- @weixin_46200189
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
机器人控制总线没有绝对的好坏,只有适合不适合。如果你在做一个简单的3轴搬运机器人,成本敏感,CAN总线完全够用如果你在做人形机器人、四足机器人或者高精度工业机械臂,EtherCAT几乎是唯一的选择总线方案做对了,控制器才有发挥空间;总线方案做错了,再高级的算法也会被延迟与抖动拖回"看上去能跑、但跑不稳"的状态。希望这篇文章能帮你彻底搞懂CAN和EtherCAT总线。下次再设计机器人控制系统时,你可

✅ Qwen2-VL 多模态模型的加载与数据预处理✅ 使用 LoRA 对大模型进行轻量化微调✅ SwanLab 可视化监控训练全过程✅ 训练完成后加载 LoRA 权重做推理✅ 看懂 loss 曲线,判断是否过拟合这套流程可以直接迁移到你自己的数据集上,不管是做工业缺陷图文描述、文档VQA还是其他多模态任务,换个数据格式就能直接开训。2B 只是入门款,想效果更好可以上 7B 版本,原理完全一样,就是
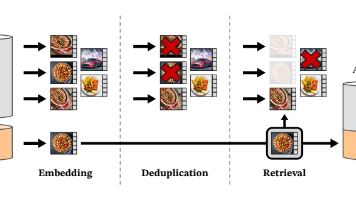
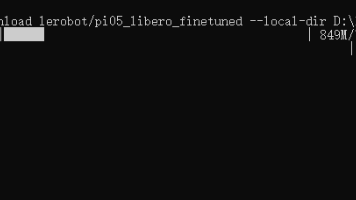
国内下载 Hugging Face 模型优先使用镜像,Win10 下载后传输到服务器,稳定性远高于服务器直接下载;EGL 相关包编译必须提前配齐系统图形依赖,并用参数确保 cmake 可被构建环境调用;LIBERO 数据集路径与 Gated 模型权限是两大隐形卡点,提前准备可大幅减少调试耗时。
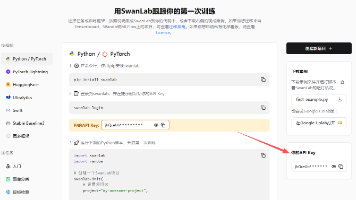
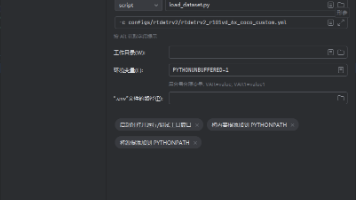
优先改运行配置:这是解决 PyCharm 自动进测试模式最直接的方法,比修改全局设置更灵活。依赖问题别忽略是 RT-DETRv2 的强依赖,安装后不仅能解决导入报错,后续模型训练的评估环节也会用到。临时方案:如果赶时间,直接在终端运行python 你的脚本.py,永远不会触发 PyCharm 的测试模式。
Gemini代表了多模态AI发展的一个重要里程碑。多模态原生架构:从一开始就联合训练文本、图像、音频和视频,实现了真正的跨模态推理超越人类专家的性能:在MMLU基准上首次超越人类专家,在大多数其他基准上也取得了最先进的结果高效的训练基础设施:使用TPU和Pathways框架,解决了大规模训练的可靠性问题负责任的部署:进行了全面的安全评估,确保模型的安全性和可靠性未来,Gemini将继续提升性能,扩

LMM(Large Multimodal Model,大语言多模态模型)通俗来说就是"能同时看懂文字和图片的AI"。它把强大的大语言模型(LLM)和视觉编码器结合起来,让AI拥有了"眼睛",能够理解视觉世界并和语言世界打通。GPT-4V是OpenAI推出的最新多模态模型,它在GPT-4的基础上增加了视觉理解能力。这篇论文通过200多个实验,从16个维度全面评估了GPT-4V的能力,发现它在很多任务

在2023年2月之前,大语言模型的世界完全被闭源巨头垄断。GPT-3、PaLM、Chinchilla这些动辄千亿参数的模型,不仅训练成本高达数千万美元,就连普通研究者想调用一下API都要排队付费。就在所有人都以为大模型会成为少数科技公司的私产时,Meta AI发布了LLaMA系列模型,彻底改变了整个行业的格局。LLaMA用70亿参数就接近了GPT-3 1750亿的性能,130亿参数直接全面超越了G
通过 Node.js + Codex CLI + CC-Switch 本地路由的组合,即可在 Windows 环境下低成本搭建 AI 编码辅助环境,无需官方订阅账号、无需全局代理,即可使用 GPT-5.5 等大模型完成代码生成、项目重构、报错排查等工作。配合 VS Code 远程开发能力,还可进一步对接服务器算法项目,大幅提升开发效率。
这里我们只关注开发调试链路,Git 先不管。这其实就是 VSCode 的远程开发模式,最常用的是。F5这样最稳,因为开发环境、运行环境、调试环境完全一致。如果能登录 Ubuntu,说明第一步没问题。安装后,VSCode 就能把“编辑器界面”放在 Windows,把“工作目录、终端、调试器”放到 Ubuntu。HostHostNameUser配好以后,以后直接连ubuntu-dev就行,不用每次敲整
如果你最近在搞具身智能或者VLA(视觉-语言-动作)模型,那你一定绕不开DINOv2。这个来自Meta AI的视觉编码器,几乎成了所有开源VLA模型的标配——OpenVLA用它,Octo用它,小米的Xiaomi-Robotics-0也用它。为什么大家都这么爱DINOv2?完全不需要任何标注,只靠看图片,就能学到和弱监督CLIP相当甚至更好的通用视觉特征。而且这些特征拿过来就能用,不需要微调,简直是