
大模型参数全解析:数字背后的AI智能奥秘
文章解析了大模型参数的本质、类型和学习过程。参数是模型通过海量数据训练获得的知识和规律的数字编码,包括权重参数(决定输入特征重要性)和偏置参数(提供基础值)。参数从随机初始化开始,通过前向传播、计算损失、反向传播和调整参数的循环不断优化。参数数量并非越多越好,需平衡性能、成本与部署难度,通过知识蒸馏、剪枝和量化等技术实现模型"瘦身"而不失核心能力。
文章解析了大模型参数的本质、类型和学习过程。参数是模型通过海量数据训练获得的知识和规律的数字编码,包括权重参数(决定输入特征重要性)和偏置参数(提供基础值)。参数从随机初始化开始,通过前向传播、计算损失、反向传播和调整参数的循环不断优化。参数数量并非越多越好,需平衡性能、成本与部署难度,通过知识蒸馏、剪枝和量化等技术实现模型"瘦身"而不失核心能力。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
现在的大模型圈简直 “卷上天”,
卷参数,卷数据、卷算力、卷应用场景。

比如,GPT-4有1.76万亿参数,
DeepSeek-R1有6710 亿参数。
这些比手机号还长的数字代表着什么?
参数是什么意思?
为什么模型要堆成 “参数巨无霸”?
真的是 “参数越多,智慧越高” 吗?
先搞明白:参数到底是啥?
Token ID 是 “把世界翻译成模型能看懂的语言”,参数则是 “模型理解这个世界的核心密码”,是模型知识与智能的核心载体。参数越多,模型理论上能学习的知识细节就越精细。
参数到底是啥呢?🤔
其实参数就是一堆数字,它们是大模型通过海量数据训练学会的知识和规律,以数字形式编码存储。
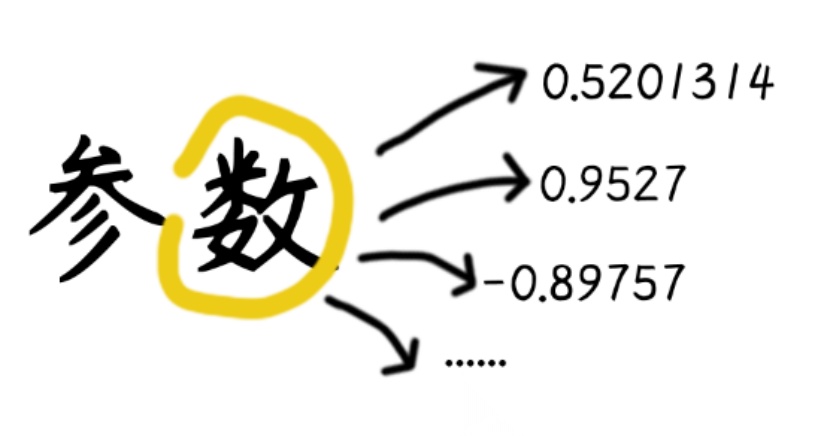
“打结记事”和“仓颉造字”等行为是人类走向智慧的关键一步,“结”和“字”是人类学习和成长中重要的“笔记”。大模型学习知识的过程也与人类似,只不过它的 “笔记” 里不是文字图画,而是密密麻麻的数字。这些数字,就是参数。比如:
- 在语言模型里,某些参数可能代表着“下雨和带伞的关联强度”;
- 在图像模型里,某些参数可能代表着“白色像素出现在猫咪胡须区域的可能性”。
这些数字从哪儿来?
