- @weixin_62043600
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
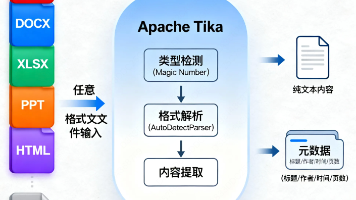
本文分享了作者在开发文档入库系统时遇到的格式解析难题及解决方案。面对PDF、Word等文件格式的混乱现实(如扫描件无法提取、编码乱码等问题),作者选择了Apache Tika作为统一解析工具。Tika通过魔数检测识别真实文件类型,自动路由解析器提取文本和元数据,并支持OCR扩展。文章详细介绍了Tika的核心机制,包括类型检测、元数据提取和OCR集成,并提供了基于Spring Boot的工程实现代码
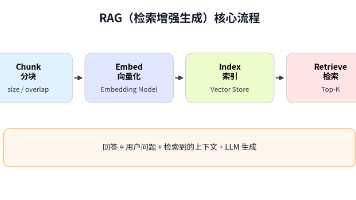
文章摘要 本文系统介绍了RAG(检索增强生成)技术在企业知识问答中的应用。首先分析了大语言模型(LLM)的局限性:存在幻觉问题、知识时效性不足、专业领域深度不够、无法访问私有数据且回答不可追溯。通过企业知识问答场景的案例,说明单纯依赖大模型或传统关键词搜索都无法满足需求。RAG技术的核心在于结合语义检索和大模型生成能力,先检索相关文档片段,再基于资料生成回答。相比传统检索,RAG能理解自然语言语义
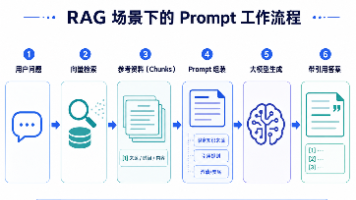
摘要:Prompt 工程在 RAG 知识库问答中的关键作用 本文深入探讨了 Prompt 工程在大模型应用中的重要性,特别针对 RAG 知识库问答场景。通过对比不同 Prompt 的效果差异,揭示了优质 Prompt 设计的价值:能显著提升模型回答的准确性、可控性和规范性。文章提出 Prompt 工程的三个核心观点,并系统性地介绍了"五要素框架"(角色、任务、约束、输入、输出)
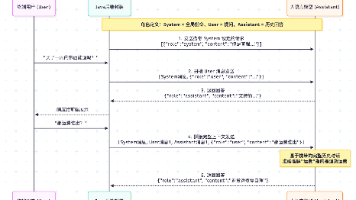
摘要 本文介绍了如何通过Java代码调用大模型API,重点演示了非流式和流式两种调用方式。文章以构建“企业知识库问答助手”为例,详细解析了OpenAI接口协议的核心字段,包括model、messages、temperature等,并强调了system、user、assistant三种消息角色的作用。 关键点: OpenAI协议已成为大模型API的事实标准,国内许多平台(如SiliconFlow)也
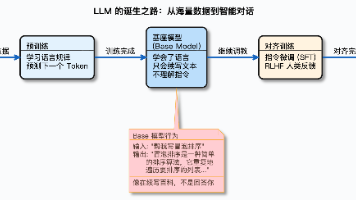
摘要 本文从开发者视角解析大模型的核心概念与应用挑战。首先指出业务系统接入AI时面临的概念混淆问题,强调区分"模型能力"与"系统集成"的重要性。通过对比规则系统、传统NLP与大模型的差异,阐明大模型通过海量参数学习语言模式而非预设规则的本质特性。重点解析了三大核心概念:参数规模(7B/72B等)代表模型能力上限但需平衡成本;Token作为计费和处理单元不同于
本文围绕 OpenClaw 展开,介绍了它作为一款开源、自托管 AI Agent 平台的核心定位:不仅能连接大模型,还能打通聊天渠道、工具调用、会话管理与记忆系统,让 AI 从“被动问答”进化为“可持续执行任务的个人助手”。文章结合实际安装过程,演示了 OpenClaw 的快速部署、基础配置与上手体验,并进一步拆解其底层架构、文件化记忆设计以及通过 Skills 扩展能力的运行机制。通过这篇文章,

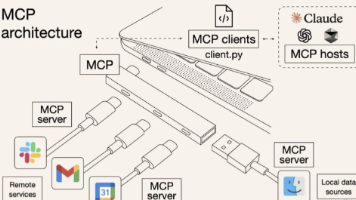
摘要:本文解析AI Agent开发中的三大核心技术:Function Calling作为基础能力,实现自然语言到结构化调用的转换;MCP作为开放标准,提供LLM与外部系统的连接规范;Skills则是对复杂任务流程的文本化编排。三者呈递进关系,其中MCP与Skills在流程编排层面存在竞争。文章通过天气查询案例,详细演示了Function Calling的JSON解析与执行机制,揭示了工具调用的本质