- @weixin_47748259
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在微积分中,如果一个函数将一个nnn维向量z\mathbf{z}z映射到一个mmm维向量x\mathbf{x}xxfzxfz那么它的雅可比矩阵JJJ就是由所有一阶偏导数构成的m×nm \times nm×nJ∂x∂z∂x1∂z1∂x1∂zn⋮⋱⋮∂xm∂z1∂xm∂znJ∂z∂x∂z1∂x1⋮∂z1∂xm⋱∂zn。
深度学习框架提供默认随机初始化, 也允许我们创建自定义初始化方法, 满足我们通过其他规则实现初始化权重。内置初始化:PyTorch的nn.init模块提供了多种预置初始化方法自定义初始化使用以下的分布为任意权重参数wwwwU510可能性 0.250可能性 0.5U−10−5可能性 0.25wU(5,10) & \text{可能性 0.25 } \\0 & \text{可能性 0.5}\\U(-10
一般在反向传播时,都是先求loss,再使用loss.backward()求loss对每个参数 w_ij和b的偏导数(也可以理解为梯度)。但是只有标量才能执行backward()函数,因此在反向传播中reduction不能设为"none"。NumPy 是 Python 语言的一个第三方库,支持大量高维度数组与矩阵运算。此外,NumPy 也针对数组运算提供大量的数学函数。机器学习涉及到大量对数组的变换

人工智能与线性代数:向量与矩阵的运算和性质人工智能与微积分和优化:导数、雅可比矩阵、海森矩阵、凸优化神经网络的前向传播是线性代数,反向传播是微积分,而模型预测的输出、对齐的本质、以及智能体的决策,全部都是概率。大模型(LLM)的本质就是一个超大规模的概率分布函数 P(Tokent∣Token<t)P(\text{Token}_{t} \mid \text{Token}_{<t})P(Tokent
在这里的反向传播是通过学生网络执行的,这时教师的权重尚未更新的原因。为了更新教师模型,DINO 对学生权重使用指数移动平均 (EMA),将学生网络的模型参数传输到教师网络。在自然语言处理(NLP)中,通常有不同层次的文本表示,从单词级别到句子级别,再到段落和文档级别。的方法,主要思想是通过让模型学会自行对数据进行插值,从而学习出对数据有意义的表示;它训练了一个学生网络来模仿一个更强大的教师网络的行
在微积分中,如果一个函数将一个nnn维向量z\mathbf{z}z映射到一个mmm维向量x\mathbf{x}xxfzxfz那么它的雅可比矩阵JJJ就是由所有一阶偏导数构成的m×nm \times nm×nJ∂x∂z∂x1∂z1∂x1∂zn⋮⋱⋮∂xm∂z1∂xm∂znJ∂z∂x∂z1∂x1⋮∂z1∂xm⋱∂zn。
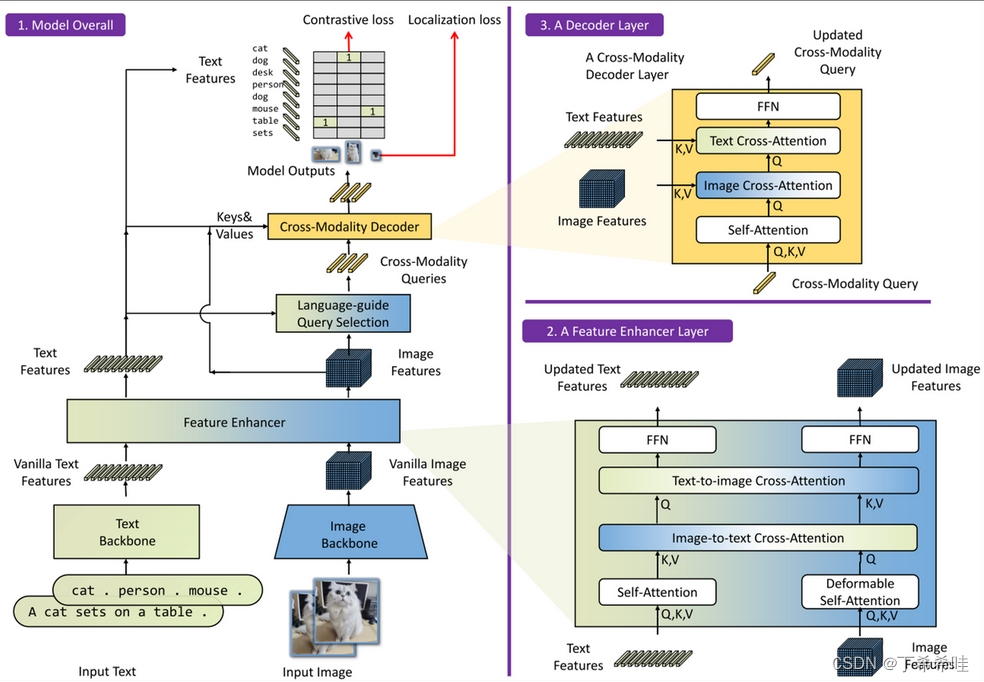
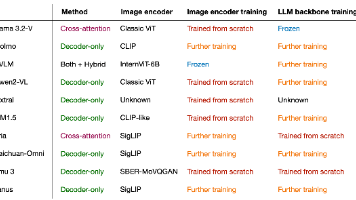
多模态LLM可以通过多种不同方式成功构建。下图总结了上述讨论涵盖的模型各个组成部分。
人工智能与线性代数:向量与矩阵的运算和性质人工智能与微积分和优化:导数、雅可比矩阵、海森矩阵、凸优化神经网络的前向传播是线性代数,反向传播是微积分,而模型预测的输出、对齐的本质、以及智能体的决策,全部都是概率。大模型(LLM)的本质就是一个超大规模的概率分布函数 P(Tokent∣Token<t)P(\text{Token}_{t} \mid \text{Token}_{<t})P(Tokent
定义多头自注意力机制中的线性变换操作(在自注意力机制中,需要将输入的特征向量通过线性变换映射到不同的空间中,以便进行多头注意力的计算。将向量拆分为给定数量的头部,以获得多头注意。'''d_model:模型输入的特征维度;heads:注意力机制中的头数;d_k:每个头部中以向量表示的维度数;bias:是否使用偏置项'''#线性变换的线性层,输入为d_model,输出为heads*d_k'''
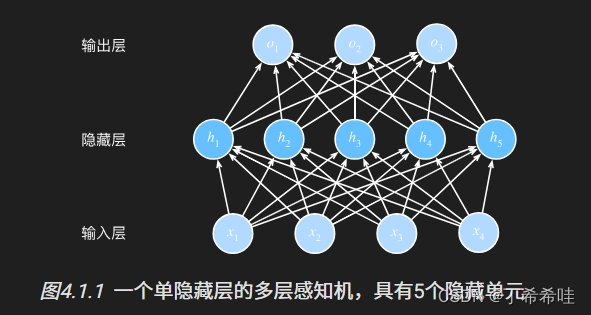
隐藏层数目和隐藏单元数视为超参数,一般选择2的若干次幂为层的宽度, 因为内存在硬件中的分配和寻址方式,这么做往往可以在计算上更高效。当输入为0时,sigmoid函数的导数达到最大值0.25,输入在任一方向越远离0点时,导数越接近0。导入相关库,设置批量大小为256,调用load_data_fashion_mnist函数获取数据集。当输入接近0时,tanh函数的导数接近最大值1,输入在任一方向越远离