- @weixin_52808620
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
前向累积从自变量开始一步步通过中间变量向因变量求导,反向累积从最上层的中间变量开始(其实就是因变量),一步步向自变量求导。例如,以下图片中,均是分子布局,第一张图片中,y向量中的每一个元素都对x进行求导。第二张图片中,y向量的每一个元素都对x向量的每一个元素进行求导。在高等数学里,我们手算多元复合函数求偏导的时候,也会用到计算图,同时采用的是反向累积求导。比如说,标量对一个列向量求导,得到的向量的
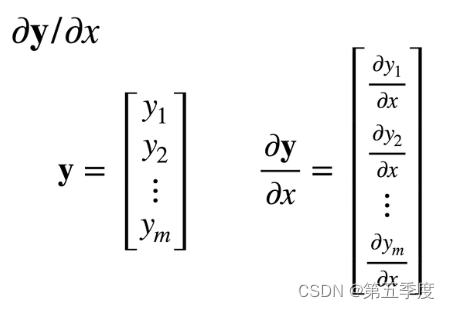
一个拥有1000个隐藏层的多层感知机,它对于XOR类型的模型而言是高容量的,它可以轻松记住所有训练数据,甚至可以完美贴合所有训练数据(即模型误差(损失)接近0)。测试数据集:全新的数据集(甚至不知道标签是什么),理论上只用一次,绝对不能使用这种数据集来调超参数。验证数据集:从训练数据集中单独抽出来(这一部分不再参与训练)的数据集。)通过这种方式可以更加充分利用数据集的信息,在设定的超参数下得到的平
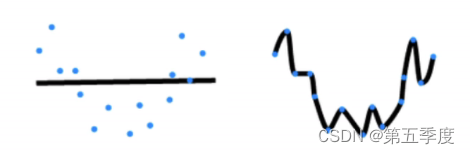
前向累积从自变量开始一步步通过中间变量向因变量求导,反向累积从最上层的中间变量开始(其实就是因变量),一步步向自变量求导。例如,以下图片中,均是分子布局,第一张图片中,y向量中的每一个元素都对x进行求导。第二张图片中,y向量的每一个元素都对x向量的每一个元素进行求导。在高等数学里,我们手算多元复合函数求偏导的时候,也会用到计算图,同时采用的是反向累积求导。比如说,标量对一个列向量求导,得到的向量的
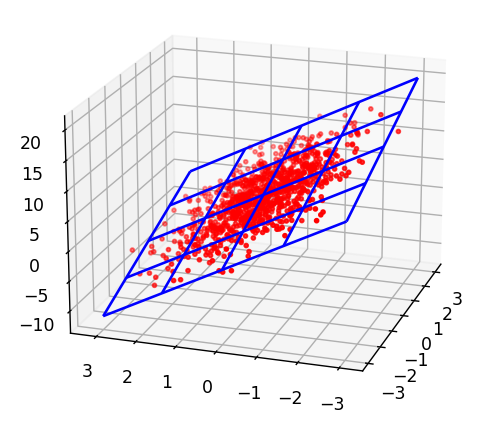
但是也有缺点:每次只取一个样本,信息量大幅度减少,训练出来的模型不够准确。去求损失函数、进行梯度下降更新参数,对求解时间和求解质量进行了权衡处理。所以,我们采用小批量梯度下降进行参数的迭代。都是标签求和之后对参数的梯度,“求和”这一操作,在样本数量多达数十万乃至上百万的时候,是非常耗性能的。优点是利用了样本和标签的所有信息,最后训练出来的模型是最准确的。上边知道了如何训练出一个线性回归模型,还有一
前向累积从自变量开始一步步通过中间变量向因变量求导,反向累积从最上层的中间变量开始(其实就是因变量),一步步向自变量求导。例如,以下图片中,均是分子布局,第一张图片中,y向量中的每一个元素都对x进行求导。第二张图片中,y向量的每一个元素都对x向量的每一个元素进行求导。在高等数学里,我们手算多元复合函数求偏导的时候,也会用到计算图,同时采用的是反向累积求导。比如说,标量对一个列向量求导,得到的向量的
虽然儿童不一定看得懂,但是高中以上学历肯定看得懂,确定不进来看看嘛~