




- @weixin_46477226
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
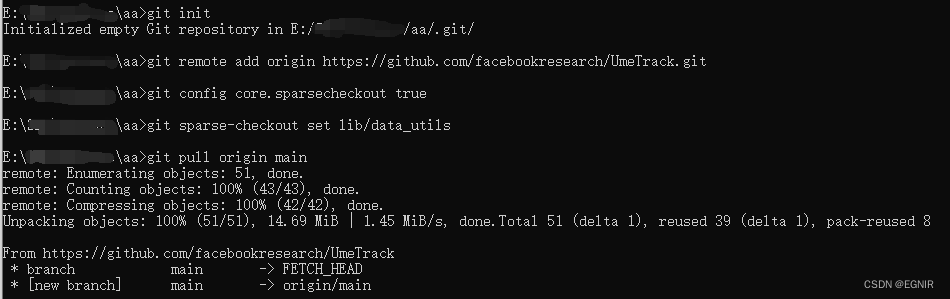
比如要下载这里的data_utils。
一、实验目的机器学习和数据挖掘算法是大数据分析处理领域的重要内容,随着数据规模的不断扩大,设计面向大数据处理的并行化机器学习和数据挖掘算法越来越有必要。通过对并行化数据挖掘算法的实现,掌握并行化处理问题的分析方法和编程思想方法,能够根据实际情况定制并行化的算法解决问题。二、实验平台1)操作系统:Linux(实验室版本为 Ubuntu17.04);2)Hadoop 版本:2.9.0;3)JDK 版本
前言:由于时间和能力的限制只完成了全国以及五个省份从1月24日到2月28日的数据统计。(疫情地图部分的数据是所有省市的)整体构架:有首页、湖北、广东、浙江、河南、山东六个网页。每个网页中包含标题、导航栏、主体的各个区域、尾部的信息来源链接。主体部分划分为图片展示、数据曲线、疫情地图、日期选择、疫情表格5个区域。另外还加了时间显示与背景音乐播放器两个配件。运用到的知识:HTML写网页的基础元素。CS
前言:由于时间和能力的限制只完成了全国以及五个省份从1月24日到2月28日的数据统计。(疫情地图部分的数据是所有省市的)整体构架:有首页、湖北、广东、浙江、河南、山东六个网页。每个网页中包含标题、导航栏、主体的各个区域、尾部的信息来源链接。主体部分划分为图片展示、数据曲线、疫情地图、日期选择、疫情表格5个区域。另外还加了时间显示与背景音乐播放器两个配件。运用到的知识:HTML写网页的基础元素。CS
1)编程实现文件的合并和去重对于两个输入文件,即文件 A 和文件 B,请编写 MapReduce 程序,对两个文件进行合并, 并剔除其中重复的内容,得到一个新的输出文件 C。import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import or
用notebook写的必做部分2.1 Plotting the Data#2.1 Plotting the Dataimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltdata=pd.read_csv('ex1data1.txt',names=['x','y'])data_x=np.array(data['x'])
根据一个已有的bvh动作文件,使用软件Blender,将其可视化成人物的动作。调整bvh文件导入所得的人体骨架的大小,使其和人物模型差不多大。使用插件(第一次用需要注册账号),将模型绑定到动作骨架上。将人物模型(fbx)和bvh文件导入Blender。从Mixamo下载一个人物的t-pose模型。从github上下载Blender插件。

用notebook写的必做部分2.1 Plotting the Data#2.1 Plotting the Dataimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltdata=pd.read_csv('ex1data1.txt',names=['x','y'])data_x=np.array(data['x'])