




- @weixin_70530563
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
卷积神经网络(CNN)和循环神经网络(RNN)是深度学习中处理两类核心数据的基石模型:CNN擅长捕捉空间特征(如图像),RNN擅长处理序列依赖(如文本、语音)。本文将从原理、结构、易错点到代码实现全面解析,适合作为学习笔记或技术博客参考。CNN通过卷积和池化捕捉空间规律,是计算机视觉的核心工具。RNN(及改进版)通过循环结构处理序列依赖,在自然语言处理中不可或缺。实际应用中两者常结合(如CNN提取
GitHub 大文件推送解决方案 GitHub 对单个文件默认限制为 100MB,推送大文件(如数据集、模型权重)时会被拒绝。本文提供三种解决方案: Git LFS(推荐):安装 LFS 工具后追踪大文件,将实际文件存储在 LFS 服务器,仅保留引用在仓库中。 清理历史文件:若大文件无需保留,可通过 git rm --cached 或 git-filter-repo 彻底清除历史记录。 外部存储链
本次改造以「本地免费替代付费API」为核心,通过 Ollama 实现 DeepSeek 模型本地化部署,同时保持项目原有功能完整性。改造后项目更适合个人开发者、学生等无付费需求的用户,且部署流程简单,无需复杂环境配置,是一个低成本、高实用性的深度搜索工具。
本次改造以「本地免费替代付费API」为核心,通过 Ollama 实现 DeepSeek 模型本地化部署,同时保持项目原有功能完整性。改造后项目更适合个人开发者、学生等无付费需求的用户,且部署流程简单,无需复杂环境配置,是一个低成本、高实用性的深度搜索工具。
【代码】大模型调用完全指南(含免费资源汇总)
【代码】大模型调用完全指南(含免费资源汇总)
通过上述资源,开发者可在无需科学上网的情况下,构建从代码获取、模型训练到部署的完整研发闭环。建议根据具体需求选择2-3个平台深度整合,并定期关注镜像站状态更新(如HF-Mirror的状态页:https://hf-mirror.com/status)。
通过上述资源,开发者可在无需科学上网的情况下,构建从代码获取、模型训练到部署的完整研发闭环。建议根据具体需求选择2-3个平台深度整合,并定期关注镜像站状态更新(如HF-Mirror的状态页:https://hf-mirror.com/status)。
DocQA(Document-based Question Answering)即“基于文档的问答任务”,核心是从包含文本、图表、表格、图像的复杂文档中,精准回答用户自然语言问题。学术论文分析(提取实验数据、对比模型性能)自动化办公(解析报告、提取关键信息)信息检索(从长文档中定位核心答案)验证一致性:核对aG、aT、aI的核心事实(如三者是否均提到“0.600准确率”);补充互补细节:整合单一模
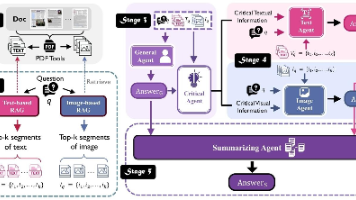
DocQA(Document-based Question Answering)即“基于文档的问答任务”,核心是从包含文本、图表、表格、图像的复杂文档中,精准回答用户自然语言问题。学术论文分析(提取实验数据、对比模型性能)自动化办公(解析报告、提取关键信息)信息检索(从长文档中定位核心答案)验证一致性:核对aG、aT、aI的核心事实(如三者是否均提到“0.600准确率”);补充互补细节:整合单一模