




- @weixin_44242403
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
视频由一系列图像构成,这些图像称为帧,帧是以固定时间间隔获取的(称为帧速率,通常用帧/秒表示,例如),本文将介绍如何读取、处理和存储视频序列。如果从视频序列中提取出独立的帧,就可以对其应用各种图像处理函数,还将学习对视频序列做时序分析的算法,即比较相邻的帧并根据时间累计图像统计数据,以提取前景物体。
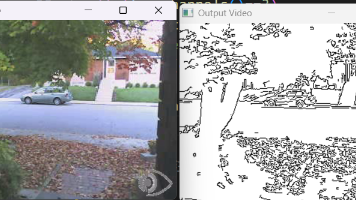
这是opencv系列的最后一节,主要学习视频序列,上一节介绍了读取、处理和存储视频的工具,本文将介绍几种跟踪图像序列中运动物体的算法。可见运动或表观运动,是物体以不同的速度在不同的方向上移动,或者是因为相机在移动(或者两者都有)。在很多应用程序中,跟踪表观运动都是极其重要的。。对于手持摄像机拍摄的视频,可以用这种方法消除抖动或减小抖动幅度,使视频更加平稳。运动估值还可用于视频编码,用以压缩视频,便

图像的边缘区域勾画出了图像含有重要的视觉信息。正因如此,边缘可应用于目标识别等领域。

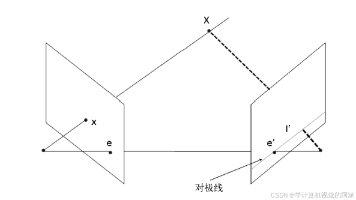
此处重点讨论在特定条件下,重建场景的三维结构和相机的三维姿态的一些应用实现。下面是完整投影公式最通用的表示方式。在上述公式中,可以了解到,真实物体转为平面之后,s系数丢失了,因而无法会的三维坐标,而s系数其实是与直接距离Z相关,实际上,如果知道。

由于此次实验是选择MindTorch进行代码迁移,建议选择交互式环境,然后镜像默认调用mindspare和MindTorch配置好的环境,如果是自己手动配置环境需要设置环境变量,否则会报错。1.包名进行替换,需要注意要偷懒直接只修改import mindtorch.torch as torch,会出现错误引用。这次迁移工作很快就结束了,总体而言未发现很大问题,后续可以尝试将更复杂的模型进行迁移。模
第一次完整地学习了transfomer,并在mindspore框架上进行了代码学习实现,代码注释流程很清晰,尤其是逐步解析多头注意力机构的实现,能够将数学原理和代码实践结合,尤其是其中时间序列掩码get_attn_subsequent_mask 函数生成的后续掩码(subsequent mask),确保在解码阶段,模型只能关注到当前位置之前的输出,而不能“看到”未来的输出。然而,在训练过程中,通常

这是opencv系列的最后一节,主要学习视频序列,上一节介绍了读取、处理和存储视频的工具,本文将介绍几种跟踪图像序列中运动物体的算法。可见运动或表观运动,是物体以不同的速度在不同的方向上移动,或者是因为相机在移动(或者两者都有)。在很多应用程序中,跟踪表观运动都是极其重要的。。对于手持摄像机拍摄的视频,可以用这种方法消除抖动或减小抖动幅度,使视频更加平稳。运动估值还可用于视频编码,用以压缩视频,便
【代码】labelme等标注的单个数据转voc标准数据集格式。

图像通常是由数码相机拍摄的,它通过透镜投射光线成像,是三维场景在二维平面上的投影,这表明场景和它的图像之间以及同一场景的不同图像之间都有着重要的关联。投影几何学是用数学术语描述和区分成像过程的工具。下文将介绍几种多视图图像中基本的投影关系,并解释如何在计算机视觉编程中将其投入应用。光线从被摄景象发出并穿过前置孔径,被相机捕获,捕获到的光线触发相机后面的成像平面(或图像传感器)
导入依赖项的h文件。
