




- @weixin_44872675
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
生成式AI:能基于历史数据自动生成文本、代码、测试数据等“新内容”,而不仅是分类或预测。大语言模型(LLM):如GPT系列,训练自海量文本和代码,具备理解上下文、自然语言和代码的能力。上手即用(few-shot/zero-shot learning)能处理多模态数据(文本、代码、图片等)生成式AI与LLM正在深刻改变自动化测试的方式,推动测试向更智能、自适应、全面的方向发展。尽管仍有挑战,但其带来
生成式AI:能基于历史数据自动生成文本、代码、测试数据等“新内容”,而不仅是分类或预测。大语言模型(LLM):如GPT系列,训练自海量文本和代码,具备理解上下文、自然语言和代码的能力。上手即用(few-shot/zero-shot learning)能处理多模态数据(文本、代码、图片等)生成式AI与LLM正在深刻改变自动化测试的方式,推动测试向更智能、自适应、全面的方向发展。尽管仍有挑战,但其带来
生成式AI:能基于历史数据自动生成文本、代码、测试数据等“新内容”,而不仅是分类或预测。大语言模型(LLM):如GPT系列,训练自海量文本和代码,具备理解上下文、自然语言和代码的能力。上手即用(few-shot/zero-shot learning)能处理多模态数据(文本、代码、图片等)生成式AI与LLM正在深刻改变自动化测试的方式,推动测试向更智能、自适应、全面的方向发展。尽管仍有挑战,但其带来
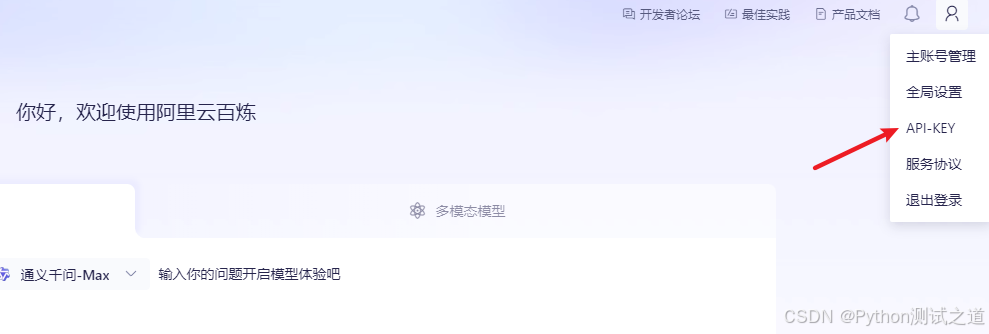
总结步骤应该是:登录/注册账号→开通服务→创建API Key→保存并安全保管。每个步骤对应相应的网页引用,确保用户能够按照指引顺利获取API密钥。
本文将介绍如何从 DOCX 文档中提取标题为“需求内容”的部分,并将其作为 DeepSeek 模型的输入,生成详细且格式化的测试用例。我们将使用 Python 编写相关脚本,并展示最终的测试用例输出格式。
搭建RAG知识库的完整源码实现(基于Python 3.8+):🛠️ 环境配置要求Python版本:3.8+安装依赖:(需创建包含以下内容的requirements.txt文件):📝 核心功能说明智能分块策略:元数据增强:检索优化:📌 常见问题处理PDF解析乱码:OCR识别失败:向量化内存不足:本实现已在实际测试项目中验证,可处理日均1000+文档的自动化入库需求。建议配合Jenkins等工具

多轮记忆靠消息序列封装,每条消息都是历史的“存档”检索工具可灵活扩展,满足复杂知识库场景LangGraph让流程管理更清晰,易于维护和扩展代码每步都可流式输出,便于调试和追踪每一个对话节点。
生成式AI:能基于历史数据自动生成文本、代码、测试数据等“新内容”,而不仅是分类或预测。大语言模型(LLM):如GPT系列,训练自海量文本和代码,具备理解上下文、自然语言和代码的能力。上手即用(few-shot/zero-shot learning)能处理多模态数据(文本、代码、图片等)生成式AI与LLM正在深刻改变自动化测试的方式,推动测试向更智能、自适应、全面的方向发展。尽管仍有挑战,但其带来
总结步骤应该是:登录/注册账号→开通服务→创建API Key→保存并安全保管。每个步骤对应相应的网页引用,确保用户能够按照指引顺利获取API密钥。
本文将介绍如何从 DOCX 文档中提取标题为“需求内容”的部分,并将其作为 DeepSeek 模型的输入,生成详细且格式化的测试用例。我们将使用 Python 编写相关脚本,并展示最终的测试用例输出格式。