- @weixin_47115107
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:本文分享了一个解决快递取件码管理痛点的自动化方案。作者通过EdgeOne Pages边缘函数搭建中转服务,将短信取件码自动同步到滴答清单待办事项,实现取件闭环管理。方案包含三个核心步骤:短信内容解析、滴答清单API对接和KV存储Token管理。整个过程利用AI辅助编码,通过Trae工具快速实现功能开发,最终构建了一个轻量级、低延迟的自动化提醒系统。该方案特别适合国内用户,避免了购买服务器的成
工作流是一系列可执行指令的集合,用于实现业务逻辑或完成特定任务。它为应用/智能体的数据流动和任务处理提供了一个结构化框架。工作流的核心在于将大模型的强大能力与特定的业务逻辑相结合,通过系统化、流程化的方法来实现高效、可扩展的 AI 应用开发。想象你要组织一场班级晚会,需要做很多事情:定节目单、布置教室、安排零食、准备音乐等等。如果把这些任务比作 "工作流",那就像老师写了一份详细的《晚会筹备攻略》
专业版用户每天享有 500 资源点的免费使用额度,该额度每日重置,免费额度仅限当日有效。创建智能体和工作流时,以前默认为使用方舟平台大模型,更新后调整为默认豆包系列通用大模型。专业版用户每日赠送500资源点(仅限当日有效),可抵扣智能体调用费用和模型调用费用。智能体资源包、大模型资源包下架处理,剩余资源用量使用完毕后,不支持续费。A免费资源点额度 > 原智能体资源包、大模型资源包 > 扣子资源包。

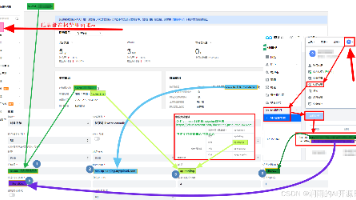
快速将智能体部署到自己的网页上,实现免登录访问介绍部分建议查看官方文档:https://www.coze.cn/open/docs/developer_guides/install_web_sdk看完后直接跳到最后,查看示例代码扣子Chat SDK 是一个 JavaScript 库,集成了扣子 OpenAPI 的对话、文件上传等能力,便于开发者高效、便捷、快速地搭建一个聊天应用。集成扣子 Chat
自媒体视频分发新方案:腾讯云"锐驰"服务器+Alist+COS组合解决传统网盘痛点。该方案提供200Mbps突发带宽和50GB对象存储,支持4K视频在线预览,无需下载。通过Docker部署Alist挂载内网COS存储,实现高速传输和免流量费。相比网盘强制登录、限速等问题,这套方案提供无门槛访问、极速体验和专业形象,成本仅相当于两顿午餐费用,是自媒体人高效分发素材的理想选择。
第一次互发 DD 报文时,双方都置位 1。常用的 LSA 共有 5 种,分别为:Router-LSA、Network-LSA、Network-summary-LSA、ASBR-summary-LSA 和 AS-External-LSA。M (More):当发送连续多个 DD 报文时,如果这是最后一个 DD 报文,则置为 0。Type:报文类型 Hello 报文、DD 报文、LSR 报文、LSU 报
OSPFArea 用于标识一个 OSPF 的区域区域是从逻辑上将设备划分为不同的组,每个组用区域号 (Area ID)来标识 OSPF 的区域 ID 是一个 32bit 的非负整数,按点分十进制的形式(与 IPV4 地址的格式一样)呈现,例如 Area0.0.0.1。为了简便起见,我们也会采用十进制的形式来表示。骨干区域(Area 0) 非骨干区域(非 Area 0)非骨干区域不允许直接相连。
本文介绍了如何在腾讯云轻量服务器上一键部署AI助手OpenClaw,并接入飞书等办公平台。推荐使用4G内存以上的海外服务器以保证AI任务流畅运行。部署过程分为选购/重装服务器、可视化配置和命令行配置三种方式,详细说明了每个步骤的操作方法。重点讲解了飞书机器人的创建和对接流程,帮助用户快速搭建专属AI助手。通过腾讯云提供的专属镜像,用户无需复杂配置即可实现24小时在线的智能助理服务。
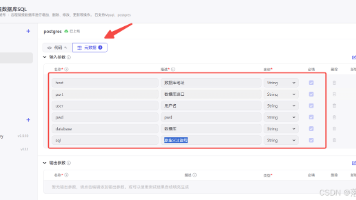
数据库节点用于对指定数据库进行常见的 SQL 操作。
在连接远程数据库进行操作时,由于需要将数据库开放至公网,必须采取严格的安全策略,如限制账号访问权限和使用高位端口等。本文介绍了如何通过输入数据库地址、端口、用户名、密码、数据库名称和SQL语句来执行查询操作,并输出执行结果和消息。支持Mysql和Postgre数据库。由于插件无法上传至扣子商店,代码已公开,用户需自行创建插件使用。本文转载自飞书文档,提供了详细的操作指南和测试方法。