




- @weixin_46399686
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
字节跳动过去几年在支撑自身业务的过程中积累了很多大数据领域的引擎工具,目前也在探索将这些引擎工具的能力进行标准化、产品化的输出。组件繁多:大数据领域完成一项工作需要很多组件配合。比如分布式大数据存储及各种任务执行引擎:Flink、Spark 及各种 ETL 的 OLAP 工具和调度 ETL 的任务调度工具,还有支撑工具引擎的运行日志监控系统和项目用户权限的辅助系统等;部署复杂:这些系统的组件繁多,
大数据是企业数字化转型中,支撑企业经营和业绩增长的主要手段之一。而实时化、云原生化已经成为大数据技术发展的必然趋势。4月18日,火山引擎春季 FORCE 原动力大会在上海举办。在会上,火山引擎发布了云原生大数据实时计算平台产品——流式计算 Flink 版。脱胎于字节跳动在业界最大规模的实时计算集群实践,流式计算 Flink 产品在诸如实时 ETL、实时数仓/湖、实时机器学习、实时风控等场景中均有所

实时数据湖是现代数据架构的核心组成部分,它允许企业实时分析和查询大量数据。在这场分享中,我们将首先介绍实时数据湖目前存在的痛点,比如数据的高时效性,多样性,一致性和准确性等。然后介绍我们如何基于 Flink 和 Iceberg 构建实时数据湖,主要通过如下两部分展开:如何将数据实时入湖、如何使用 Flink 进行 OLAP 临时查询。最后介绍一下字节跳动在实时数据湖中的一些实践收益。
云原生场景下,大数据和机器学习的计算架构朝着存算分离、弹性伸缩和灵活调度的方向发展,但是各种存储服务的带宽、时延和亲缘性的能力很难去适应计算的要求。但是面对计算和客户场景的多样性,目前还没有一个业界标准的存储加速实践,很多客户在做选型的时候也面临着诸多的困惑。Ray 是近年来兴起的新一代计算引擎,相较于传统计算引擎具有更好的可编程性、异构资源支持等能力,在分布式计算尤其是机器学习领域的应用越来越广
BMQ 存算分离的架构极大提升了集群扩缩容的效率,实现了计算层和存储层的秒级扩缩容。这种架构还为 BMQ 赋予了极强的可扩展性,单集群能承担 TB/s 级别的吞吐。池化的分布式存储资源以及极致的负载均衡算法,再加上云原生化,让 BMQ 的成本相较 Kafka 降低了约 70%。此外,BMQ 还具备强大的容灾容错能力,自动的分布式存储系统故障检测及切换功能,能使 BMQ 在底层存储系统异常时快速自动
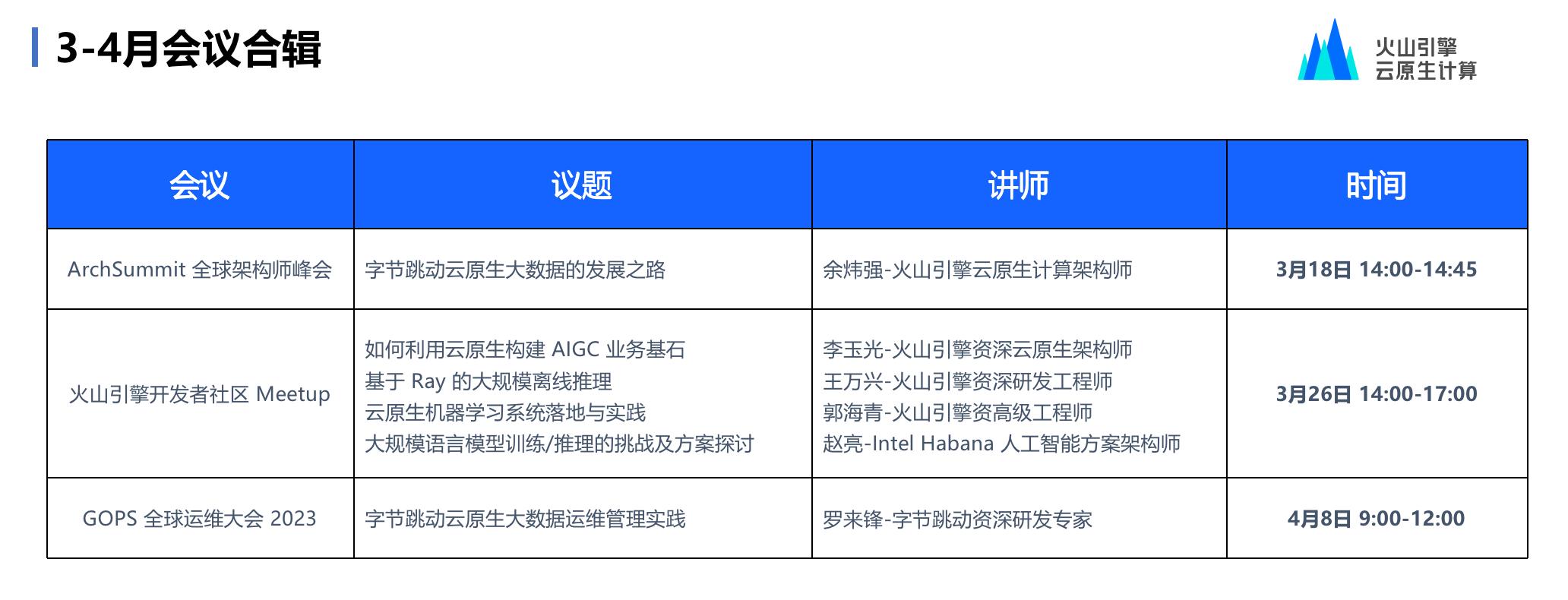
字节跳动云原生大数据的发展之路、从云原生到大数据,如何打造 AIGC 新引擎、字节跳动云原生大数据运维管理实践
字节跳动基础架构-编排调度团队的研究成果被 SoCC 2023 接收,并受邀进行现场报告。
在云原生计算时代,云存储使得海量数据能以低成本进行存储,但是这也给如何访问、管理和使用这些云上的数据提出了挑战。而 Iceberg 作为一种云原生的表格式,可以很好地应对这些挑战。本文将介绍火山引擎在云原生计算产品上使用 Iceberg 的实践,和大家分享高效查询、存储和治理 Iceberg 数据的方法。
