




- @weixin_43826536
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
传输层安全性协议(TLS)及其前身安全套接层(SSL)是现在的 HTTPS 协议中的一种安全协议,目的是为互联网通信提供安全及数据完整性保障。而较新版本的 python 内置的 pip 以及用于网络请求的 requests、urllib3 包也较新,并且会使用。2.通过镜像的 HTTP 源来避免 SSL 认证问题。在pip安装第三方库时,出现SSL的问题。
训练yolov8时遇到的keyError问题。

依次点击链接器,输入,附加依赖项(注意一点,要记得留意一下我们代码的运行配置,在属性页的正上方可以看到,比如我这边是Debug模式,平台是x64,因此我的附加依赖项应该是opencv_world455d.lib,而不是opencv_world455.lib,如果你选择的配置是Release,那么你的附加依赖项就应该是opencv_world455.lib)把D:\Opencv\build\x64\

大模型的文件大小与其参数量有关,通常大模型是以半精度存储的, Xb 的模型文件大概是 2X GB多一些,例如 13b 的模型文件大小大约是 27GB 左右。一般来说推理模型需要的显存约等于模型文件大小,全参训练需要的显存约为推理所需显存的三倍到四倍,正常来说,在不量化的情况下4张 v100 显卡推理 65b 的模型都会有一些吃力,无法进行训练,需要通过 LoRA 或者****QLoRA 采用低秩分

【代码】深度学习中禁用wandb方法。
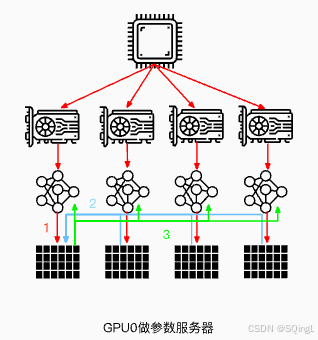
本文主要讲解了大模型分布式训练并行技术的数据并行,并以Pytorch为主线讲解了DP、DDP、FSDP三种不同的数据并行方案。单进程多线程模式,由于锁的机制导致线程间同步存在瓶颈。使用普通的All-Reduce机制,所有的卡需要将梯度同步给0号节点,并由0号节点平均梯度后反向传播,再分发给所有其他节点,意味着0号节点负载很重。由于第二点的原因,导致0号GPU通讯成本是随着GPU数量的上升而线性上升
目标检测技术在过去的十几年中,从传统的方法逐步转变成基于深度学习驱动的方法。2012年,AlexNet在ImageNet竞赛中胜利,促进了目标检测技术的发展。目标检测领域的技术发展经历了从基于卷积神经网络(CNN)的架构到基于Transformer架构的重要转变。最初的突破来自于基于CNN的模型,如R-CNN系列(包括R-CNN、Fast R-CNN和Faster R-CNN),这些模型通过引入区

训练yolov8时遇到的keyError问题。
依次点击链接器,输入,附加依赖项(注意一点,要记得留意一下我们代码的运行配置,在属性页的正上方可以看到,比如我这边是Debug模式,平台是x64,因此我的附加依赖项应该是opencv_world455d.lib,而不是opencv_world455.lib,如果你选择的配置是Release,那么你的附加依赖项就应该是opencv_world455.lib)把D:\Opencv\build\x64\
【代码】深度学习中禁用wandb方法。