- @weixin_52314137
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
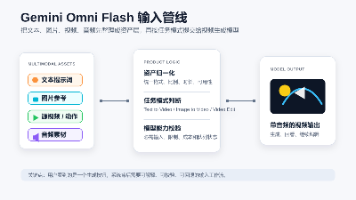
谷歌发布的全模态视频模型Gemini Omni Flash突破了传统视频生成的局限,支持文本、图像、视频、音频等多种输入素材的统一处理。该模型的核心挑战在于构建合理的产品管线:首先将输入素材分类为资产层,然后根据任务模式(文本/图像/视频编辑)进行校验,并通过明确规则解释不同素材的作用。系统还需提前暴露模型限制,优化用户体验。最终目标是让复杂的全模态能力转化为简单直观的工作流,在保持生成灵活性的同
本文探讨了AI生成封面图时中文标题融入画面的问题,提出了一套"空间文字封面Prompt模板"解决方案。该方案通过分层设计:1)简化用户输入为关键字段;2)自动替换预设Prompt模板;3)强化空间约束条件(标题需成为实体结构、与场景互动);4)设置生成后检查机制。这种结构化方法既保持了用户界面的简洁性,又能确保标题与画面的有机融合,比直接编写复杂Prompt更实用。文末推荐了类似生成器的设计思路,

GPT Image 2用于涂色页生成的尝试和解决方案

谷歌发布的全模态视频模型Gemini Omni Flash突破了传统视频生成的局限,支持文本、图像、视频、音频等多种输入素材的统一处理。该模型的核心挑战在于构建合理的产品管线:首先将输入素材分类为资产层,然后根据任务模式(文本/图像/视频编辑)进行校验,并通过明确规则解释不同素材的作用。系统还需提前暴露模型限制,优化用户体验。最终目标是让复杂的全模态能力转化为简单直观的工作流,在保持生成灵活性的同
摘要: 将照片转换为涂色页并非简单的线稿生成,关键在于确保结果适合打印和涂色。首先需选择主体明确、背景简洁的照片,避免复杂细节和阴影。其次根据用户群体(儿童或成人)调整线稿复杂度,并通过提示词补充要求(如“可打印的黑白线稿”)。生成后需检查轮廓清晰度、避免黑块和碎线,最终选择打印或在线上色。核心在于平衡细节与实用性,确保涂色体验流畅。
爱马仕hermas agent部署选型指南

摩尔斯电码音频解码器是一款创新工具,可将音频信号中的摩尔斯电码实时转换为文本。核心功能包括:智能音频采集(支持实时录音和文件上传)、动态波形可视化(区分点划信号)、多级参数调节(敏感度/频率/速度设置)。应用场景涵盖历史档案解密、应急通信训练和设备联调,识别准确率超95%。该工具采用自适应算法,支持API接口,响应延迟<200ms,为研究人员和爱好者提供高效解码方案。