
[ViTP]Visual Instruction Pretraining for Domain-Specific Foundation Models
本文提出了一种创新的自上而下视觉指令预训练框架ViTP,通过利用视觉语言模型(VLM)的推理能力反向指导视觉编码器的特征学习。与传统的自监督或对比学习方法不同,ViTP将ViT嵌入多模态大模型,通过特定领域指令任务迫使ViT学习具有辨识度的深层特征。核心创新包括:1)设计视觉鲁棒性学习(VRL),随机丢弃75%视觉token以提高特征信息密度;实验表明,ViTP在遥感和医疗领域的16个数据集上均取
论文基本信息 (Basic Information)
| 标题 (Title) | Visual Instruction Pretraining for Domain-Specific Foundation Models |
|---|---|
| Adress | https://arxiv.org/pdf/2507.01738 |
| Journal/Time | 2509 |
| Author | NKU,南开程明明团队 |
| Code | https://github.com/zcablii/ViTP |
| zhihu | https://zhuanlan.zhihu.com/p/1953867088889348234 |
1. 核心思想 (Core Idea)
高层理解能不能反过来教底层视觉表征做事?
之前都是用大规模预训练的模型去微调下游任务,本篇论文是用这种视觉语言模型(VLM)的推理能力去反过来训练ViT的感知能力。
