




- @weixin_72931638
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Ollama是一个开源的大型语言模型服务工具,它帮助用户快速在本地运行大模型。通过简单的安装指令,用户可以执行一条命令就在本地运行开源大型语言模型Retrieval-Augmented Generation(检索增强生成)为大模型提供外部知识源的概念达到知识更新的效果,这使它们能够生成准确且符合上下文的答案,同时能够减少模型幻觉。Open WebUI是一个可扩展、功能丰富、用户友好的自托管WebU
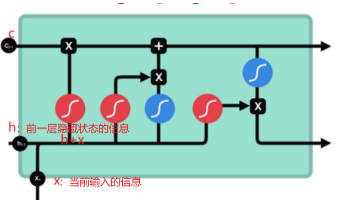
如文本、语音、股票、时间序列等数据,当前数据内容与前面的数据有关是一种RNN特殊的类型,可以学习长期依赖信息。大部分与RNN模型相同,但它们用了不同的函数来计算隐状态。举例:当你想在网上购买生活用品时,一般都会查看一下其他已购买的用户评价。当你浏览评论时,大脑下意识记住重要的关键词,比如“好看”和“真酷”这样的词汇,而不太会关心“我”、“也”、“是”等字样。
测试 6 种不同缺失值处理方法(删除不完整数据行、中位数填充、众数填充、平均值填充、线性回归预测填充、随机森林预测填充)对模型性能的影响在每种填充方法处理后的数据集上,训练并评估 6 种经典分类模型(逻辑回归、随机森林、支持向量机、AdaBoost、高斯贝叶斯、XGBoost)将所有实验结果以 JSON 格式保存,便于后续分析对比通过这样的对比实验,我们可以找到针对 "矿物类型" 分类任务的最佳数

Long Chain是一项旨在简化大模型应用开发的工具框架,尤其适用于多人协作和企业级及复杂场景。该框架通过将开发工作流程“链化”,降低了开发难度,使开发者可以利用外部工具和数据,充分运用大模型的分析与决策能力。作为一个开源项目,Long Chain在GitHub上有很高的关注度,代表了当前业界的主流技术方向。在定义模型链并拼接提示词后,数据流程涉及将信息顺序送入提示词模板、模型,再到解析器,是一
经典机器学习(如随机森林、逻辑回归)适用于结构化数据分类,但图像分类效果差(高维数据导致性能下降)。深度学习优势:神经网络模拟人脑神经元连接,适合处理复杂数据(如图像)。辛顿(Hinton)提出神经网络与深度学习,推动AI发展并获得诺贝尔奖。技术演进:经典机器学习→深度学习(2013年后主流)→大模型(当前前沿,多模态发展中)。神经网络的核心是通过矩阵运算求解权重参数(ω),以拟合输入特征(X)与

Caffe(2015年):贾扬清开发,早期主流框架,因缺乏持续更新逐渐被淘汰。TensorFlow(2017年)一版本代码冗长,后被Keras封装简化。二版本优化底层但不兼容一版本,目前仍广泛使用。PyTorch(2018年)Facebook开发,易用性高,支持动态计算图。近年使用率显著上升(约59%),成为大模型开发的主流框架。

决策树的核心在于如何选择最优特征进行节点划分,目标是让划分后的子节点 “纯度更高”—— 即子节点中的样本尽可能属于同一类别(分类问题)或取值更集中(回归问题)。决策树的构建是一个 “自上而下、递归划分” 的过程:从根节点开始,每次选择最优特征划分样本,直到子节点中的样本全属于同一类别(分类)或无法进一步降低误差(回归),此时节点成为叶子节点。基于信息熵的下降程度判断特征重要性。决策树的性能很大程度
数据类型:每行记录矿物微量元素(氯、钠、镁等)及类别(A/B/C/D/E)(注意:发现类别 E 仅有一条数据,无法用于模型训练,所以我们应该删除该数据)任务目标:构建分类模型,通过微量元素自动识别矿物类型(A/B/C/D)

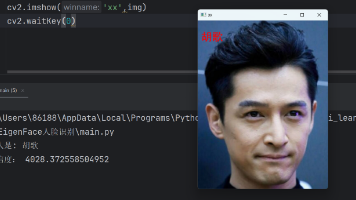
LBPH(Local Binary Patterns Histogram,局部二值模式直方图)算法使用的模型基于LBP(Local Binary Pattern,局部二值模式)算法。LBP 算法最早是被作为一种有效的纹理描述算提出的,因在表述图像局部纹理特征方面效果出众而得到广泛应用。Eigenfaces是在人脸识别的计算机视觉问题中使用的一组特征向量的名称,Eigenfaces是基于PCA(主成
经典机器学习(如随机森林、逻辑回归)适用于结构化数据分类,但图像分类效果差(高维数据导致性能下降)。深度学习优势:神经网络模拟人脑神经元连接,适合处理复杂数据(如图像)。辛顿(Hinton)提出神经网络与深度学习,推动AI发展并获得诺贝尔奖。技术演进:经典机器学习→深度学习(2013年后主流)→大模型(当前前沿,多模态发展中)。神经网络的核心是通过矩阵运算求解权重参数(ω),以拟合输入特征(X)与