- @weixin_45234741
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
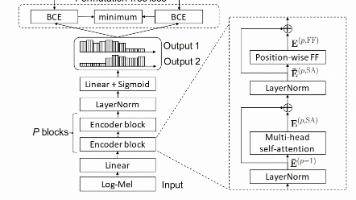
本文介绍了现代大型语言模型(如LLaMA、Qwen)在Transformer架构上的关键优化组件:RMSNorm、SwiGLU和GQA,以及它们相对于传统vanilla Transformer的改进。 RMSNorm:简化了LayerNorm,去除了减均值和偏置项,仅保留按均方根缩放,计算更高效且效果相当。 SwiGLU:在FFN中引入门控机制,通过sigmoid函数实现信息筛选,相比传统ReLU
本文探讨了现代大语言模型处理超长上下文的关键技术——旋转位置编码(RoPE)。通过对比传统学习式绝对位置编码,RoPE采用"旋转"而非"相加"的方式注入位置信息,使注意力内积仅依赖相对距离而非绝对位置。这种无参数的设计赋予RoPE天然的外推能力,解决了绝对位置编码的长度限制问题。文章从注意力机制对位置感知的需求出发,详细解析了RoPE的数学原理和实现优势,包括其置换等变特性、相对位置编码机制以及零
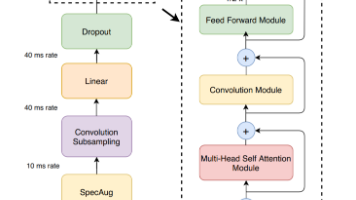
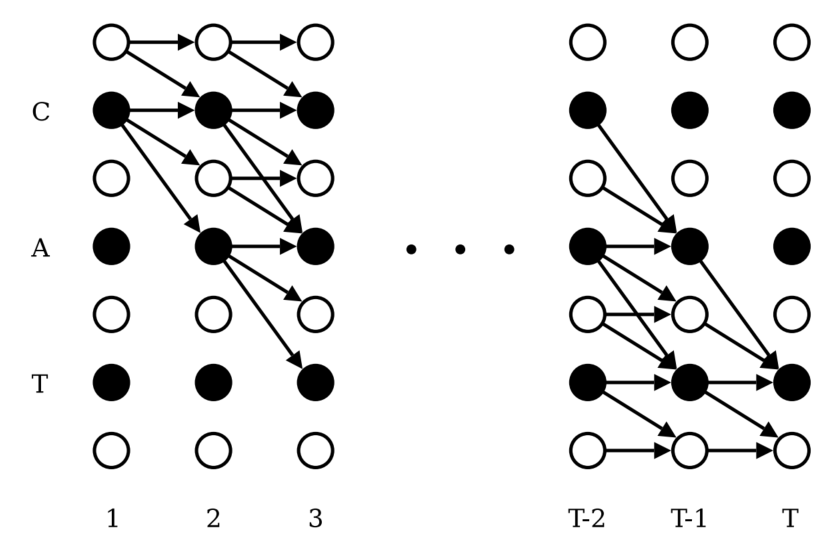
本文分析了WeNet语音识别工具包中U2++模型的训练流程。重点阐述了动态分块训练技术,该技术通过随机采样不同大小的分块(chunk)进行训练,使同一套模型参数既能支持非流式(全句)又能支持流式(有限延时)场景。文章详细说明了如何通过配置参数控制训练模式,并深入解析了add_optional_chunk_mask函数的实现逻辑,包括随机采样chunk大小、限制左右上下文范围等关键步骤。这种训练方法
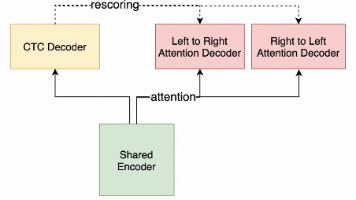
本文以nanoGPT为例,介绍了大语言模型(LLM)训练的核心过程。LLM通过next-token prediction(预测下一个词)在大量文本上训练,最小化交叉熵损失。文章展示了nanoGPT的极简实现,包括数据预处理、模型训练和文本生成。训练过程从文本流中随机采样输入-目标对(x右移一位得y),通过交叉熵损失优化模型。文章还解释了交叉熵的信息论含义,说明其作为模型性能评估指标的作用。整个过程
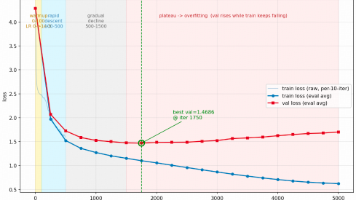
WeNet工具包采用U2++架构统一流式与非流式语音识别,通过同一模型参数支持实时低延迟和高精度两种场景。其处理流程包括:数据下载与准备、特征计算与BPE分词、词表构建、数据格式转换及模型训练。关键点包括:使用LibriSpeech数据集,计算全局CMVN统计量,训练5000个subword的BPE模型,构建包含特殊符号的字典,生成JSON格式的训练数据列表,并支持多GPU分布式训练。该方案显著降

英伟达团队在ICML 2025提出Sortformer模型,创新性地将说话人日志(SD)任务融入多说话人语音识别(ASR)系统。该方法通过引入基于首次说话时间的Sort Loss,结合传统的排列不变损失(PIL),实现了说话人顺序的稳定监督。模型采用正弦说话人核将说话人信息注入ASR编码器表示,使ASR解码器无需额外排列匹配即可生成有序文本。实验使用7180小时混合真实与模拟数据,验证了该框架在联
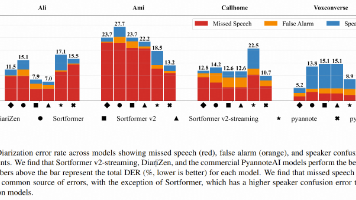
本文评测了当前主流的说话人分离模型性能,重点对比了pyannoteAI、DiariZen和Sortformer系列在不同场景下的表现。结果表明:pyannoteAI综合表现最佳(平均DER=11.2%),DiariZen是最强开源方案(DER=13.3%),而Sortformer v2在速度和流式处理上优势明显(RTF=214.3x)。研究发现当前模型的主要问题不是说话人混淆,而是语音漏检(占比约
摘要: 论文《End-to-End Neural Speaker Diarization with Self-Attention》(SA-EEND)提出将原始EEND模型中的BLSTM编码器替换为自注意力机制,以更好地建模说话人分割任务中的全局和局部信息。SA-EEND通过逐帧多标签分类和置换不变损失进行训练,实验表明其在模拟和真实数据集上均显著优于BLSTM-EEND,尤其在重叠语音场景下表现更