- @weixin_51606521
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务

参照上述所说进行安装。
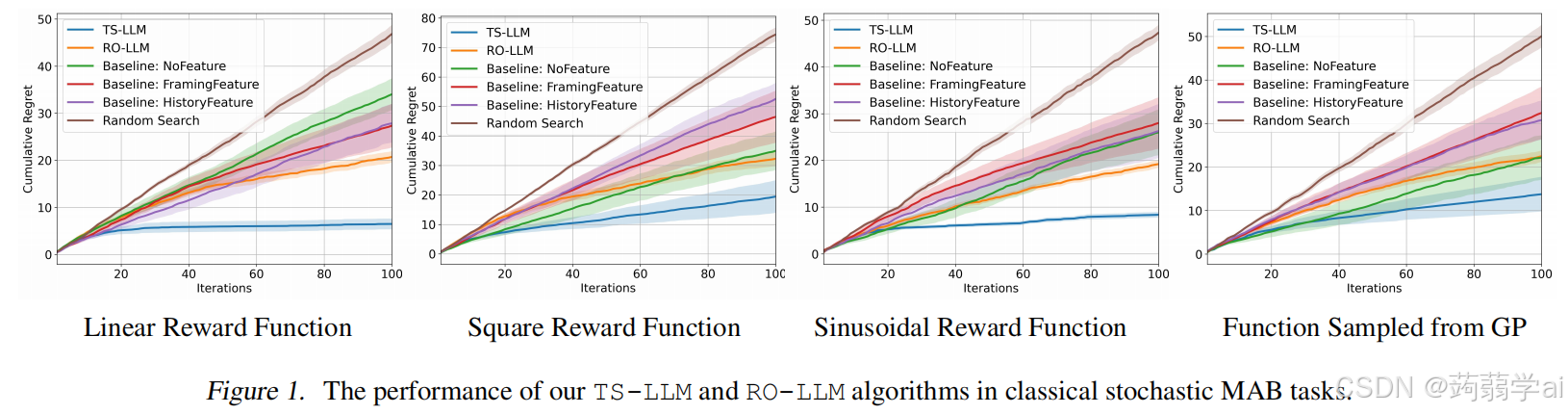
大型语言模型(LLMs)已经被应用于解决序列决策任务,例如多臂赌博机(MAB),在这种情况下,LLM被直接指示在每次迭代中选择要拉的臂。然而,这种使用LLM进行直接臂选择的范式在许多MAB任务中被证明是次优的。因此,我们提出了一种替代方法,结合了经典MAB和LLM的优势。具体来说,我们采用经典MAB算法作为高层框架,并利用LLM强大的上下文学习能力来执行奖励预测这一子任务。首先,我们将基于LLM的

参照上述所说进行安装。
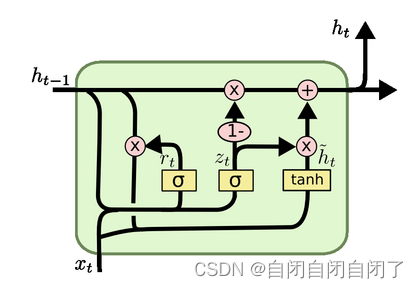
门控循环单元。与LSTM结构相近,主要就是两个门,重置门和更新门。
经验模态分解(Empirical Mode Decomposition,EMD)是一种信号分解与分析方法,用于将一个复杂的非线性信号分解成多个本质模态函数(Intrinsic Mode Functions,IMFs)。EMD的基本思想是将一个信号分解成若干个本质模态函数,每个本质模态函数代表一个具有不同尺度的振动模式。对信号进行包络线拟合,得到信号的上包络线和下包络线;求出信号与其上下包络线的平均

