- @weixin_43440181
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
华为鸿蒙生态设备的数量已经超过8亿台,这一令人瞩目的成就标志着华为在操作系统领域的重要突破。随着180款设备即将获得HarmonyOS 4.2的升级。在国内市场,华为鸿蒙生态已经站稳了脚跟,市场份额稳步增长。据统计,鸿蒙系统的市场份额已经超过了16%。随着鸿蒙系统的不断优化和升级,其在国内市场的地位将进一步提升,与安卓和iOS形成三足鼎立的格局。对于程序员来说,这无疑是投身技术浪潮、拥抱未来机遇的

随着智能科技的不断进步,华为推出的鸿蒙操作系统(HarmonyOS)以其创新的分布式特性和广阔的应用前景,正吸引着众多开发者的关注和参与。那么,在这样一个背景下,鸿蒙开发的就业前景显得尤为引人注目。

最近,华为家的鸿蒙操作系统(HarmonyOS)可是火得不得了,不仅接入鸿蒙生态的设备数量噌噌往上涨,已经有超过4000款应用加入了这个大家庭,而且纯正的鸿蒙系统(非安卓兼容版)也开始崭露头角,这就意味着懂鸿蒙开发的大神们越来越抢手!想学鸿蒙开发?那就得先摸清鸿蒙的“语言”——ArkTS。它是鸿蒙专有的编程语言,学好它就像找到了进入鸿蒙世界大门的钥匙。别担心,咱有一份详细的鸿蒙学习路线图,一步一步

鸿蒙操作系统(HarmonyOS)是由中国的华为公司自主研发的操作系统,旨在为各种类型的设备提供统一和协同的操作体验。随着鸿蒙操作系统的不断成熟和发展,越来越多的行业和领域开始关注并采用这一系统,以实现更高效、更智能的设备互联和数据管理。在这样的背景下,"以千行百业加速鸿蒙化"成为了一个重要的发展趋势。那么,对于开发者来说,是否有必要学习鸿蒙开发呢?本文将从几个方面进行探讨。

本文详细介绍了如何使用LangGraph构建多智能体系统来解决单Agent处理复杂任务时的局限性。文章分析了单Agent的三大痛点:工具选择困难、上下文过载和角色迷失,展示了多智能体系统的专业化分工优势。通过Subgraphs和Network架构的实战案例,演示了如何构建能自主协作的"AI团队",包括状态共享、Agent设计和系统集成。最后提供了测试调试、生产化部署和系统扩展的最佳实践,帮助开发者
本文详细介绍了大模型智能体系统的7种核心工作流模式,包括提示词链式调用、并行化、路由、编排者-工作者模式、评估者-优化器模式以及智能体实现。通过LangGraph框架的Graph API和Functional API两种方式,提供了完整的代码示例和实现细节,帮助开发者构建高效的大模型应用系统。

MCP Client发起工具调用的实体,也就是 Dify 工作流或 Agent。它通过 Dify 平台提供的标准化接口(工具节点)来请求服务。MCP Server / Host提供实际服务的端点。在这个例子中,就是模拟 API 服务器 上的各个API (/api/pump/status, /api/cmms/pump/history 等)。这个服务器理解工具调用背后转换成的 HTTP 请求并返回数

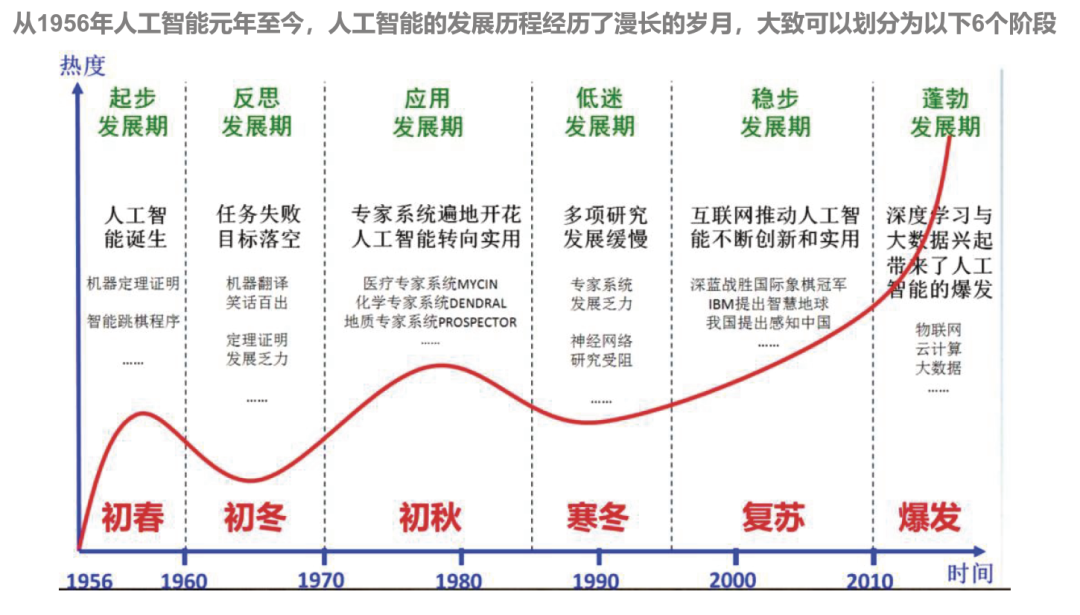
从概念提出到技术突破,人工智能的发展历程体现了人类探索智能奥秘的不懈努力。大模型时代的到来,标志着人工智能进入了新的发展阶段。这些强大的工具正在改变我们的生活方式,并为社会发展带来深远影响。展望未来,随着计算能力的持续提升和算法的不断优化,大模型将在更多领域展现出其独特价值。但同时我们也需要保持清醒认识,在技术创新的同时注重伦理规范,确保人工智能技术造福人类社会。如何学习AI大模型?最先掌握AI的
学习训练大模型需要深度学习知识、计算资源、实践经验和一定的方法。以下是学习训练大模型的一般步骤

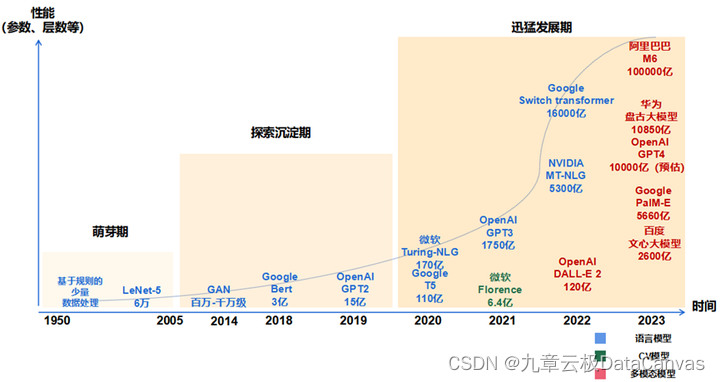
大模型是指具有大规模参数和复杂计算结构的机器学习模型。本文从大模型的基本概念出发,对大模型领域容易混淆的相关概念进行区分,并就大模型的发展历程、特点和分类、泛化与微调进行了详细解读,供大家在了解大模型基本知识的过程中起到一定参考作用。