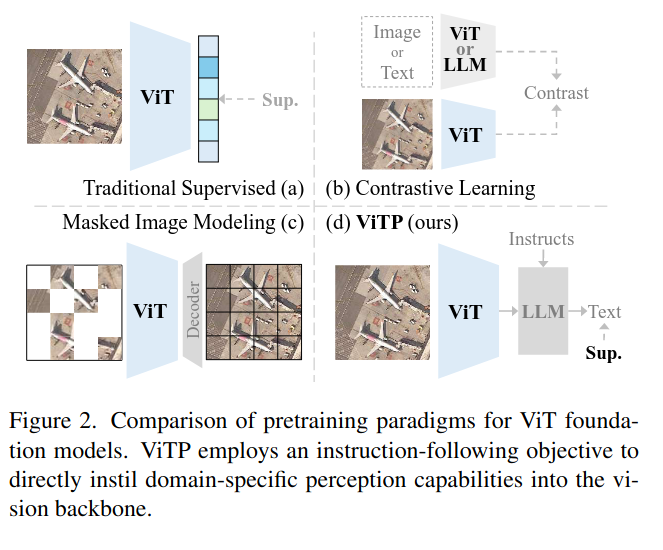
与传统的“自下而上”(bottom-up)的预训练方法(如监督学习、掩码图像建模MIM、对比学习)不同,ViTP采用了一种“自上而下”(top-down)的策略。让ViT 去学习那些具有辨识度、更深层次、更贴近下游任务的视觉特征。
 |
 |
2. 研究背景与动机 (Background and Motivation)
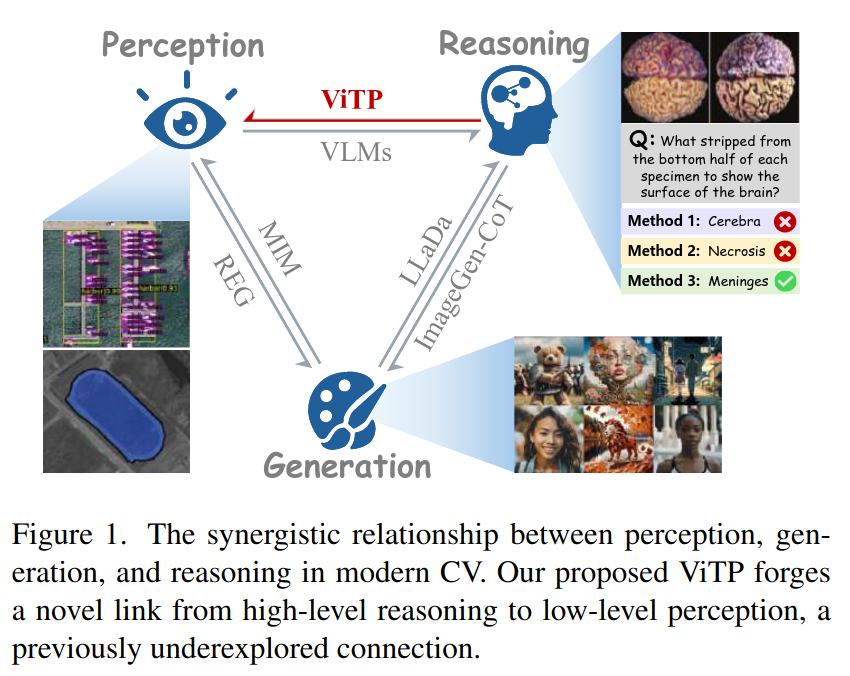
传统的计算机视觉发展遵循一个“感知-推理-生成”的闭环,大家普遍认为,强大的“感知”(比如特征提取)是实现高级“推理”(比如问答、理解)的前提。
现有的预训练方法,比如MAE(掩码自编码器)或者CLIP(对比学习)。
MAE这样的方法,本质上是在像素级别做完形填空,它关心的是“能不能重建图像”,这是一种很底层的“感知”任务。
CLIP呢,它通过图文对比,学习的是一种全局的、泛泛的对齐,对于需要精细定位和理解的下游任务(比如在遥感影像里找一架特定的小飞机,或者在医疗CT里分割一个微小的病灶),这种全局特征往往就不够用了 。
3. 方法论 (Methodology)
-
将ViT放进多模态大模型,利用下游任务,让 ViT 这个 backbone 来学习图中有效的特征。
把ViT “扔”进一个更大的视觉语言模型(VLM)里,然后给它一大堆特定领域的“指令”(比如:“请在这张遥感图里框出所有的小型船只。”),为了让LLM部分能够准确地根据指令定位到“小型船只”,ViT就必须学会提取出“小型船只”区别于其他物体的、非常有辨识度的特征,而不是一堆模糊的像素纹理。LLM通过不断地提问,逼着ViT去学习真正有用的、面向任务的视觉知识。 -