就像学生反复刷题找规律,大模型会 “读” 遍互联网上的信息,把文字、图片、视频、音频等各种内容的组合规律全部翻译成数字,存在自己的 “笔记本” 里。
可以把这个笔记本想象为一个巨大的表格,每个格子里都有一个类似这样的数字。
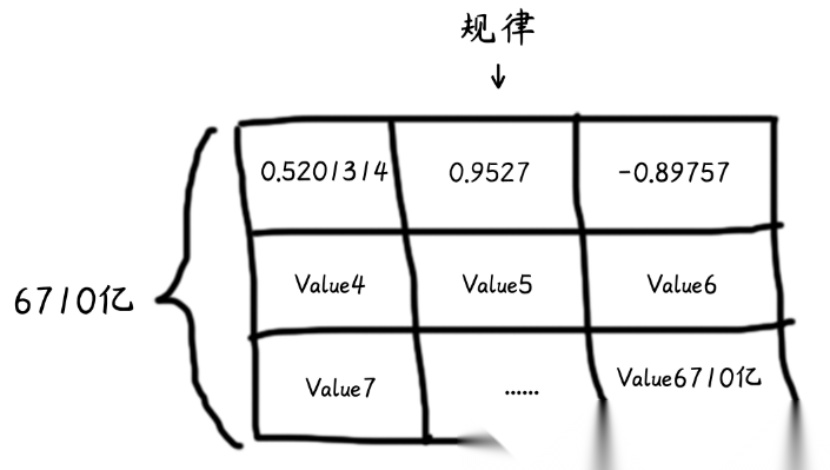
这些参数正是大模型真正的“体重担当”,通常占据大模型总体积的90%以上。大模型的“大”,本质上就是参数的“多”。
每个参数就像一个知识碎片,在协同运作中演化出推理能力,最终构建起复杂的认知网络。
划重点✍️:

参数的类型与作用
在大模型中,不同的参数类型承担着不同的功能。今天我们先来认识两个最基础也是最重要的参数类型:权重参数与偏置参数。
权重参数:模型的“放大镜”
权重参数决定了输入信息对结果的影响程度。就像考试中每道题考查的知识点不一样,对应的分值也不同。简单来说,权重越高,对应因素的 “话语权” 越大。
- 初始权重是随机的。
- 训练过程中,模型会根据预测结果与真实值的差距,自动调整权重。
- 正权重:某个特征对结果有正向推动(如 “天气晴朗” 可能增加野餐推荐概率)。
- 负权重:某个特征对结果有负向抑制(如 “降雨概率高” 会降低野餐推荐概率)。
- 权重的绝对值越大,对应因素的影响越显著。
🌰当用户询问"明天适合去野餐吗?",模型处理流程如下:
- 特征提取:解析问题中的显式(天气、温度)和隐式(季节、用户位置)特征。
- 加权求和:
-
天气晴朗(正权重 + 0.7)、温度 23℃(正权重 + 0.5)、树荫覆盖率80%(正权重 + 0.2)等正向因素提升推荐值;
-
降雨概率 10%(负权重 - 0.6)、路程20km(负权重 - 0.2)、风速5级(负权重 - 0.4)等负向因素降低推荐值。
- 综合决策:通过激活函数将加权结果映射到 0-1 区间,若输出值 > 0.6 则推荐野餐,若负向权重主导则建议改期。
- 持续优化:若用户反馈实际体验与预测不符,模型会自动调整相关因素的权重(如发现 “树荫覆盖率” 影响被低估,后续训练中增加该特征的权重)。
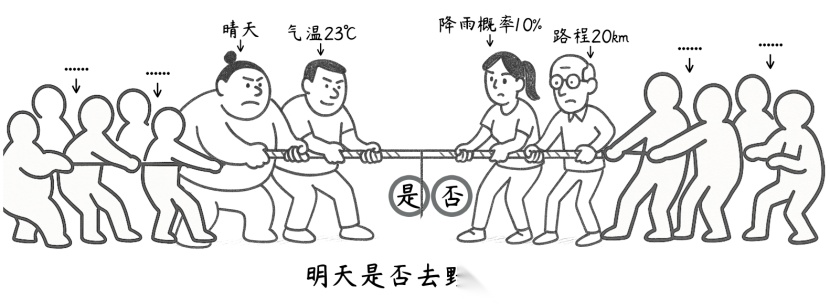
权重的本质是模型从大量数据中学习到的规律刻度,记录着 “哪些特征重要、哪些不重要”。
偏置参数:模型的“调节器”
偏置参数为大模型提供了一个基础值或默认状态,避免因输入为空或极端数据而导致不合理结果。
就像老师判作文时总有个“保底操作”:
1.偏置参数(基础分):哪怕作文跑题,老师也会给一个基础分,避免出现 0 分这种极端结果。
2.权重参数(内容得分):
- 扣题精准、文采斐然、观点新颖(输入特征越符合预期)→ 总分越高;
- 偏题、逻辑混乱、语病多(输入特征不符合预期)→ 总分越低。
总分 = 权重1×得分点1 + 权重2×得分点2 +…+ 基础分(偏置参数)

为什么偏置参数是模型的生存刚需?
如果没有偏置参数,模型只能根据输入特征的加权和做出判断。偏置允许模型在没有明确输入信号时,也能给出一个合理的结果。
- 防止零输入崩溃:假设语音助手突然收到空输入(用户误触),偏置可让其默认回复“请再说一遍?”,而非死机。
- 平衡数据偏差:如医疗数据中罕见病样本少,偏置可预设“存在患病可能”的基础值,避免模型直接忽略小概率疾病。
- 赋予模型“常识底座”:语言模型的偏置可内置“主语后接谓语”的基础语法倾向,即使输入混乱字符,也能优先生成语法结构更合理的句子。
总的来说,权重参数决定输入特征的“重要性”,偏置参数决定模型的“基础态度”。
参数是咋变聪明的?
