




- @weixin_45819759
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
batch-size是深度学习模型在训练过程中一次性输入给模型的样本数量。它在训练过程中具有重要的意义,影响着训练速度、内存使用以及模型的稳定性等方面。以下是batch-size训练速度:较大的batch-size通常可以加快训练速度,因为在每次迭代中处理更多的样本。这可以充分利用高性能计算资源(如GPU)的并行计算能力。然而,过大的batch-size可能会导致内存不足而无法训练。内存使用:较大

表格中会显示显卡的一些信息,第一行是版本信息,第二行是标题栏,第三行就是具体的显卡信息了,如果有多个显卡,会有多行,每一行的信息值对应标题栏对应位置的信息。需要注意的一点是显存占用率和GPU占用率是两个不一样的东西,类似于内存和CPU,两个指标的占用率不一定是互相对应的。* Persistence-M:持续模式的状态开关,该模式耗能大,但是启动新GPU应用时比较快,这里是off。* GPU-Uti
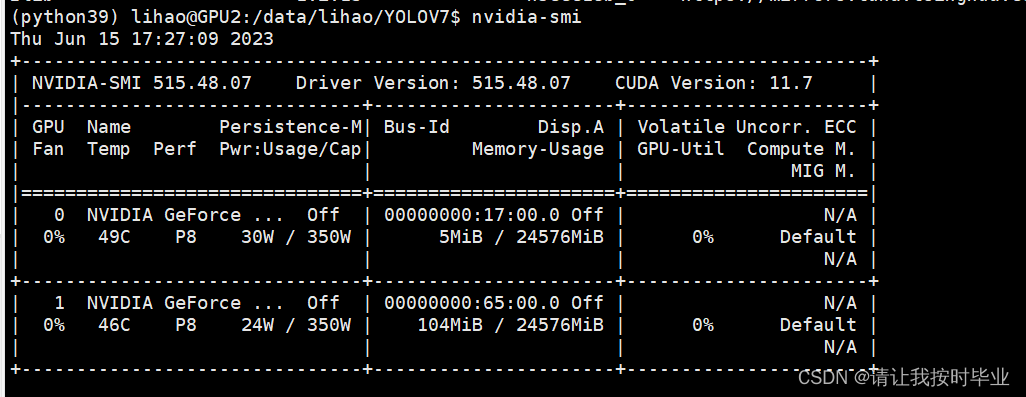
好多30系显卡呀,虽然很贵,但是为了深度学习也没有办法欸。该博客主要是为了30系显卡写的,当然不一定一定要30系列显卡,只要支持都可以这样配置。

替换为包含要修改的XML文件的文件夹的实际路径。运行代码后,它将遍历该文件夹下的所有XML文件,并将标签中的"号猪"替换为"pig"。因此想把所有xml标签里的中文统一改为英文,以下以中文“号猪”为例,统一改为“pig”。下面是一个示例代码,它遍历指定文件夹下的所有XML文件,并将标签中的"号猪"替换为"pig",然后保存修改后的XML文件。要批量修改多个XML文件中的标签,将"号猪"替换为"pi

出现以下字样即为成功。

batch-size是深度学习模型在训练过程中一次性输入给模型的样本数量。它在训练过程中具有重要的意义,影响着训练速度、内存使用以及模型的稳定性等方面。以下是batch-size训练速度:较大的batch-size通常可以加快训练速度,因为在每次迭代中处理更多的样本。这可以充分利用高性能计算资源(如GPU)的并行计算能力。然而,过大的batch-size可能会导致内存不足而无法训练。内存使用:较大
好多30系显卡呀,虽然很贵,但是为了深度学习也没有办法欸。该博客主要是为了30系显卡写的,当然不一定一定要30系列显卡,只要支持都可以这样配置。
好多30系显卡呀,虽然很贵,但是为了深度学习也没有办法欸。该博客主要是为了30系显卡写的,当然不一定一定要30系列显卡,只要支持都可以这样配置。
在安装TensorRT前,首先需要安装CUDA、CUDNN等NVIDIA的基本库,如何安装,已经老生常谈了,这里不再过多描述。关于版本的选择,楼主这里:CUDA版本,楼主这里选择的是 cuda11.0 ,具体cuda版本见,可自行下载。CUDNN版本,选择 cudnn-11.0-windows-x64-v8.2.1.32,官网下载需要先注册账号,pycuda 选择 11.4。
好多30系显卡呀,虽然很贵,但是为了深度学习也没有办法欸。该博客主要是为了30系显卡写的,当然不一定一定要30系列显卡,只要支持都可以这样配置。