随机丢 75% 的视觉 token。
为了让ViT学得更好,设计了视觉鲁棒性学习(VRL)。就是在训练时,故意“藏”起来一大部分(比如75%)的图像特征块,只给LLM看一小部分 。LLM必须仅凭有限的线索来回答问题。这个过程会反向“压迫”ViT,让它把更丰富、更精华的信息都浓缩在每一个没被藏起来的图像特征块里,极大地提升了特征的鲁棒性和信息密度。而且,这么做还能大幅减少计算量。 -
将这个训练好的 ViT 拿出来直接接任务头。
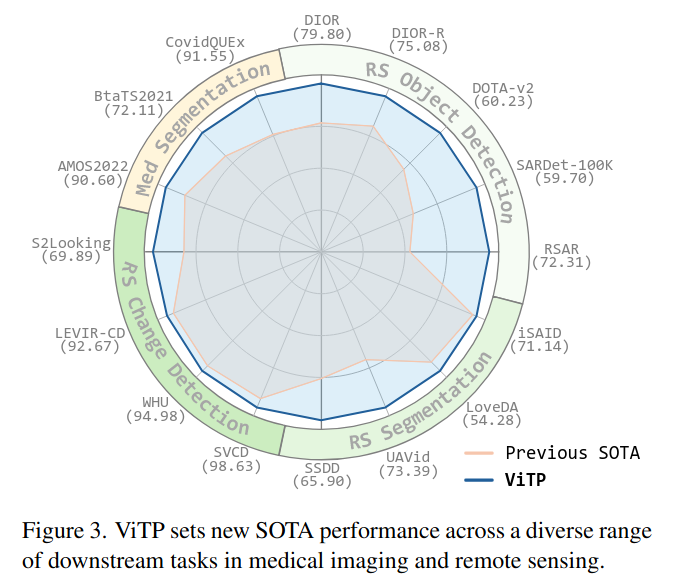
把用ViTP预训练好的ViT backbone拿出来,用到各种下游任务上,无论是在遥感领域的物体检测、分割、变化检测,还是在医疗影像的病灶分割,几乎都取得了当前最好的(SOTA)成绩 。特别是在数据量很少的情况下,我们的模型表现得比传统方法好得多 ,这说明通过高级指令学到的知识,让模型有了更强的泛化能力和先验知识。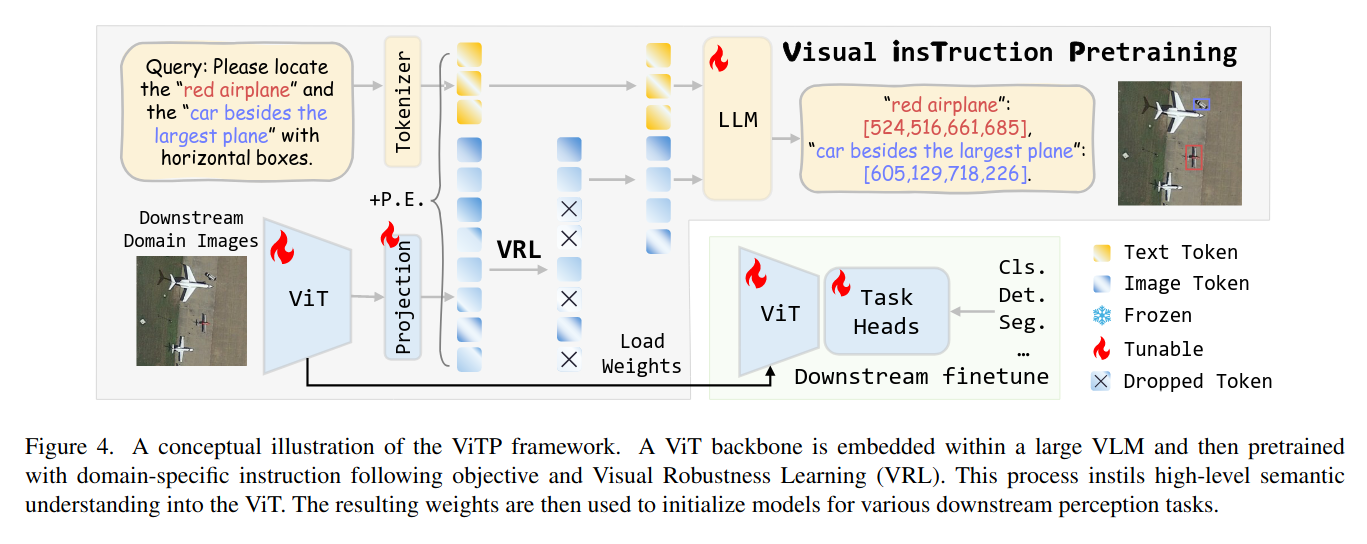
4. 实验结果 (Experimental Results)
数据集总结
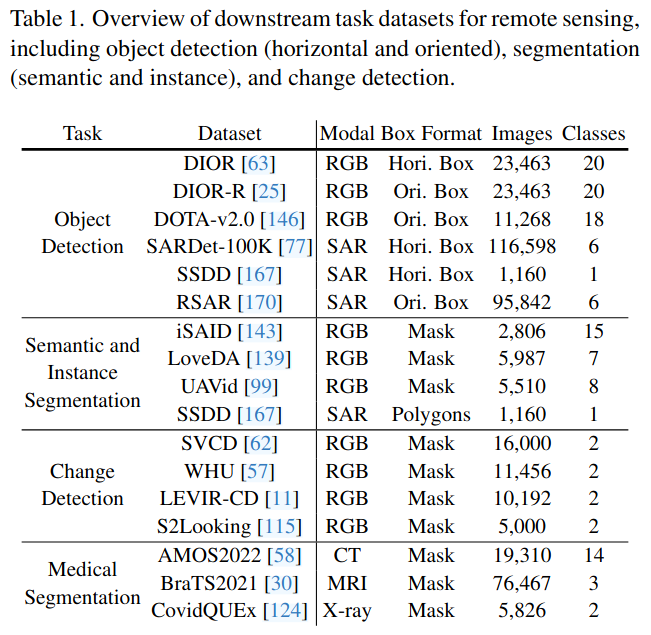 |
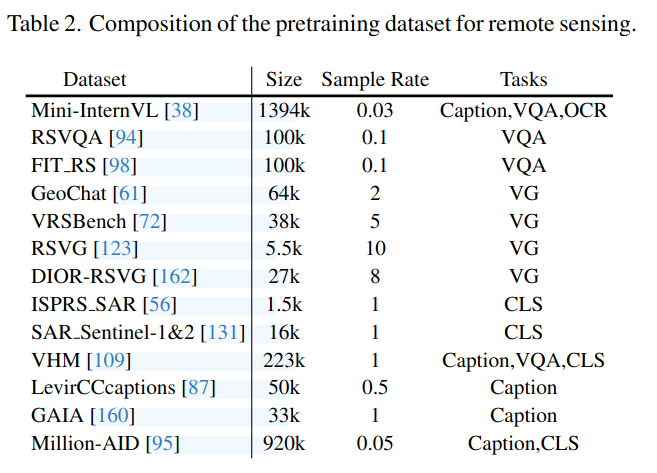 |
实验结果
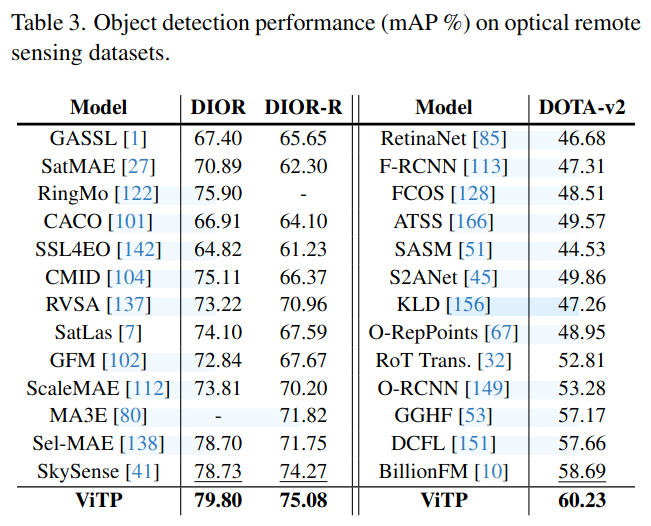 |
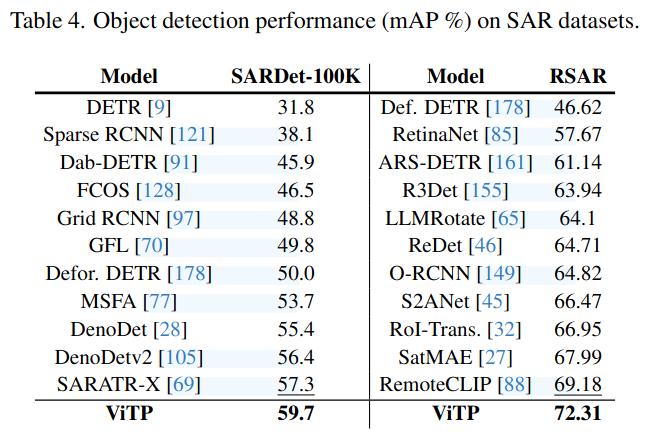 |