大模型的参数并非天生具备“智慧”,它们最初只是一堆毫无意义的随机数,需要通过学习不断调整和优化,从初始的无知状态逐渐积累知识和经验。
参数的 “起点”:随机初始化
训练大模型的第一步,是给参数一个“起点” ,用数学方法(比如从正态分布、均匀分布中)生成一堆随机数,作为权重参数和偏置参数的初始值。
为什么要随机初始化呢?如果所有参数一开始全设为 0,会发生什么?
如果所有参数初始全为 0,模型会陷入“复读机模式”:
- 模型每个处理单元的计算完全相同 → 输出千篇一律的结果,无法区分不同特征,永远学不会区分猫和狗、晴天和雨天。
- 梯度更新失效 → 模型无法学习,就像全班同学交白卷,老师不知道重点教谁。

随机初始化能让模型 “起点”不同,迫使模型去探索数据中的规律。
参数的 “学习”:模型如何从 “乱猜” 到 “秒答”
随机初始化的参数毫无经验,需要通过 “海量数据 + 算法” 来优化,这个过程叫训练。大模型的参数学习就像学生备考的 “错题修炼手册”,通过 “刷题→改错→总结” 的循环,把随机的 “蒙题思路” 打磨成 “精准解题套路”。

1.学生答题(前向传播)
让模型用当前参数 “猜” 一个结果。
🌰学生拿到考试卷后(输入数据),用自己现有的解题思路(当前参数)来答题(预测结果)。
- 给模型输入一批数据(比如历史天气数据等特征)。
- 模型用当前的权重和偏置参数,对输入数据进行数学运算,输出一个预测结果(比如 “明天会下雨”)。
2.老师判卷(计算损失)
看看模型 “猜” 得有多准,算出 “错误程度”。
🌰老师批改试卷,把学生答案和标准答案对比,算出扣分多少(损失值)。
- 把模型的预测结果(如 “下雨”)和真实结果(如 “实际没下雨”)进行对比。
- 用一个损失函数计算两者的差距,得到一个数值(损失值)。损失值越小,说明预测越准;损失值越大,说明错误越严重。
3.追查错题责任(反向传播)
从 “扣分” 倒推哪些 “解题步骤” 出错,以及责任大小。
🌰复盘错题,看看是公式用错了(比如某个权重参数错误),还是计算时忘了加常数项(比如偏置参数错误),然后明确每个错误对最终答案的影响有多大。
- 从损失值出发,反向推导每一层参数对最终错误的影响程度。
- 用梯度下降等数学方法,计算每个参数需要调整的方向和幅度。梯度的正负表示参数该 “增大” 还是 “减小”,梯度的大小表示调整幅度。
4.错题本改错(调整参数)
根据错误责任,调整参数,让下次答得更准。
🌰学生根据错题分析,修改自己的解题思路(调整参数)。
- 用优化器(Optimizer)根据梯度更新参数:
-
新参数 = 原参数 - 学习率 × 梯度
-
学习率:控制调整的 “力度”,太小会学太慢,太大可能学偏。
- 重复前面的步骤,直到损失值足够小(模型 “学会” 为止)。
5.题海战术(反复训练)
一次训练过程包括前向传播、计算损失、反向传播和调整参数,这是一个最小循环单元。
大模型需要用海量数据重复这个循环成千上万次(甚至上亿次),每次都让参数向 “更正确” 的方向微调,最终从 “随机乱猜” 变成 “精准预测”。
训练数据越多、质量越高,参数调整得就越好。最终,这些参数就变成了模型的“经验值”,记录了它从数据中学到的所有规律。
总的来说,参数的学习就是用足够多的 “训练” 和足够多次的 “优化”,强迫模型 “记住” 规律。
参数真的越多越好吗?
通过上面的学习,我们知道了参数是模型的“记忆”,决定了它能记住多少知识和处理多复杂的问题。
现代大模型参数从早期的百万级发展到了如今的万亿级。
图源网络
如果把每个参数看作一块砖,那么:
- 百万级参数模型相当于一栋高楼
- 十亿级参数模型相当于一个小区
- 万亿级参数模型则相当于一座城市
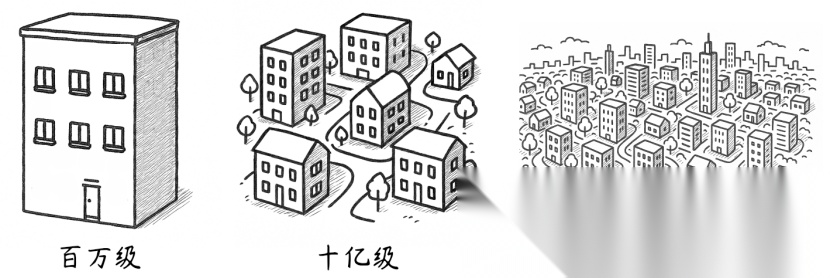
理论上来说参数越多,模型能学习到更复杂的语言模式、世界知识和逻辑推理能力。
但是参数越多≠一定聪明,参数数量≠模型能力。
参数越多,越“烧钱”
算力成本爆炸:参数越多,模型占用的存储空间就越大,计算时需要的内存和算力也越多!
