




- @weixin_44585839
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2.数据取值与选择2.1 Series数据选择方法2.1.1 将Series看作字典利用键值对索引利用字典的表达式检测索引和值2.1.2 将Series看作一维数组可以利用索引-显式、隐式,掩码进行索引2.1.3 索引器 locilocixloc:取值和切片都是显式的iloc:取值和切片都是隐式的ix:是混合形式,主要用于DataFrame2.2 DataFrame数据选择方法首先创建一个较为有意
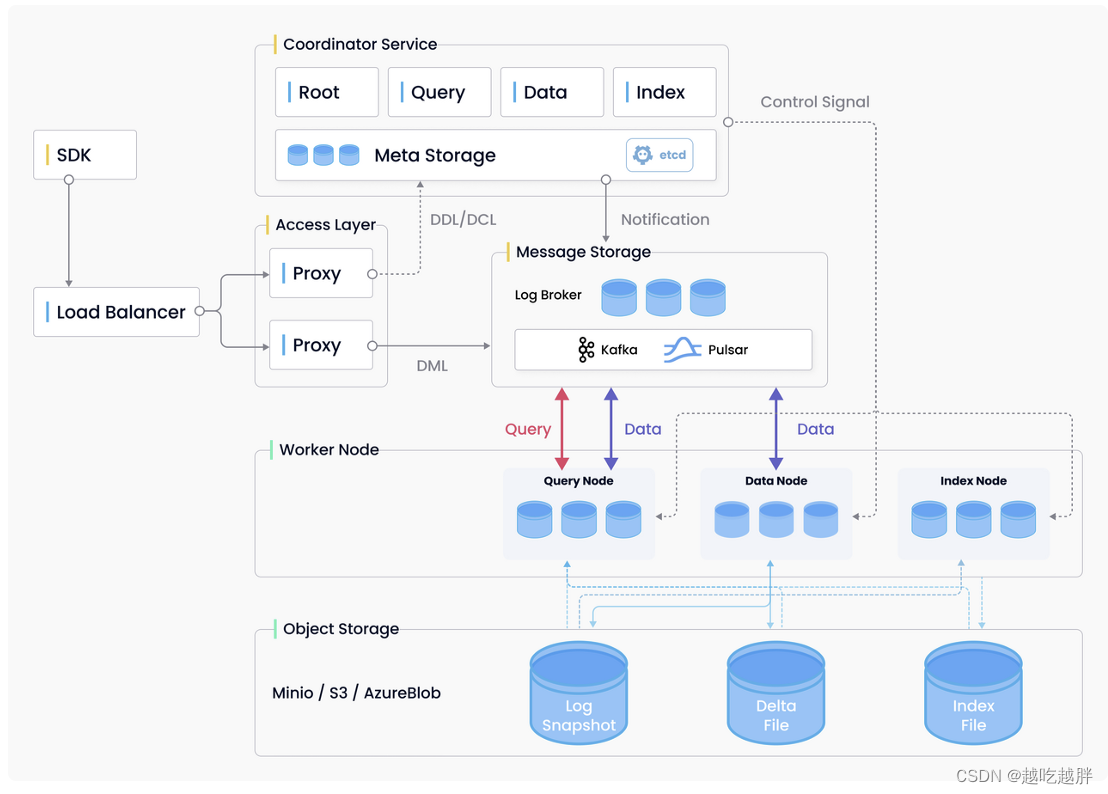
查询复杂度主要是哈希函数的计算复杂度和哈希表的遍历复杂度,一般时间复杂度达到O(N^p),其中N是数据库中向量的数量。时间复杂度主要是与K(最近邻数目)、N(向量数目)和D(向量空间维数)相关,因此时间复杂度能够低至O(log N)。预处理时间复杂度为O(N * D),其中N是数据库中向量的数量,D是向量的维度;自定义实现的 HNSW,调整到规模,并支持完整的 CRUD。搜索复杂度为O(N log
1.前言通过对好大夫网站内容的爬取,我们已经收集到好大夫的相关数据,并将其存入excel表中。之所以先存入excel表中,是因为有很多是非结构化数据,需要进行数据清理后在进行保存,excel中有很多的功能能够帮助进行数据清理,下图是获取的数据示例,一共获得20多万条数据。接下来进行数据清洗工作。2.数据清洗规则爬虫爬取的内容为:姓名_title医院科室医生主页url患者投票...
1. 缺失值处理缺失值处理主要有三个内容、四个函数:发现缺失值(isnull()notnull())、删除缺失值(dropna())、填补缺失值(fillna())首先创建一个矩阵1.1 发现缺失值发现缺失值是生成布尔类型的掩码数据,两个函数相反1.2 删除缺失值基本类型dropna(axis=0, how =‘any’,tresh) ,其中axis是按行还是按列删除、how有两种any-有缺失值
在做LDA的过程中比较比较难的问题就是主题数的确定,下面介绍困惑度、一致性这两种方法的实现。其中的一些LDA的参数需要结合自己的实际进行设定直接计算出的log_perplexity是负值,是困惑度经过对数去相反数得到的。import csvimport datetimeimport reimport pandas as pdimport numpy as npimport jiebaimport
基于阿里云hologres进行mimic数据库组装,该数据库具有强大的性能和计算速度。依次遵循一下步骤可以完成配置。
