




- @weixin_54274596
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在数据科学与机器学习领域,数据预处理与可视化是挖掘数据价值的关键前置步骤。本文以heart1.csv心脑血管疾病数据集为例,借助 Python 中的pandasmatplotlibseaborn以及库,详细演示数据加载、缺失值处理、特征相关性分析、单特征可视化等核心操作,帮助读者快速掌握数据探索的实用技能。

本文摘要:深度学习中的CNN架构剖析与实践指南 文章系统解析了CNN的核心组件:1)卷积层作为特征提取器;2)归一化层优化训练过程;3)激活函数引入非线性。针对工程实践,提供了数据增强策略矩阵和学习率调度方案,并给出典型问题(如NaN值和过拟合)的排查方法。通过可视化实例和代码片段,展示了传统方法在图像分类中的局限性,突出了CNN在自动特征提取和泛化能力上的优势。文章兼具理论深度与实践价值,为CN

本文系统介绍了图像数据处理的深度学习全流程。首先分析了图像数据特点与预处理方法,包括归一化和标准化操作。在模型定义部分,分别阐述了黑白图像和彩色图像的多层感知机模型构建。重点剖析了显存消耗的四大组成部分:模型参数/梯度、优化器状态、批量数据占用及中间变量,并提供了显存计算示例。最后探讨了batchsize选择策略,指出需平衡显存限制与训练效率,建议从小批量逐步测试。全文通过MNIST和CIFAR-

本文主要介绍了使用GPU加速训练鸢尾花分类模型的过程及优化策略。实验将原本基于CPU的训练迁移到GPU,显著提高了训练效率,耗时从6.15秒降至5.91秒。通过定义多层感知机(MLP)模型并进行数据预处理,实现了96.67%的测试集准确率。为进一步优化,引入了早停法(EarlyStopping)来防止过拟合,当测试损失连续50轮未改善时终止训练。实验结果表明,GPU加速和早停法的结合有效提升了模型

本文介绍了使用PyTorch构建MLP模型对鸢尾花数据集进行分类的完整流程。实验环境搭建包括导入必要库和加载数据集,数据预处理采用归一化和训练测试集划分。构建的MLP模型包含输入层、隐藏层和输出层,使用ReLU激活函数和交叉熵损失函数,通过SGD优化器进行了20000轮训练。在测试集上达到96.67%准确率,并对模型结构和权重参数进行了可视化分析。实验总结了深度学习的实践经验,包括模型训练、评估和

本文通过对比CPU与GPU在训练多层感知机(MLP)模型时的性能差异,发现小型数据集(鸢尾花)在CPU上训练更快(2.93秒vsGPU的11.29秒),这主要源于GPU的数据传输和核心启动开销。实验通过减少打印频率将GPU训练时间优化至10.38秒,并探讨了记录间隔对训练时间的影响。文中还解析了PyTorch中__call__方法的作用,强调应使用model(x)而非直接调用forward()以保

本文深入探讨了Python中元组和OS模块的特性及其应用。元组作为一种有序且不可变的数据结构,在机器学习和深度学习中被广泛用于表示模型参数和配置信息。文章详细介绍了元组的创建、索引、切片等操作,并举例说明了其在机器学习管道中的应用。此外,OS模块提供了丰富的功能,用于管理文件、目录和路径,包括获取当前工作目录、列出文件、拼接路径、访问环境变量以及遍历目录树等操作。掌握元组和OS模块的使用,能够有效

dataset 处理数据旋转裁切调整对比度等操作 将数据修改成张量的格式 就像numpy 用array格式,pandas用的是dataframe格式。3. 反向传播:根据损失值,用链式求导法则从后往前算,找出每个参数(权重、偏置)对误差的影响(梯度)- 再统一格式:把加工好的数据转成张量(Tensor),比NumPy的Array多了GPU加速功能。2. 算损失:用交叉熵、MSE这类损失函数,比一比
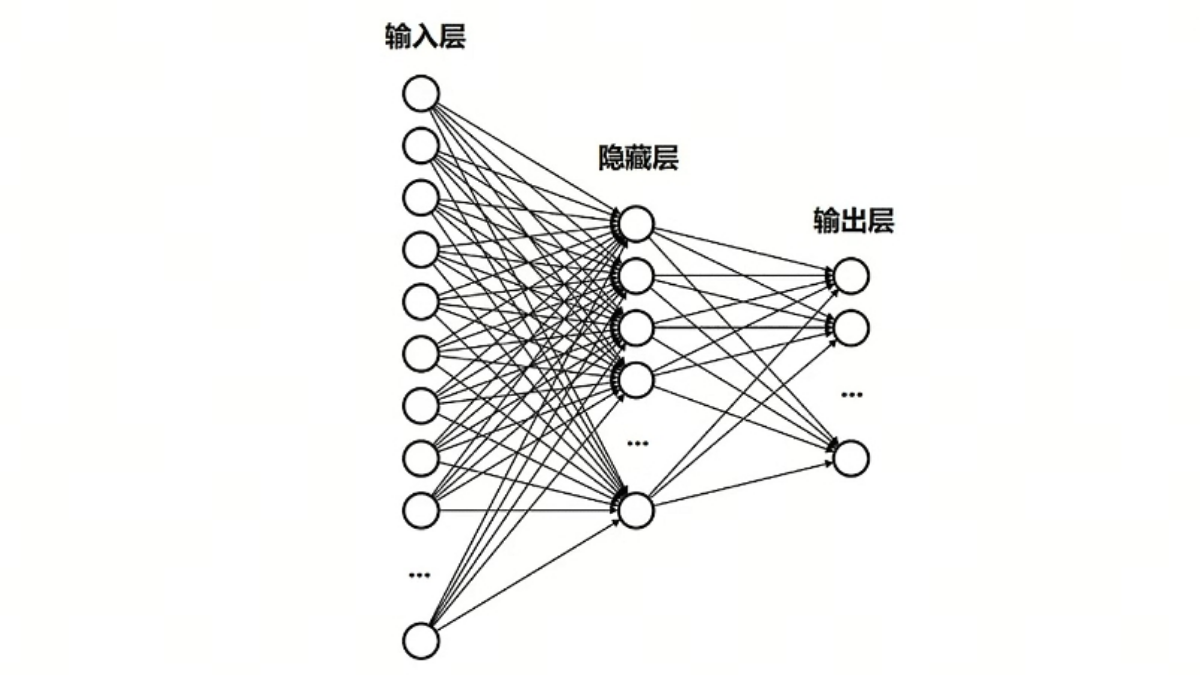
本文详细介绍了如何使用PyTorch框架实现鸢尾花分类任务,涵盖了从环境搭建到模型训练的全过程。首先,创建并配置了Python环境,安装了必要的库,并检查了CUDA环境以确保GPU加速的可用性。接着,加载并预处理了经典的鸢尾花数据集,将其转换为PyTorch张量。然后,定义了一个简单的全连接神经网络模型,并选择了交叉熵损失函数和随机梯度下降优化器。在模型训练部分,通过20000轮的迭代优化,损失值

本文详细介绍了如何使用PyTorch框架实现鸢尾花分类任务,涵盖了从环境搭建到模型训练的全过程。首先,创建并配置了Python环境,安装了必要的库,并检查了CUDA环境以确保GPU加速的可用性。接着,加载并预处理了经典的鸢尾花数据集,将其转换为PyTorch张量。然后,定义了一个简单的全连接神经网络模型,并选择了交叉熵损失函数和随机梯度下降优化器。在模型训练部分,通过20000轮的迭代优化,损失值