




- @weixin_43571113
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
当物体变幻时,它的外观可能转瞬即逝。例如当鸡蛋被打碎或者纸张被撕破时,他们的颜色、形状和质地都会发生巨大的变化。除了身份本身外,几乎不保留任何原始特征。然而在现有的视频分割基准中,基本上都没有注意这一重要现象。在这项工作中,我们通过收集一个新数据集(变换下的视频对象分割-VOST)来填补这一空白。该数据集由700多个在不同环境中捕获的高分辨率视频组成,这些视频平均长度为21秒,并用实例掩码进行密集

【代码】【SAM2代码解析】training部分代码详解-训练流程。
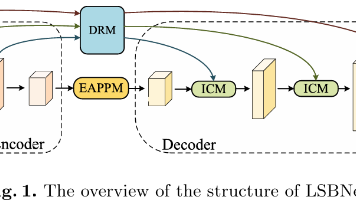
为了解决现有语义分割模型在移动设备上计算开销过大与实时推理速度之间的平衡问题,提出了一种用于实时语义分割的轻量化对称平衡网络(Lightweight Symmetrically Balanced Network,LSBNet)。
在这里,我们回顾AOT模型是如何使用Encoder和one-hot-mask模块处理输入图像和mask的。encoder处理输入图像输入数据的shape为[20,3,465,465],在这里batch_size为4.因此代表输入数据包含4个batch的数据,每个batch包含5张图像。将输入数据输给mobilenetv2网络,提取四个不同比例的中间输出特征图,并将这些特征图分成五块。那么这五块的每

