




- @weixin_43960413
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
一、最小距离分类在统计模式识别中,可以采用最小距离分类器,它是计算待分类的样本到各个已知类别的中心(通常是训练集中同类样本的重心)的距离,将其划分到据它最近的类别中去,这可以看做是一种最近邻的分类规则。二、最近邻分类器最近邻分类器是在最小距离分类的基础上进行拓展,将训练集中的每一个样本作为判别依据,找出和测试样例属性比较接近的所有训练样例,这些训练样例被称为最近邻,可以用来确定测试样例的类标...
注:教材为孟庆昌 路旭强版本,官方未给出课后题标准答案。以下答案均为本人自主整理与编写,如有错误之处,烦请各位斧正,QQ:1626686204目录第二章课后题第二章补充第三章课后题第三章补充第四章课后题第四章补充第五章课后题第五章补充未完待续第二章课后题1、简述Linux命令的一般格式bash 命令的一般格式是:命令名 [选项] [参数1] [参数2]2、请说明下述命令的功能:date命令:用于在
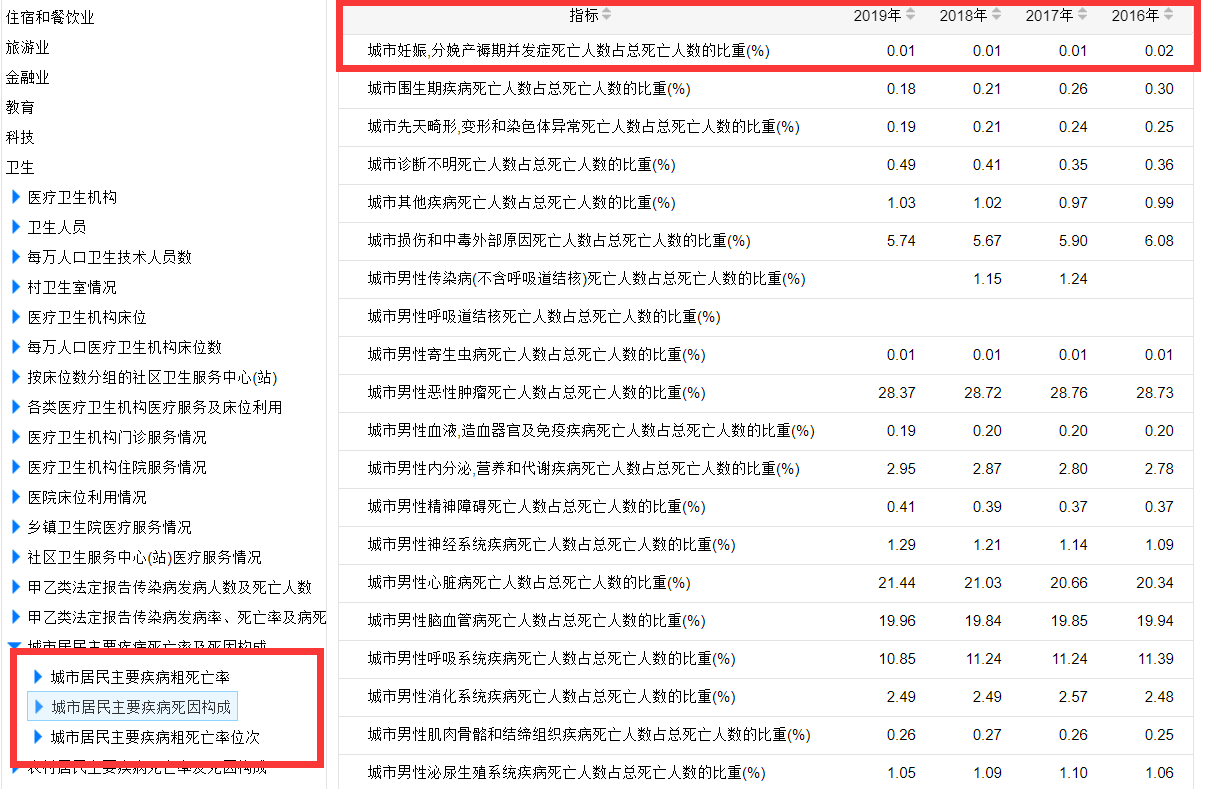
1爬取医疗行业数据并输出保存为csv格式文件目的:编写爬虫完成爬取国家统计局网站年度数据之卫生行业分类数据,具体爬取数据为:(1)城市居民主要疾病死因构成(2)农村居民主要疾病死因构成将爬取的数据进行初步的分析、整合,要求输出为csv格式文件,供Spark程序处理分析。1.1网站数据查找与分析国家数据网站(国家统计局) :https://data.stats.gov.cn/easyquery.ht
一、决策树模型决策树(decision tree)是一种常用的机器学习方法,是一种描述对实例进行分类的树形结构。举例:决策树基于“树”结构进行决策:(1)内部结点:属性(2)分支:属性值(3)p叶结点:分类结果学习过程:通过对训练样本的分析来确定“划分属性”(即内部结点所对应的属性)预测过程:将测试示例从根结点开始,沿着划分属性所构成的“判定测试序列”下行,直到叶结点学习的过程就是...