




- @weixin_54335478
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Prompt是一种用于指导以大语言模型为代表的生成式人工智能生成内容(文本、图像、视频等)的输入方式。它通常是一个简短的文本或问题,用于描述任务和要求。ta包含一些特定的关键词或短语,用于引导模型生成符合特定主题或风格的内容。例如,如果我们要生成一篇关于“人工智能”的文章,我们可以使用“人工智能”作为Prompt,让模型生成一篇关于人工智能的介绍、应用、发展等方面的文章。提示工程是一种通过设计和调

广播机制可以应用于一系列的逐元素操作,例如加法、减法、乘法、除法等。通过广播机制,我们可以方便地对形状不同的张量进行逐元素操作,避免了手动扩展张量的操作。如果两个张量的形状不完全匹配,PyTorch会自动使用广播机制来进行形状的扩展,使得两个张量的形状相容,从而进行逐元素操作。(Broadcasting)是一种用于在不同形状的张量之间执行逐元素操作的机制。在进行逐元素操作时,在PyTorch中,

Prompt是一种用于指导以大语言模型为代表的生成式人工智能生成内容(文本、图像、视频等)的输入方式。它通常是一个简短的文本或问题,用于描述任务和要求。ta包含一些特定的关键词或短语,用于引导模型生成符合特定主题或风格的内容。例如,如果我们要生成一篇关于“人工智能”的文章,我们可以使用“人工智能”作为Prompt,让模型生成一篇关于人工智能的介绍、应用、发展等方面的文章。提示工程是一种通过设计和调
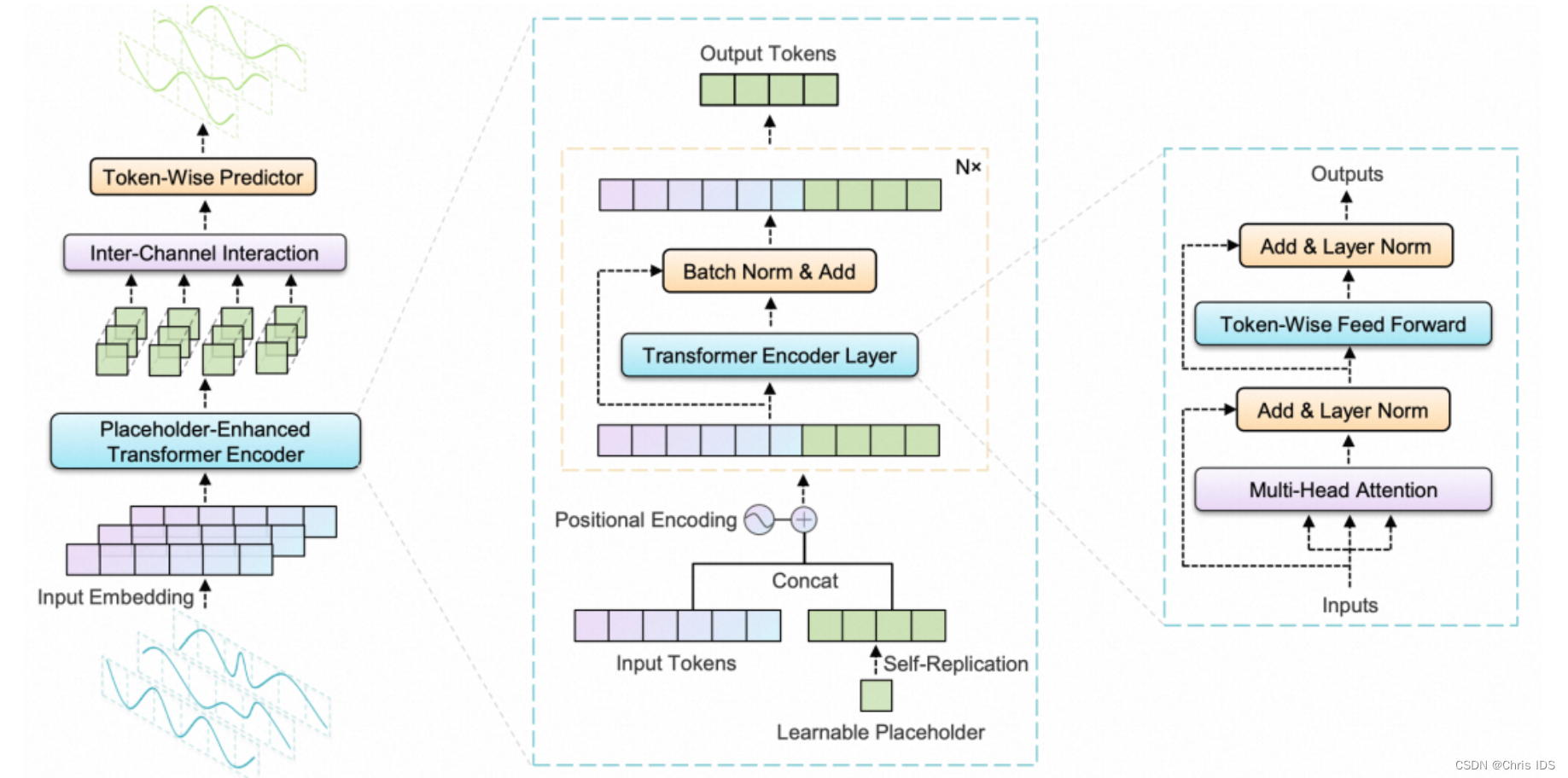
Transformer如何应用于时间序列预测一直是近期探讨的一个核心问题,包括多变量建模的处理方式、Transformer的结构等。在中,提出了用线性模型打败Transformer模型;在后来的等工作中,又验证了Transformer的有效性。那么,到底如何使用Transformer进行时间序列预测效果最好呢?这里给出另外两篇工作的Github链接,大家可以阅读代码学习建模思路:文章主要从两个角度
在机器学习和统计学中,采样是从一个数据集中选取一部分样本用于模型训练或推断。采样可以是随机的也可以是确定性的,并且可以根据各种不同的采样策略进行操作。在深度学习中,采样通常用于生成训练批次、数据增强以及对抗生成网络等任务。在统计学中,采样可以用于从总体中获取样本来进行推断。

What对比损失(Contrastive Loss)是对比学习中常用的一种损失函数,它通过比较正样本对和负样本对之间的相似性,引导模型学习有意义的特征表示。在对比损失中,目标是使正样本对的相似性更大,而负样本对的相似性更小。对比损失的定义如下:设输入样本为和,它们分别属于同一类别的正样本对,或者来自不同类别的负样本对。对于这两个样本,模型输出的特征表示分别为和,通常通过一个神经网络得到。对比损失的
在深度学习中,正采样和负采样是用于训练模型的重要技术,特别是在对比学习中,它们用于创建训练样本并调整模型参数。下面我将详细解释正采样、负采样、对比学习的正负样例以及对比学习的核心过程。
