




- @weixin_45863274
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
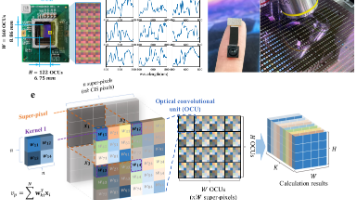
提出了一种创新的感内边缘计算方案。该工作突破了传统光计算依赖相干激光的局限,通过将卷积核权重编码到光谱滤波器中,使CMOS传感器能直接处理自然光并完成卷积运算。芯片采用超表面和颜料两种工艺制造,在12英寸晶圆上实现量产。实验表明,该方案在活体检测任务中达到100%准确率,甲状腺病理诊断准确率96.4%,同时减少96%数据传输量。
创建个人学术主页。

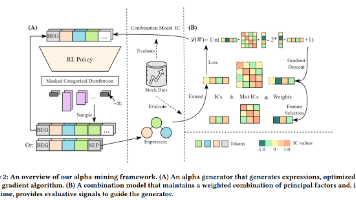
本文提出了一种基于强化学习的公式化Alpha因子自动生成框架,旨在生成具有协同效应的因子组合而非独立因子。通过将逆波兰表达式与PPO算法结合,该框架以因子组合的整体预测性能作为奖励信号。核心创新包括:1)设计快速计算因子边际贡献的定理,避免每次重新训练组合模型;2)将优化目标从单因子性能转向组合协同效应。实验表明,该方法在中国A股市场显著优于传统遗传规划和Top-K选择策略,随着因子池扩大持续提升
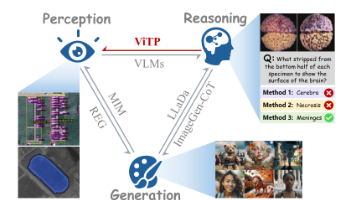
本文提出了一种创新的自上而下视觉指令预训练框架ViTP,通过利用视觉语言模型(VLM)的推理能力反向指导视觉编码器的特征学习。与传统的自监督或对比学习方法不同,ViTP将ViT嵌入多模态大模型,通过特定领域指令任务迫使ViT学习具有辨识度的深层特征。核心创新包括:1)设计视觉鲁棒性学习(VRL),随机丢弃75%视觉token以提高特征信息密度;实验表明,ViTP在遥感和医疗领域的16个数据集上均取
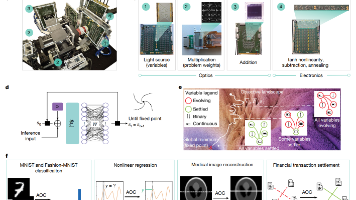
模拟光学计算机(Analog Optical Computer, AOC)的核心突破在于通用性,能够在同一套模拟硬件上加速AI和组合优化任务。采用了一种光电混合架构,通过迭代反馈回路来寻找系统的“不动点” 。光学部分利用光的并行性处理计算量最大的矩阵-向量乘法 ;模拟电子部分则负责处理非线性激活、减法、动量以及退火等操作 。系统的物理演化过程本身就是计算过程,直到信号稳定在不动点,即为最终解 。通
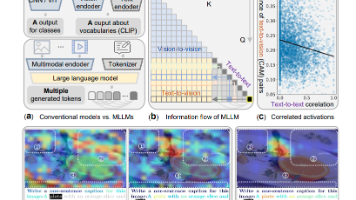
本文提出了一种新的可视化方法TAM(Token Activation Map),用于解释多模态大模型(MLLMs)的视觉注意力机制。与传统的Grad-CAM等方法不同,TAM专门针对MLLMs渐进式生成token的特性,解决了上下文干扰这一核心问题。通过估计因果推断机制,TAM能够准确分离当前token的视觉激活图,避免了先前token的干扰。同时,该方法采用排序高斯滤波器有效降低噪声。实验表明,
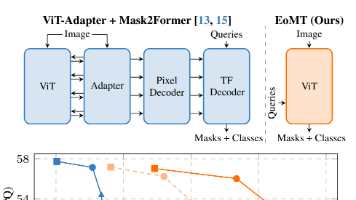
本文提出一种极简的视觉Transformer(ViT)图像分割方法EoMT,通过移除传统ViT-Adapter和Mask2Former中的复杂组件,直接在ViT编码器中注入分割查询并复用其自注意力机制完成分割任务。研究发现,大规模预训练(如DINOv2)和大模型尺寸可替代人工设计的归纳偏置,使纯ViT结构达到SOTA性能。EoMT在COCO等数据集上实现4.4倍加速(128 FPS),精度仅下降1
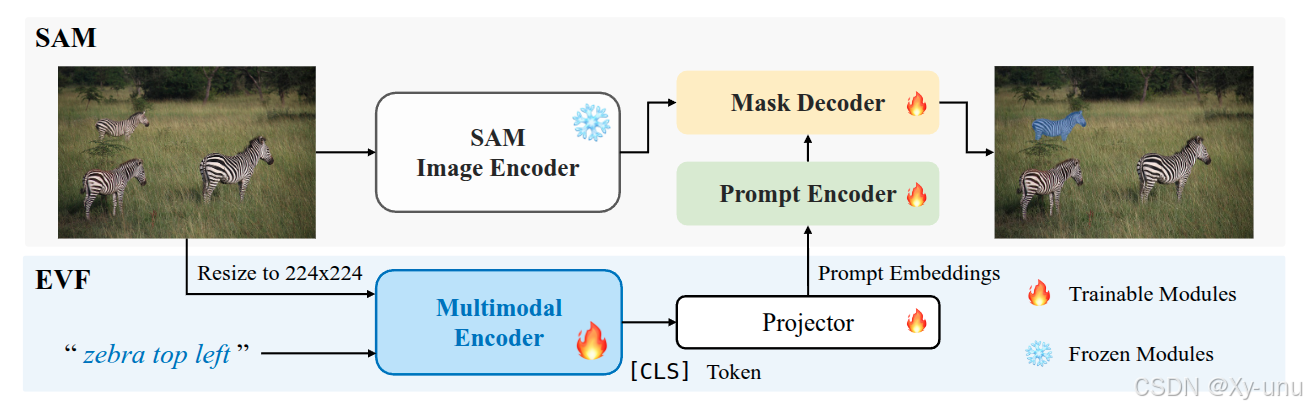
EVF-SAM 是一种简单而有效的参考分割方法,它利用多模态提示(即图像和文本),并包括一个预训练的视觉语言模型来生成参考提示和一个 SAM 进行分割。令人惊讶的是,我们观察到:(1)多模态提示和(2)早期融合的视觉语言模型(例如,BEIT-3)有利于提示 SAM 进行准确的参考分割。
本文提出了一种基于强化学习的公式化Alpha因子自动生成框架,旨在生成具有协同效应的因子组合而非独立因子。通过将逆波兰表达式与PPO算法结合,该框架以因子组合的整体预测性能作为奖励信号。核心创新包括:1)设计快速计算因子边际贡献的定理,避免每次重新训练组合模型;2)将优化目标从单因子性能转向组合协同效应。实验表明,该方法在中国A股市场显著优于传统遗传规划和Top-K选择策略,随着因子池扩大持续提升