




- @weixin_44778145
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Hive新增列查询为NULL问题解析 原因: 插入数据时未显式给新列赋值,默认填充NULL 动态分区或列顺序错位导致数据映射错误 Parquet/Avro等文件格式的旧数据未更新schema 解决方案: 显式指定新列值(INSERT...SELECT col1, col2, 'default') 严格匹配SELECT与表结构的列顺序 对旧数据执行INSERT OVERWRITE重建文件 分区表需单

本文介绍了 Rust 实现的高性能模型服务网关(SMG)的核心架构与关键技术。系统采用分层设计,包括负载均衡策略(7种算法)、gRPC路由管道化处理、4层可靠性机制(断路器/令牌桶/重试/健康检查)、PD分离路由、多模型网关等模块。特别优化了令牌桶的无锁实现、字符串Interning指标存储、全Rust Tokenizer等关键路径,支持Prometheus监控和OpenTelemetry链路追踪

摘要:本文探讨多线程安全初始化、配置热更新及命名空间规范三大核心主题。1)利用std::once_flag实现线程安全的单例模式,避免双重检查锁定问题;2)通过事件驱动机制实现配置热更新,结合版本校验与原子操作保证数据一致性;3)规范C++命名空间使用,强调头文件声明用extern、源文件定义的原则,并推荐匿名命名空间限制符号可见性。文末通过综合案例展示高可靠配置管理模块的设计,融合一次性初始化、

【C++进阶摘要】静态绑定、动态绑定与多态底层机制解析 本文深入探讨C++多态实现原理,重点剖析静态绑定与动态绑定的本质差异。静态绑定在编译期确定函数调用,适用于普通成员函数;动态绑定通过虚函数表(vftable)和虚指针(vptr)在运行时解析,需满足继承、虚函数、重写和指针/引用四要素。文章详解虚函数调用机制、vptr内存布局、thunk桩代码作用,以及RTTI实现原理,特别强调虚析构函数的必

Muon优化器通过正交化设计实现神经网络训练加速创新,在CIFAR-10和NanoGPT任务中刷新训练速度记录。其核心技术采用5步牛顿-舒尔茨迭代进行矩阵正交化,相比传统SVD计算效率提升10倍以上,在bfloat16精度下稳定运行。关键设计包括:(1)针对隐藏层参数的定向优化,(2)精心调优的系数组合实现快速收敛,(3)仅增加1%计算开销的轻量化实现。实际测试显示,1.5B参数模型训练时间比Ad

RLVR(可验证奖励的强化学习)是当前主流的大模型训练方法,通过预定义规则(如数学答案匹配、代码测试)提供二元奖励信号,替代传统RLHF的主观评估。其核心优势在于客观性、易设计性和防作弊能力,广泛应用于数学推理、代码生成等确定性任务。构建RLVR需关注数据准备、奖励函数设计和验证体系,但存在领域依赖性强和可能窄化模型能力的局限。未来将聚焦垂直领域优化和工业级实施方案,推动技术实际落地。

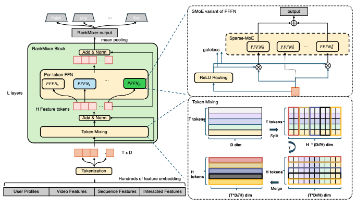
本文摘要了多种推荐系统模型的技术特点: Rank Mixer通过转置融合优化硬件效率; OneTrans采用金字塔结构压缩序列,混合参数化处理异质信息; OneSug通过前缀增强和DPO学习优化生成; EGA/DiffuASR等结合预训练与强化学习,分别解决广告竞价和冷启动问题; GPR/LC-Rec利用分层优化和语义对齐提升生成质量; DMSG通过扩散模型增强多样性。这些方法在序列建模、参数优化
RLVR(可验证奖励的强化学习)是当前主流的大模型训练方法,通过预定义规则(如数学答案匹配、代码测试)提供二元奖励信号,替代传统RLHF的主观评估。其核心优势在于客观性、易设计性和防作弊能力,广泛应用于数学推理、代码生成等确定性任务。构建RLVR需关注数据准备、奖励函数设计和验证体系,但存在领域依赖性强和可能窄化模型能力的局限。未来将聚焦垂直领域优化和工业级实施方案,推动技术实际落地。
Muon优化器通过正交化设计实现神经网络训练加速创新,在CIFAR-10和NanoGPT任务中刷新训练速度记录。其核心技术采用5步牛顿-舒尔茨迭代进行矩阵正交化,相比传统SVD计算效率提升10倍以上,在bfloat16精度下稳定运行。关键设计包括:(1)针对隐藏层参数的定向优化,(2)精心调优的系数组合实现快速收敛,(3)仅增加1%计算开销的轻量化实现。实际测试显示,1.5B参数模型训练时间比Ad
近年来,研究者提出了多种混合推理方法,在思考(CoT)和非思考模式间实现智能切换。