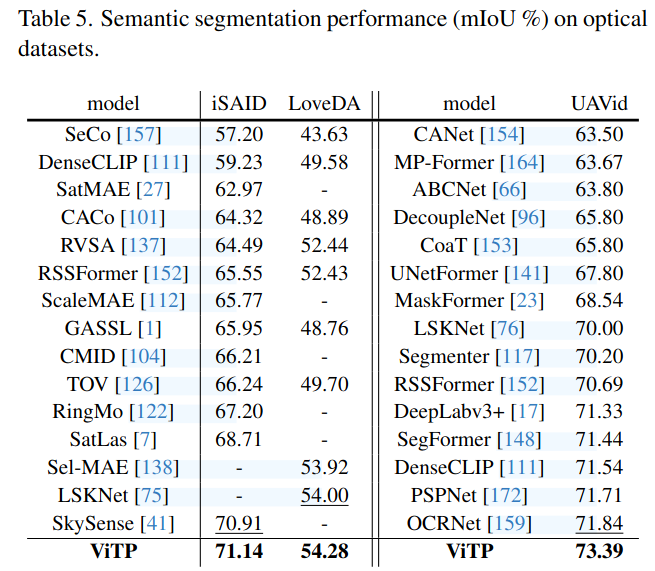 |
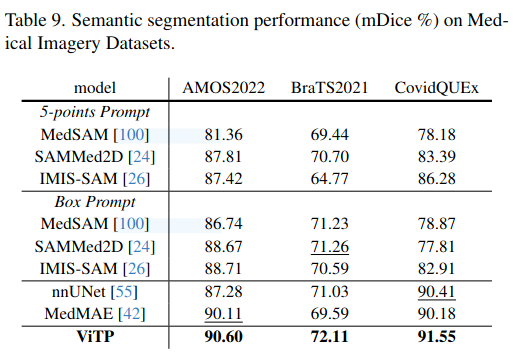 |
5. 结论与讨论 (Conclusion & Discussion)
在第5.1节的消融实验(表10)中 ,移除任何一个数据子集(如w/o Grounding, w/o SAR, w/o General data)都会导致性能显著下降 。性能的提升可能主要归功于这种组合的、信息丰富的指令数据集。
可能训练的数据也比较重要一些。
视觉鲁棒性学习(VRL)本质上,这是一种在特征层面施加的结构化Dropout。尽管实验证明其有效,但这种思想在其他领域(如BERT中的token masking)并不鲜见。
ViTP的性能是建立在一个非常强大的预训练VLM(InternVL-2.5)之上的。
6. 主要贡献总结 (Summary of Key Contributions)
提出了一种创新的“自上而下”预训练框架——视觉指令预训练(ViTP)。ViTP的核心思想是利用视觉语言模型(VLM)的推理能力来反向指导视觉编码器的特征学习。通过在一个端到端的框架中,要求视觉编码器提取能够帮助语言模型完成复杂视觉指令(如细粒度问答、视觉定位)的特征,ViTP成功地将高级语义推理的需求融入到了底层的感知学习中,为特定领域的视觉基础模型提供了高效且强大的预训练方案。
正文实验覆盖面非常广(两大领域,16个数据集,多种任务)
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)