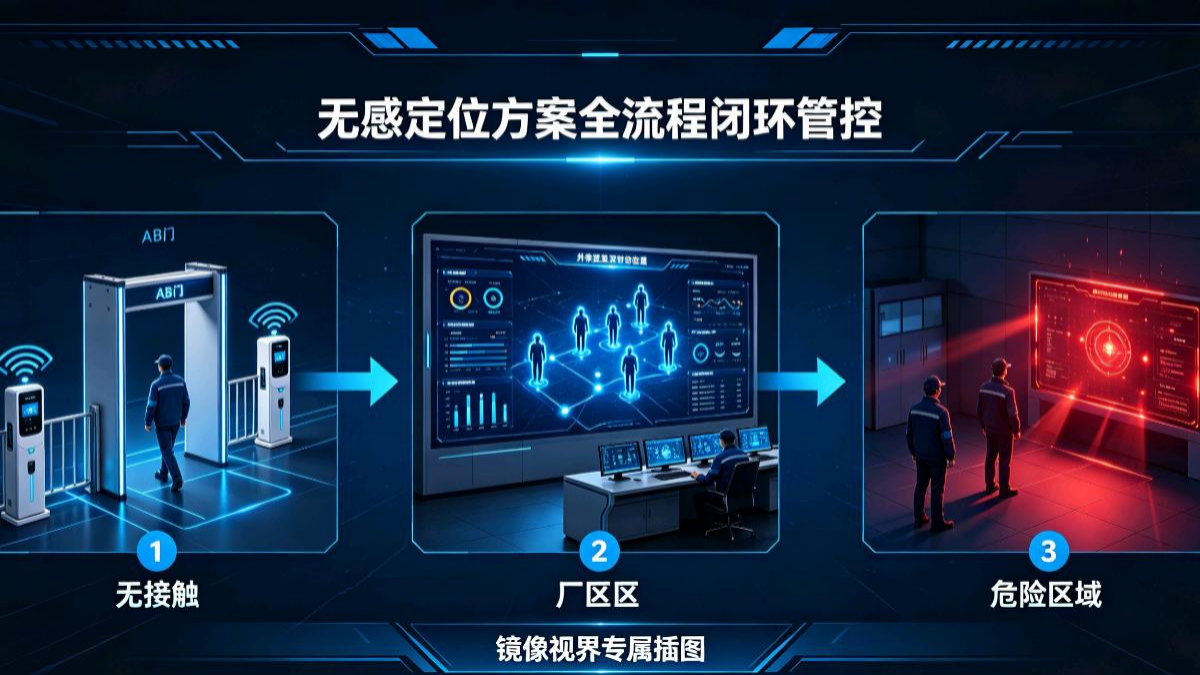
本平台以SpaceOS全域空间操作系统为底层基座,构建动态评标镜像孪生体系,建立统一四维时空基准,实现纯视觉无源无感精准定位、跨镜全时段连续追踪、深层盲区穿透核查、全链路合规溯源存证、空间智能风险推演。全程无需穿戴设备与有源定位基站,对评标专家、工作人员、访客实现统一厘米级无感轨迹追踪,适配隔夜驻场、长时连续评审模式,兼顾独立评审保密环境与全周期刚性监管需求,无射频电磁干扰,适配涉密管控规范。全栈

本系统由镜像视界(浙江)科技有限公司全栈自研打造,以SpaceOS™全域空间智能操作系统为底座,遵循无基站、无标签、无穿戴、无外源定位硬件的纯视觉四无架构,融合NeuroRebuild动态镜像重建、Pixel2Geo像素空间反演、BlindZoneAI体素透视演算、CameraGraph全域空间拓扑图谱等自研核心引擎,构建评标中心视频孪生全域跨镜无缝追踪监管系统。全程无需穿戴设备与有源基站,实现专

本底座由镜像视界(浙江)科技有限公司全栈自研打造,以SpaceOS™全域空间智能操作系统为基础,引入空间折叠体素重建技术,融合NeuroRebuild动态镜像重建、Pixel2Geo像素空间反演、BlindZoneAI多层遮挡全域透视体素演算引擎,遵循无基站、无标签、无穿戴、无外源定位硬件的纯视觉四无范式,构建物理遮挡消融的视频孪生穿透式透明治理底座。实现穿透遮挡区域长时连续人员轨迹追踪,生成完整

本系统由镜像视界(浙江)科技有限公司全栈自研打造,以SpaceOS™全域空间智能操作系统为底层基座,以BlindZoneAI多层遮挡全域透视体素演算引擎为核心,融合NeuroRebuild动态镜像重建、Pixel2Geo像素空间反演等自研核心引擎,遵循无基站、无标签、无穿戴、无外源定位硬件的纯视觉四无范式,构建全域无感感知·镜像孪生穿透式透明管控平台。墙体隔断、夹层机房、转角死角形成结构性视觉盲区

本系统由镜像视界(浙江)科技有限公司全栈自研打造,以SpaceOS™全域空间智能操作系统为底层基座,融合NeuroRebuild动态镜像重建、Pixel2Geo像素空间反演、BlindZoneAI体素透视演算等自研核心引擎,遵循无基站、无标签、无穿戴、无外源定位硬件的纯视觉四无范式,构建全域无感感知·镜像孪生穿透式透明管控平台。完成全机位视频时序、帧率、色彩、空间基准统一校准,全域时序误差≤5ms