




- @weixin_44175061
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
淘宝商品评论查询接口摘要(150字) 淘宝taobao.item.review接口支持通过商品ID批量获取全量评论数据,包含主评、追评、晒图、SKU规格、星级评分等核心字段。接口采用加密签名鉴权,企业权限可获取完整数据,个人权限存在脱敏。主要参数包括商品ID、分页设置、评论类型筛选等,单页最多50条,仅返回180天内数据。典型应用场景包括竞品分析、用户调研、舆情监控等。返回数据为标准JSON格式,
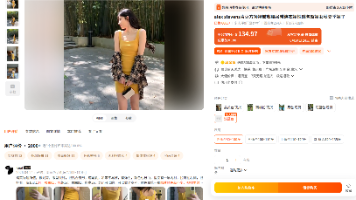
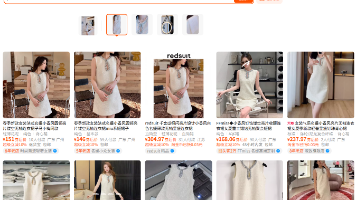
摘要:本项目基于淘宝拍立淘接口实现以图搜货功能,通过批量导入竞品主图或外网红款图片,智能匹配同款/近似款商品。项目优化了图片预处理、接口调度等环节,构建以相似度、销量和售价为核心的爆款筛选模型,有效解决接口限流和识别偏差问题。该方案支持无店铺权限调用,提供图片URL/Base64两种传参方式,返回商品ID、销量等关键数据,适用于爆款挖掘、竞品分析、货源对标等电商场景,帮助快速识别高潜力商品并优化选
在淘宝购物中,价格的变动是经常发生的。所以,如何快速掌握价格变化,抓住购买时机,是每个淘宝用户都需要考虑的问题。为了解决这个问题,出现了许多淘宝价格变动监控工具和API接口。总之,淘宝价格变动监控工具能够帮助用户更好地掌握淘宝商品价格变动情况,从而更加明智地进行购物。但是,用户在使用这些工具时也需要注意,要选择可靠的工具,并且在购物时仍需谨慎,根据自己的实际情况进行选择。一个好的淘宝价格变动监控工

天猫平台API接口是为开发电商类应用程序而设计的一套完整的、跨浏览器、跨平台的接口规范,天猫API接口是指通过编程的方式,让开发者能够通过HTTP协议直接访问天猫平台的数据,包括商品信息、店铺信息、物流信息等,从而实现天猫平台的数据开放。item_search-按关键字搜索天猫商品接口可以通过关键词搜索到商品标题,宝贝图片,优惠价,价格,销量,宝贝ID,商品风格标示ID,掌柜昵称,物流费用,店铺所

天猫平台API接口是为开发电商类应用程序而设计的一套完整的、跨浏览器、跨平台的接口规范,天猫API接口是指通过编程的方式,让开发者能够通过HTTP协议直接访问淘宝天猫平台的数据,包括商品信息、店铺信息、物流信息等,从而实现淘宝平台的数据开放。item_get-按商品ID(商品链接/淘口令)搜索淘宝天猫商品详情接口可以通过接口索到商品标题,宝贝图片,优惠价,价格,销量,宝贝ID,商品风格标示ID,掌

唯品会平台API接口是为开发电商类应用程序而设计的一套完整的、跨浏览器、跨平台的接口规范,唯品会API接口是指通过编程的方式,让开发者能够通过HTTP协议直接访问唯品会平台的数据,包括商品信息、店铺信息、物流信息等,从而实现唯品会平台的数据开放。item_search-按关键字搜索唯品会商品接口可以通过关键词搜索到商品标题,宝贝图片,优惠价,价格,销量,宝贝ID,商品风格标示ID,掌柜昵称,物流费

1688平台API接口是为开发电商类应用程序而设计的一套完整的、跨浏览器、跨平台的接口规范,1688API接口是指通过编程的方式,让开发者能够通过HTTP协议直接访问1688平台的数据,包括商品信息、店铺信息、物流信息等,从而实现1688平台的数据开放。item_search-按关键字搜索1688商品接口可以通过关键词搜索到商品标题,宝贝图片,优惠价,价格,销量,宝贝ID,商品风格标示ID,掌柜昵
京东平台API接口是为开发电商类应用程序而设计的一套完整的、跨浏览器、跨平台的接口规范,京东API接口是指通过编程的方式,让开发者能够通过HTTP协议直接访问京东平台的数据,包括商品信息、店铺信息、物流信息等,从而实现京东平台的数据开放。item_search-按关键字搜索京东商品接口可以通过关键词搜索到商品标题,宝贝图片,优惠价,价格,销量,宝贝ID,商品风格标示ID,掌柜昵称,物流费用,店铺所

当当网平台API接口是为开发电商类应用程序而设计的一套完整的、跨浏览器、跨平台的接口规范,当当网API接口是指通过编程的方式,让开发者能够通过HTTP协议直接访问当当网平台的数据,包括商品信息、店铺信息、物流信息等,从而实现当当网平台的数据开放。item_search-按关键字搜索当当网商品接口可以通过关键词搜索到商品标题,宝贝图片,优惠价,价格,销量,宝贝ID,商品风格标示ID,掌柜昵称,物流费

lazada平台API接口是为开发电商类应用程序而设计的一套完整的、跨浏览器、跨平台的接口规范,lazadaAPI接口是指通过编程的方式,让开发者能够通过HTTP协议直接访问lazada平台的数据,包括商品信息、店铺信息、物流信息等,从而实现lazada平台的数据开放。item_search-按关键字搜索lazada商品接口可以通过关键词搜索到商品标题,宝贝图片,优惠价,价格,销量,宝贝ID,商品