- @weixin_44191845
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
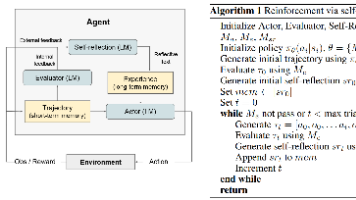
本文提出了一种名为Reflexion的框架,旨在解决大型语言模型 (LLM) 在作为智能体 (Agent) 执行任务时,难以通过传统的强化学习 (RL) 方法进行快速、低成本学习的问题。Reflexion 的本质是将“策略优化” (Policy Optimization) 从参数空间 (Parameter Space) 转移到了上下文空间 (Context Space)。
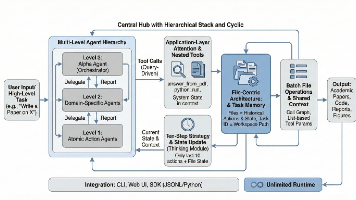
当前 LLM Agent 的核心瓶颈在于上下文长度与任务复杂度的矛盾。InfiAgent 通过将状态管理从 Prompt 中剥离,提出了一种以文件为中心 (File-Centric)的状态抽象机制,从根本上解决了长时序任务中的上下文无限增长问题。核心结论: 在 DeepResearch 基准测试中,InfiAgent 使得一个仅20B 参数的开源模型,能够在无需特定微调的情况下,达到甚至超越 GP
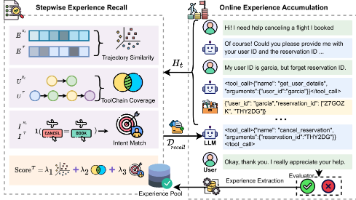
提出了一种针对复杂工具调用场景的自引导式上下文学习 (Self-Guided ICL)框架。传统的 RAG 方法通常仅依赖语义相似度来检索示例,这在多步推理和工具链规划中往往失效。SEER 的突破在于将检索维度高维化——不仅看 Query 的语义,还考量轨迹相似度工具链覆盖率和意图对齐。更进一步,它引入了在线经验累积 (Online Experience Accumulation)
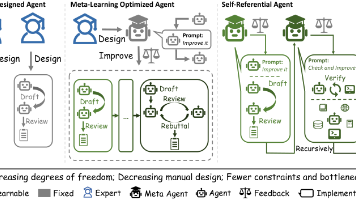
这篇论文提出了一种名为的新型智能体框架,其核心在于实现了递归式的自我改进 (Recursive Self-Improvement)。不同于以往依赖固定架构(Hand-Designed)或固定元学习算法(Meta-Learning Optimized)的智能体,Gödel Agent 受 Jürgen Schmidhuber 的 Gödel Machine 启发,具备自我指涉 (Self-Refer
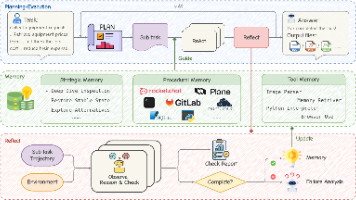
核心结论MUSE (Memory-Utilizing and Self-Evolving) 框架通过引入层级化记忆和自我反思机制,解决了 LLM 智能体在长时序任务中无法从经验中学习的问题。在 TheAgentCompany (TAC) 基准测试中,MUSE 仅使用轻量级的模型,便取得了51.78%的成功率,以20%的相对优势超越了此前由 Claude-3.5 Sonnet 驱动的 SOTA (O
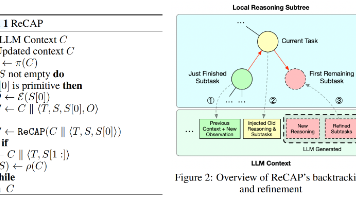
核心结论:针对长时序任务(Long-horizon tasks)中 LLM 容易迷失目标或上下文过载的问题,本文提出了一种名为 ReCAP 的递归推理与规划框架。不同于传统的扁平化思考链(CoT/ReAct)或割裂的层级规划,ReCAP 通过共享的滑动窗口上下文和**结构化的父级计划重注入(Re-injection)**机制,在保持高层意图连贯性的同时,实现了对底层执行细节的动态修正。前瞻展望:在
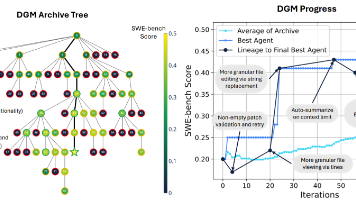
本文提出了一种名为的新型人工智能框架,旨在实现 AI 系统的完全自主进化。DGM 结合了哥德尔机 (Gödel Machine) 的理论愿景——即 AI 能够递归地重写自身代码以提升性能——与达尔文进化论的实证方法。与需要形式化证明每一次修改都有益的理论哥德尔机不同,DGM 通过在沙箱环境中进行实证评估 (empirical validation)来验证修改的有效性,并通过开放式探索 (open-
训练后的神经网络则作为学习到的启发式函数或策略,能够指导和增强后续搜索过程的效率和有效性。报告的结构将首先介绍“搜索+学习”的基本原理,然后探讨神经网络在学习搜索启发式方面的应用,接着深入分析这种范式在神经组合优化、规划和机器人技术中的应用,并重点介绍在游戏人工智能领域取得突破性进展的AlphaZero和MuZero算法。未来的研究方向包括开发更具通用性和可扩展性的搜索启发式学习方法,提高神经网络

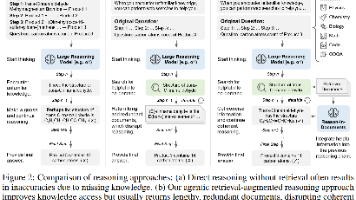
Search-o1 框架为 LRM 引入了一种智能、动态的知识获取和利用机制。通过赋予 LRM "何时搜索"、"搜索什么" 的自主权,并通过一个独立的模块来 "提炼和消化" 搜索结果,该方法有效地解决了 LRM 在面对复杂推理任务时的知识瓶颈问题。这不仅提升了模型的准确性,也增强了其推理过程的连贯性和可靠性。
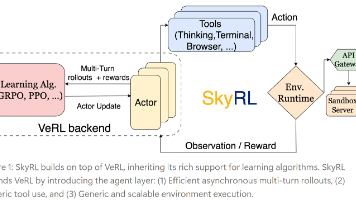
SkyRL-v0 是一个非常务实且有价值的工作。它没有把重点放在提出全新的强化学习算法上,而是通过引入**远程沙箱服务器**来解决环境扩展性问题,并通过**异步 Rollouts 和精巧的三阶段生产者-消费者流水线**来大幅提升 Rollout 效率,SkyRL 为在诸如 SWE-Bench 这样的“硬核”真实世界基准上训练 LLM 智能体铺平了道路。其核心贡献在于提供了一个**高效、可扩展的 R