




- @weixin_43592742
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
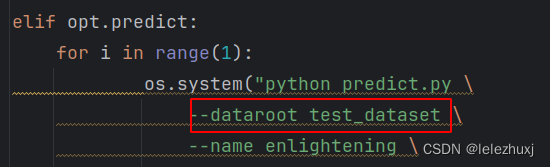
更改为 final_dataset,然后在自己根目录下(其实就是文件夹EnlightenGAN中)创建一个文件夹 final_dataset,然后把数据trainA和trainB放入到里面,就是文中提到的real_A和real_B。(具体数据和模型,原作者github下有链接)在根目录下建一个model文件夹,把vgg的模型放到里面就很好了。(2)script.py文件中将–gpu_ids 0,1
网上有人说用查看有无cpuonly的方法,试过不管用,具体参见链接[https://blog.csdn.net/HuangJM3/article/details/123685177](https://blog.csdn.net/HuangJM3/article/details/123685177)网上完整步骤的安装贴已经有不少,说下重点解决的,直接使用官网指令安装pytorch11.3发现安装的是

在安装Anaconda之前需要先安装ros(防止跟conda冲突,先装ros)。提前安装好cuda 和cudnn。安装完conda后,输入:python也就是系统默认python版本为anaconda下的python,使用指令查询发现确实是用的conda的python.使用指令由于ros 用的是系统默认的python3.8,因此如果不更改python 指向,会导致ros启动失败。使用指令查询当前环
安装gcc7.5,多版本管理
更改为 final_dataset,然后在自己根目录下(其实就是文件夹EnlightenGAN中)创建一个文件夹 final_dataset,然后把数据trainA和trainB放入到里面,就是文中提到的real_A和real_B。(具体数据和模型,原作者github下有链接)在根目录下建一个model文件夹,把vgg的模型放到里面就很好了。(2)script.py文件中将–gpu_ids 0,1