- @weixin_46687145
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
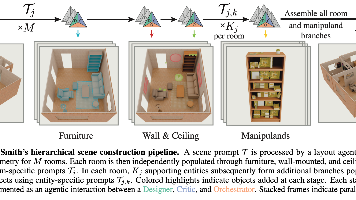
SceneSmith提出了一种智能体框架,用于根据自然语言提示自动生成仿真就绪的室内场景。该方法通过分层式智能体交互(设计者、评判者、协调者)构建场景,从建筑布局到家具摆放再到物体填充,并整合文本到3D合成与物理属性估计。实验表明,SceneSmith生成的场景物体密度是基线的3-6倍,碰撞率低于2%,96%的物体物理稳定。用户研究显示,其真实感和提示词保真度胜率分别达92%和91%。该框架可直接
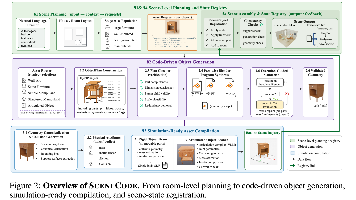
SceneCode是一种将自然语言提示编译为可执行代码的室内场景生成框架,可生成具备物理交互能力的铰接物体。其核心创新在于将场景表示为程序而非静态网格,支持按需生成全新可交互资产。框架通过房间级智能体规划布局,再调用视觉语言模型生成Blender Python代码逐部件构建物体,最终输出仿真就绪的SDF资产。实验表明,SceneCode在场景保真度、物体质量及机器人交互适用性上优于现有方法,实现了
摘要: SCENEWEAVER是一种具备自反思能力的智能体框架,专为3D室内场景合成设计,结合多元生成工具与闭环优化策略,解决现有方法在物理合理性、视觉真实感和语义匹配度上的不足。其核心是通过大语言模型驱动的规划器(Reason-Act-Reflect循环)动态调用标准化工具(如数据驱动模型、LLM、2D引导工具),迭代优化场景布局与细节。物理感知执行器确保零碰撞与零越界,多源资产库支持开放词汇需
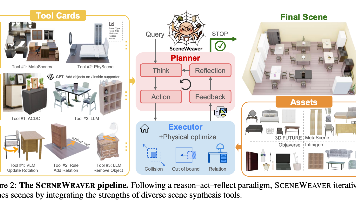
摘要: SCENEWEAVER是一种具备自反思能力的智能体框架,专为3D室内场景合成设计,结合多元生成工具与闭环优化策略,解决现有方法在物理合理性、视觉真实感和语义匹配度上的不足。其核心是通过大语言模型驱动的规划器(Reason-Act-Reflect循环)动态调用标准化工具(如数据驱动模型、LLM、2D引导工具),迭代优化场景布局与细节。物理感知执行器确保零碰撞与零越界,多源资产库支持开放词汇需
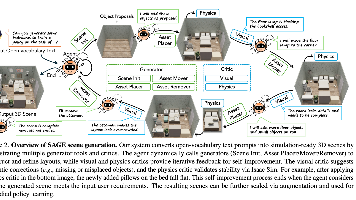
本文提出SAGE框架,通过智能体驱动的3D场景生成方法解决具身AI训练数据获取难题。SAGE将用户任务指令转化为仿真就绪的3D场景,结合生成器工具集与视觉/物理双批评器实现迭代优化,确保场景的语义合理性与物理稳定性。实验表明,基于SAGE生成数据训练的具身策略性能显著提升,并能泛化至新物体与布局。该工作为仿真驱动的具身AI规模化训练提供了有效解决方案。
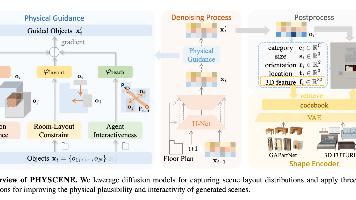
本文提出PHYSCENE,一种面向具身AI的高物理交互性3D场景生成方法。该方法基于条件扩散模型,通过创新的物理引导机制(碰撞避免、房间布局约束、智能体可达性)优化场景布局,并引入跨库形状检索嵌入可交互关节物体。实验表明,PHYSCENE生成的场景在物理合理性和交互可用性上显著优于现有方法,能有效支持具身智能体的技能学习。核心创新在于将抽象物理约束转化为可微分引导函数,实现了数据驱动与物理规则的有
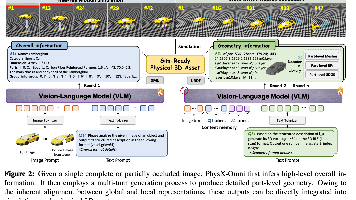
摘要 PhysX-Omni提出了一种统一框架,用于生成具有完整物理属性的仿真就绪三维资产,涵盖刚体、可变形体和关节物体。该方法创新性地设计了适配视觉语言模型的高效几何表示,可直接编码高分辨率三维结构,无需压缩或额外分割步骤。研究者构建了首个通用仿真就绪数据集PhysXVerse(含8000+资产,2000+类别)和综合评测基准PhysX-Bench,从几何、尺度、材质等六大维度评估生成质量。实验表
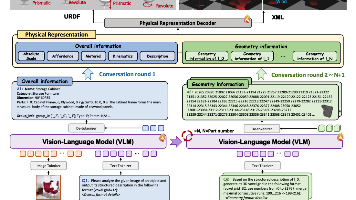
本文提出PhysX-Anything,一种从单张图像生成可直接用于仿真的物理3D资产的新方法。现有3D生成方法大多忽视物理属性和关节结构,限制了在机器人等领域的应用。为解决这一问题,作者开发了首个基于视觉语言模型(VLM)的物理3D生成框架,并提出新型3D表示方法,将几何分词数量减少193倍,使显式几何学习成为可能且无需特殊分词。此外,构建了PhysX-Mobility数据集,将物理3D资产类别扩
本文提出LatticeWorld框架,一种基于多模态大语言模型(LLM)的交互式三维世界生成方法。该框架将轻量级LLaMA-2-7B模型与虚幻引擎5结合,支持文本和视觉指令输入,自动生成包含动态智能体的高保真虚拟环境。相比传统手动建模,LatticeWorld提升生产效率90倍以上,同时保持高质量物理仿真和实时渲染能力。实验表明,该方法在场景布局精度和视觉保真度上均优于现有技术,为AI训练和内容创
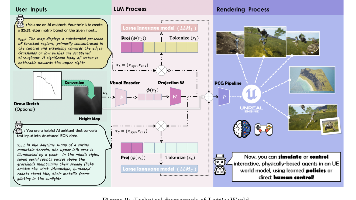
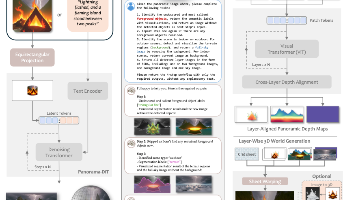
HunyuanWorld 1.0提出了一种融合2D与3D生成优势的创新框架,能够从文本或图像输入创建沉浸式、可交互的3D世界。该方法通过全景图作为世界代理实现360°场景覆盖,采用语义分层网格表示支持高效渲染与对象级交互,并兼容现有图形学流水线。实验表明,该方法在生成质量、3D一致性和交互性方面达到SOTA水平,适用于VR、游戏开发等应用场景。项目代码和演示已开源。