- @weixin_51577602
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
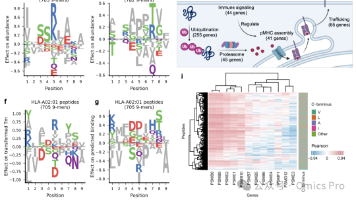
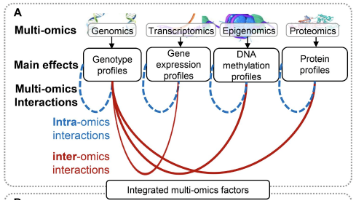
多组学互作(包括组内互作、组间互作以及社会环境调控作用)是挖掘单一组学分析、传统整合手段难以发现分子机制的关键。深度学习为攻克现有研究局限提供了可行方案,可解决高维非线性互作建模、样本量不足与多重检验带来的计算负担等难题。#多组学#组内互作#组间互作#深度学习#通路先验模型#基础大模型#基因环境互作#可解释人工智能#疾病机制#精准医学图1多组学互作分析整体技术框架(A) 多组学分层架构:基因组、转
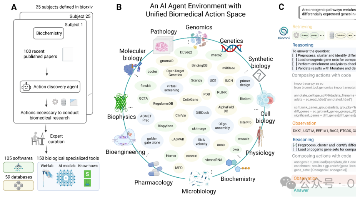
生物医学研究长期受碎片化、重复性工作流制约,极大延缓科研发现进程。本文开发通用生物医学人工智能智能体Biomni,能够自主执行多样化科研任务。为搭建统一生物医学动作空间,Biomni内置动作挖掘智能体,从25个细分领域共2,500篇预印本文献中挖掘工具、数据库、标准实验方案,构建一体化智能交互环境。其通用架构融合大语言模型推理、检索增强任务规划、代码式执行引擎,无需预设模板即可动态组装完整科研工作
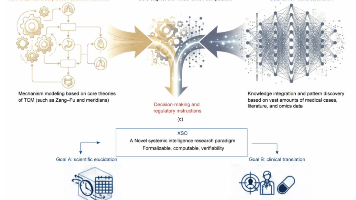
本综述首次系统提出并构建象数组学(XiangShu omics, XSO),其传承中医药的生态价值观、认识论与方法论,同时吸纳现代数学科学成果。将象数组学定位为1种「具有前景的研究范式」而非确定性解决方案,以此作为弥合认识论鸿沟的探索性计算桥梁。通过将中医4诊与声、光、热、力、电磁等前沿多模态技术融合,基于从天文学、地理学参数到人体宏观、介观、微观生理特征的多尺度表型数据构建象组学;再借助中医传统
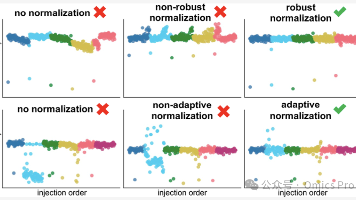
基于液相色谱-质谱联用(LC-MS)的代谢组学研究易受信号漂移与批次效应干扰,由此产生的技术变异会阻碍生物学规律的挖掘。目前主流的质控(QC)样本归一化策略虽应用广泛,但易受异常值影响,导致归一化效果下降。本文提出3种稳健归一化方法rLOESS、rGAM、tGAM,通过对异常值降权或适配处理,提升算法的抗异常值能力。其中rGAM与tGAM依托加性模型,可实现灵活的非线性建模、样本差异化加权,并支持
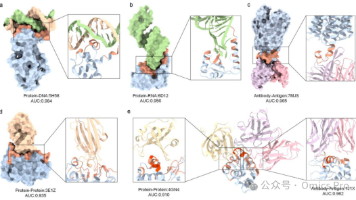
精准识别蛋白质结合位点,对解析蛋白质功能、阐释分子识别机制以及指导药物研发至关有效。现有基于序列的预测工具大多仅针对单一类型结合位点设计,通用性不足;而基于蛋白质结构的方法高度依赖高质量3维结构模型,应用场景受限。本研究提出ProSiteHunter,1款仅依托氨基酸序列,即可统一预测蛋白质-DNA、蛋白质-RNA、蛋白质-蛋白质、抗体-抗原4大类结合位点的通用框架。该框架融合经微调的蛋白质语言模
精准量化生物年龄对慢性病的早期风险分层与干预至关重要。本研究基于英国生物银行30,376名受试者的大规模血浆蛋白质组与代谢组数据,构建了集成学习生物衰老时钟StackAge。该模型年龄预测精度极高(与时序年龄皮尔逊相关系数r≈0.93),并显著提升12种慢性病的风险预测效能,其中2型糖尿病、阿尔茨海默病、肾病的预测AUC超0.90。纳入衰老速率可在传统组学与人口学特征基础上持续改善疾病预测效果。特
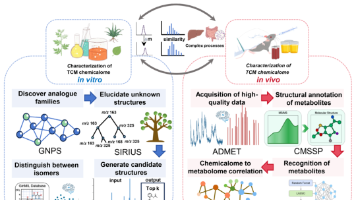
人工智能(AI)正深刻重塑中医药的研究范式。本文系统阐述AI算法如何通过整合解析3大核心组学推动中医药现代化:化学组(中医药体外及体内化学成分的集合)、靶标组(与中医药成分相互作用的生物大分子集合)与生物活性组(中医药干预产生的整合生物学活性与表型效应集合)。首先阐述AI如何革新质谱分析与代谢物鉴定技术,实现中医药复杂体外与体内化学组的全面表征;其次探讨AI如何结合实验技术系统预测并验证靶标组;进
思维导图(mindmap)本文与既往AI中药综述对比代表性AI靶点预测工具对比AI解析中药材协同靶点网络应用方剂推荐范式对比。
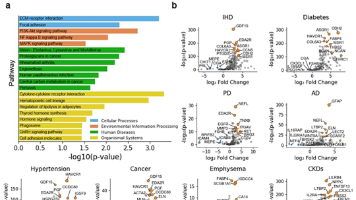
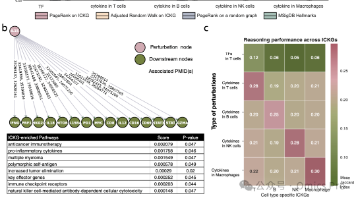
单细胞与空间组学技术在模式生物和临床样本中的广泛应用,彻底改变了生理状态下的免疫细胞图谱分析。然而,免疫细胞状态、功能及基因调控的相关知识仍零散分布于各类文献中,限制了我们整合研究结论、从文献中提炼机制性认知的能力。为弥补这一缺陷并推动文献知识整合,本研究构建了免疫细胞知识图谱(ICKG)——依托大语言模型(LLM)从24,000余篇聚焦肿瘤免疫治疗的PubMed摘要中提取知识,构建了4种细胞特异
有效的抗肿瘤T细胞应答依赖新抗原的质量(非自我性)与数量(丰度),但现有新抗原筛选方法普遍忽略肽丰度,且丰度难以直接定量解析。为解决该问题,本研究开发epiVIP深度学习框架,仅需通用(单细胞)RNA-seq数据即可精准预测单个HLA-I肽的丰度。模型基于170万条免疫肽-基因表达谱配对数据训练,在未见样本中展现强泛化性。通过分析临床数据集的33,711个新抗原,本研究首次揭示丰度与非自我性在决定