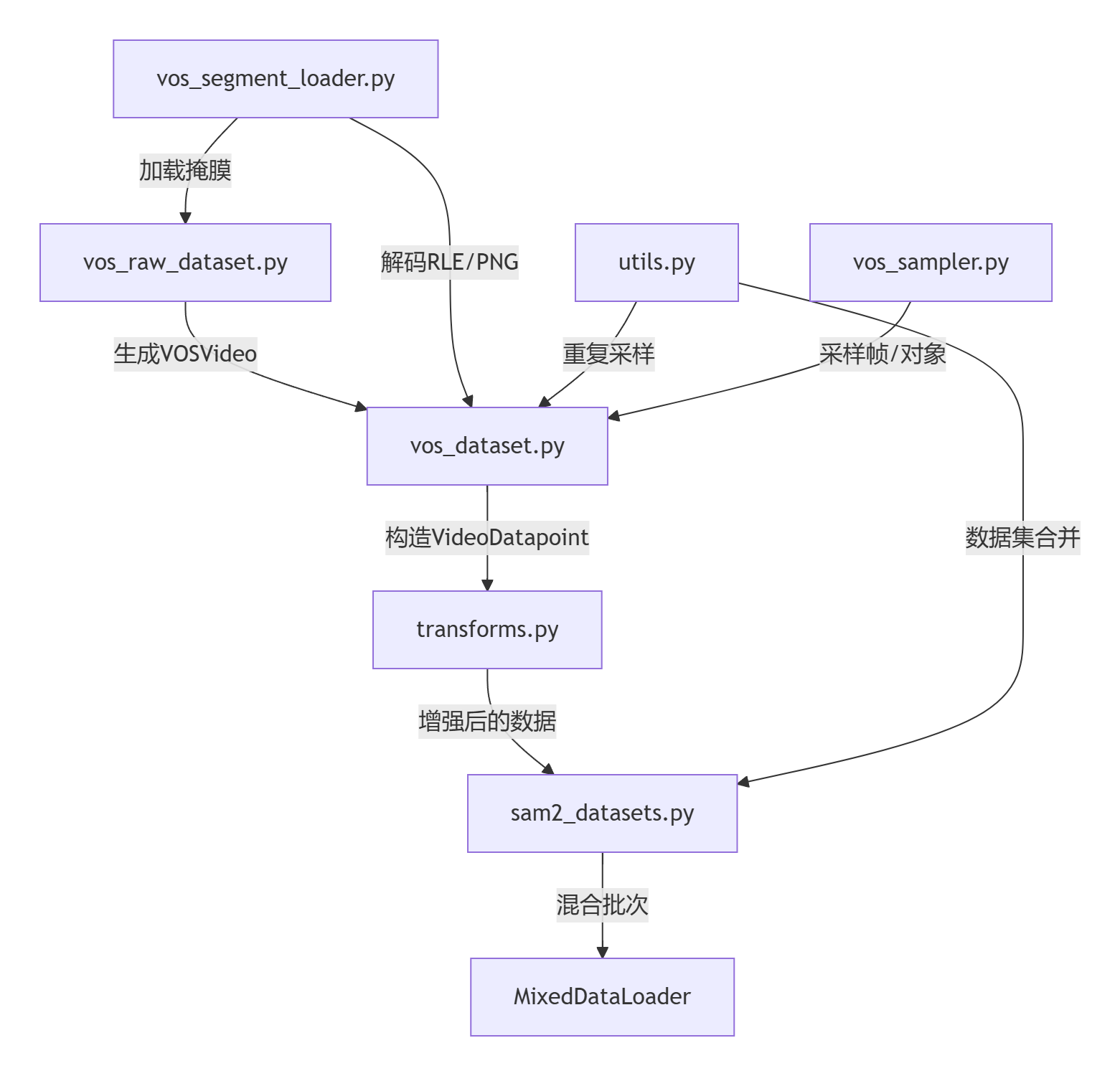
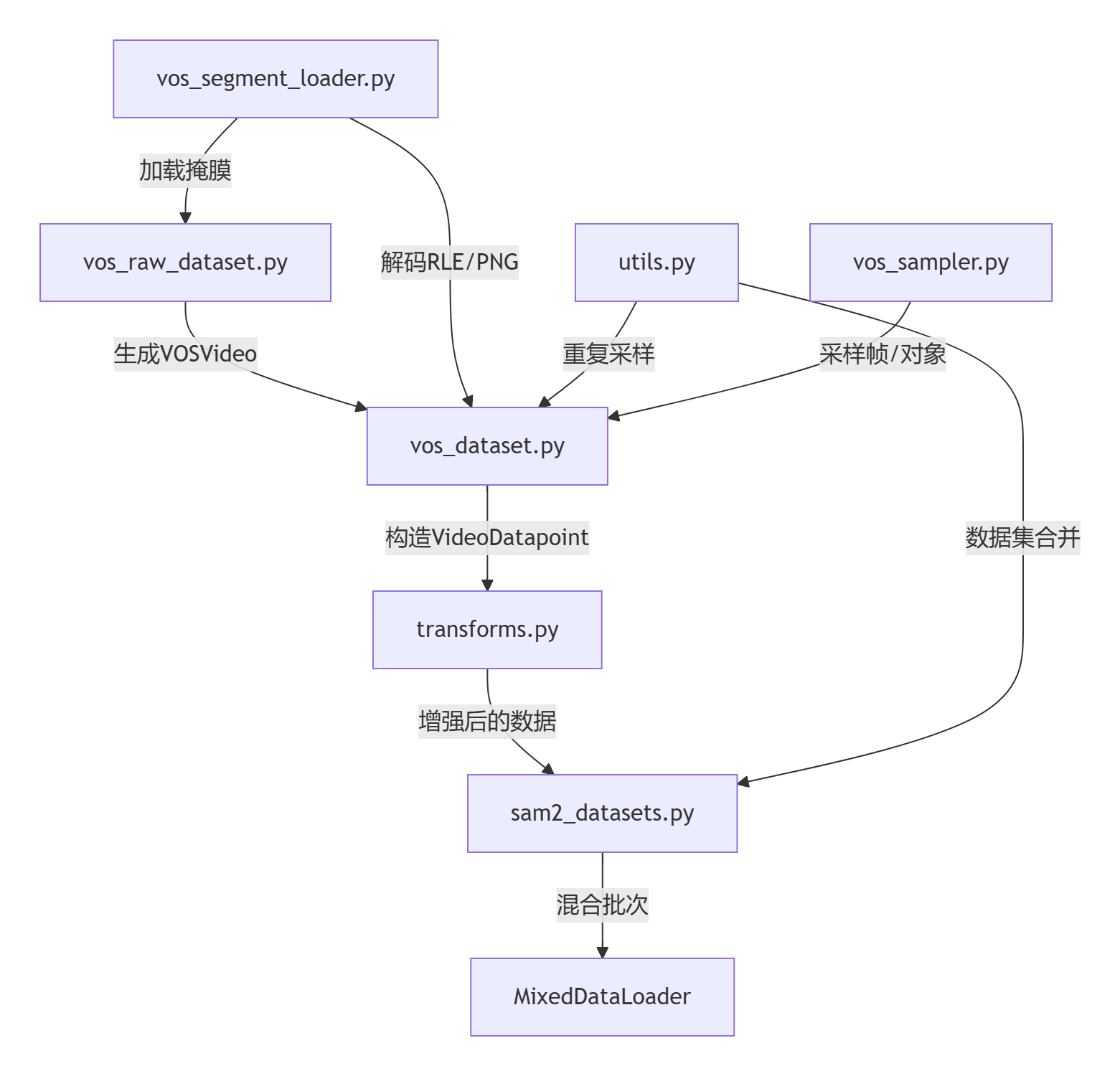
原始视频/标注…↓…[vos_segment_loader.py] → 加载掩膜…↓…[vos_raw_dataset.py] → 生成VOSVideo(元数据+帧列表)…↓…[vos_dataset.py] → 调用VOSSampler选择帧/对象 → 构造VideoDatapoint…↓…[transforms.py] → 应用翻转/缩放/马赛克等增强 → 标准化Tensor…↓…
这里的逻辑是,我们使用segment_load方法得到的mask是true.false填充的,此时直接计算sum,若和>0,则说明存在obj。使用segment_loader的load方法,得到对象mask字典,字典的key是调色盘掩码png图像中,不同对象自身对应的像素值,字典的value是将不同对象分离后得到的单对象mask掩码,掩码的值是True和False。随机采样对象ID:从可见对象ID
training folder保存了训练SAM2的相关代码,该代码允许使用者们用他们自己的数据集(图像、视频或两者一起)去微调SAM2。