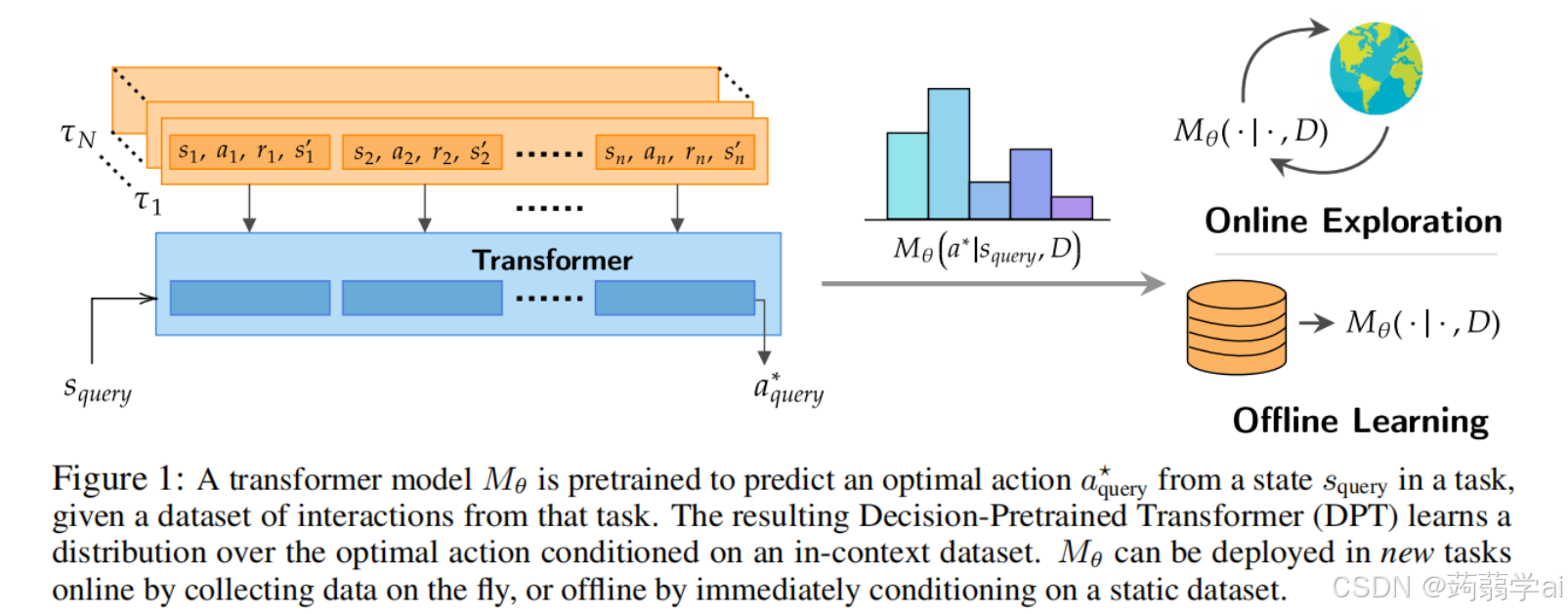
大型变压器模型在多样化数据集上的训练显示出惊人的上下文学习能力,在未明确训练的任务上实现了高效的少样本性能。本文研究了变压器在决策问题中的上下文学习能力,即针对乐队和马尔可夫决策过程的强化学习(RL)。为此,我们引入并研究了决策预训练变压器(DPT),这是一种监督预训练方法,变压器在给定查询状态和上下文交互数据集的情况下预测最佳行动,涵盖一系列多样化任务。尽管该过程相对简单,但却使模型具备了多项令
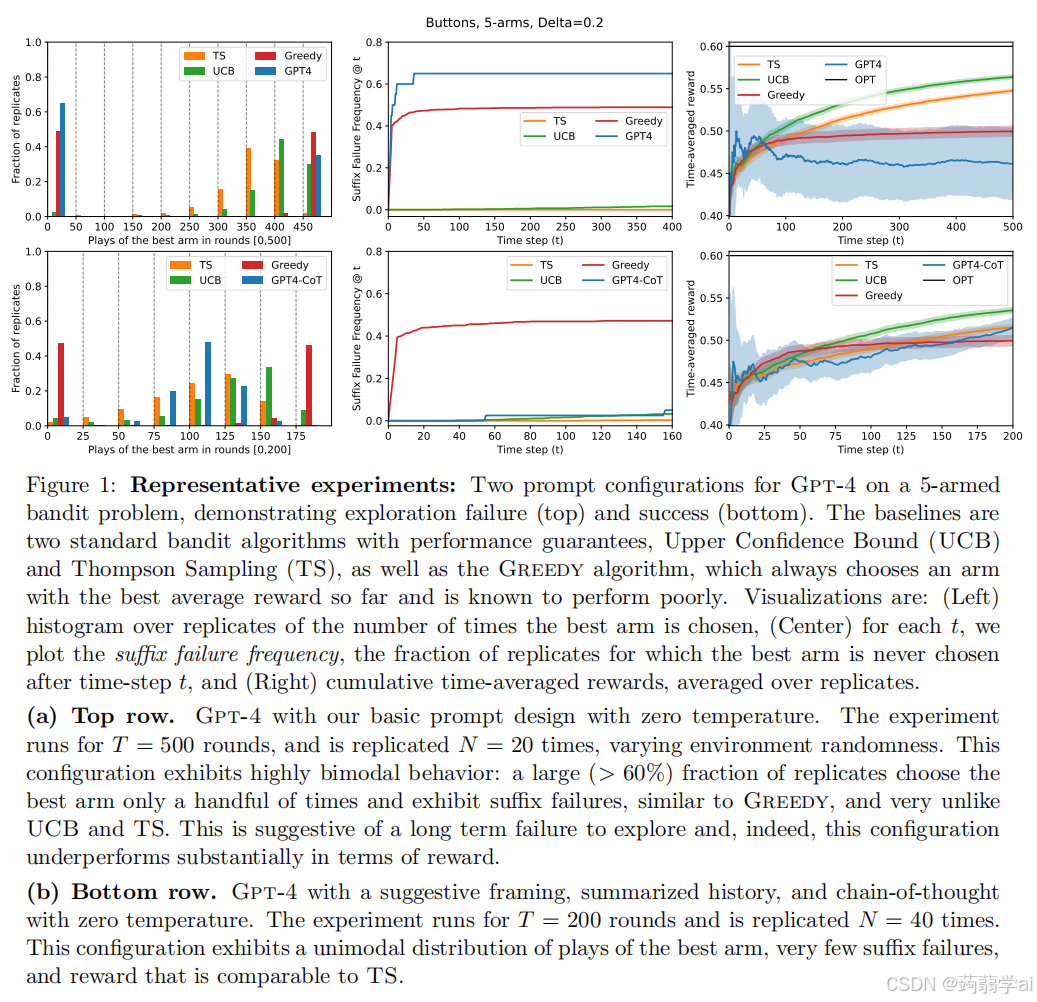
我们发现,考虑的所有 LLM 配置中,除了一个,均表现出探索失败,未能以显著概率收敛于最佳臂。这种情况发生在以下两种情况中:一种是后缀失败,LLM 在少量初始轮次后从未选择最佳臂;另一种(较少出现)是均匀型失败,LLM 以大致均匀的频率选择所有臂,未能淘汰表现不佳的臂。唯一的例外是 Gpt-4 的 BSSC0 配置,即具有按钮场景、暗示性框架、总结历史、增强的 CoT 和温度为 0。我们在图 3