问题:最近基于点击的交互式分割已经证明通过不同的推理优化策略可以达到最先进的结果。这些方法的计算量比前馈模型的消耗还要大,因为它们在推理期间运行向后的梯度,此外在流行的移动框架中不知向后传递,这使得在嵌入式设备上不住这样的方法变得复杂。方法:在本文中,我们研究了交互式分割的设计选择,并发现无需任何额外的优化方案即可获得最先进的结果。我们提出了一个简单的基于点击的交互式分割,并采用前面的步骤分割掩模

近年来,基于注意力机制的VOS方法取得了显著进展,其中AOT通过引入基于Transformer的层次传播机制,实现了从过去帧到当前帧的信息传播,并将当前帧的特征从目标无关(object-agnostic)转换为目标特定(object-specific)。视频目标分割(VOS)是视频理解中的一个基础任务,其目标是根据视频序列中第一帧提供的目标掩码,跟踪并分割整个视频中的目标。视频目标分割(VOS)是
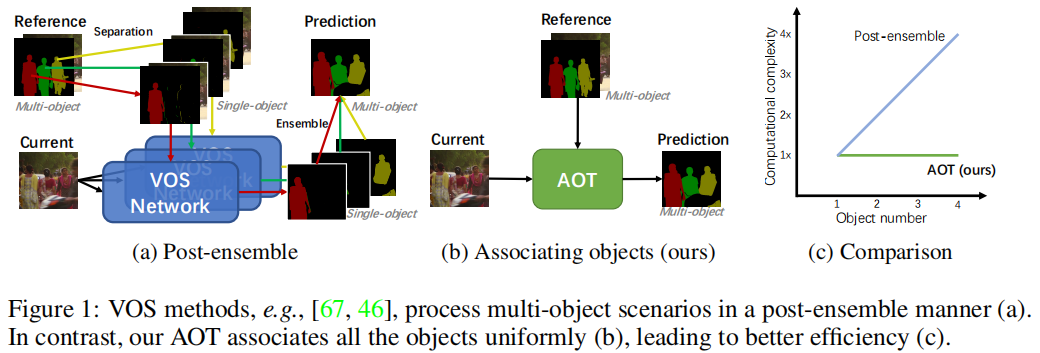
本文研究了如何在具有挑战性的多目标场景下实现更好、更高效的嵌入学习,以解决半监督视频对象分割问题。最新的方法通过学习解码具有单一正对象的特征,因此在多目标场景下必须分别匹配和分割每个目标,这会消耗多倍的计算资源。为了解决这个问题,我们提出了一种将对象与变换器关联起来的方法(AOT),以统一匹配和解码多个对象。具体来说,AOT采用了一种识别机制,将多个目标关联到同一高维嵌入空间中。因此,我们可以像处