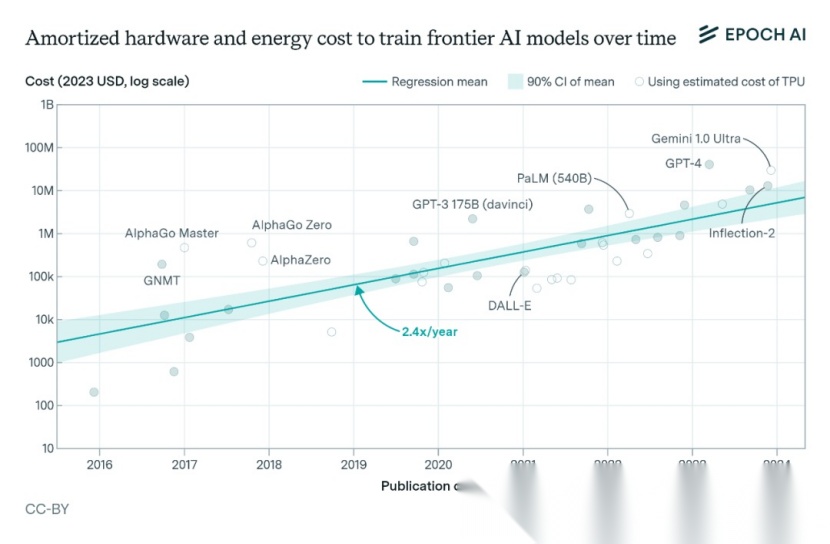
图源网络
上图表示AI模型最终训练运行的摊销硬件成本加上能源成本。空心圆圈表示使用 Google TPU 硬件预估生产成本计算的成本。
参数越多,越“低效”
边际效益递减:当参数突破千亿级后,性能提升斜率急剧放缓。参数量从10亿增加到千亿,模型性能可能提升15%;但如果从千亿增加到万亿,提升可能只有5%。
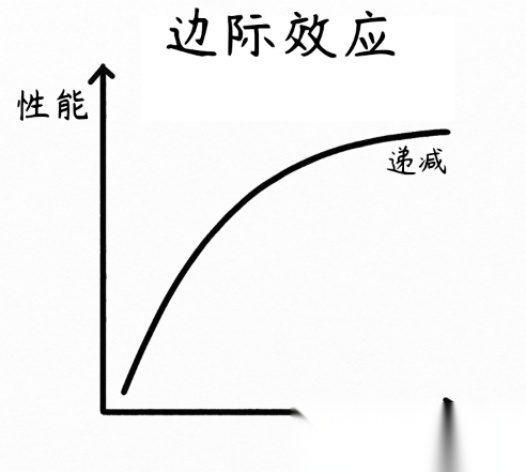
参数越多,越“贪吃”
过拟合风险:模型的参数量越高,越需要海量高质量数据 “投喂”。否则,“饿着肚子学知识”有可能会让模型“学偏”。模型会死记硬背下训练数据中的表面细节,甚至把噪声(如文本中的随机错误、图像里的无关像素)和偶然关联当作普适规律。最终,模型对见过的内容能机械模仿,却无法理解背后的逻辑,遇到新场景就会因缺乏真正的规律认知而判断失误。
就像两个学生准备同一场考试。其中一个花时间理解核心概念,练习不同的题型。另一个拿着去年的试卷,逐行记住每个答案,却不明白到底是怎么回事。新试卷题目相似,考查的是相同的知识点,但具体出题内容不同。
第一个理解概念的学生会运用相同的逻辑,以新的方式解决问题。第二个学生死记硬背的学生就要两眼一抹黑了!

总的来说,参数越多,模型就越“挑食”,需要更高质量的数据、更精细的调参、更复杂的优化算法才能发挥作用。如果数据质量差(比如充斥垃圾信息),或者算法没优化好,盲目堆参数就像往漏桶里倒水 ——投入越大,浪费越多。
所以,一个万亿参数模型若训练数据不足或结构设计不佳,可能不如精心优化的十亿参数模型。
要“Strong”不要“虚胖”
大模型参数像吹气球一样越吹越大,却可能变成“虚胖”:存储占满硬盘、计算拖慢速度、部署难如登天。这时候就需要给模型来一场健身改造,把“脂肪”(冗余参数)炼成“肌肉”(核心能力)。
- 砍掉“脂肪”:去掉重复、无效的参数(比如记住“苹果 = Apple”后,删掉记住“Apple = 苹果”的冗余参数);
- 强化“肌肉群”:保留并优化关键能力参数(如逻辑推理、语义理解的核心权重)。
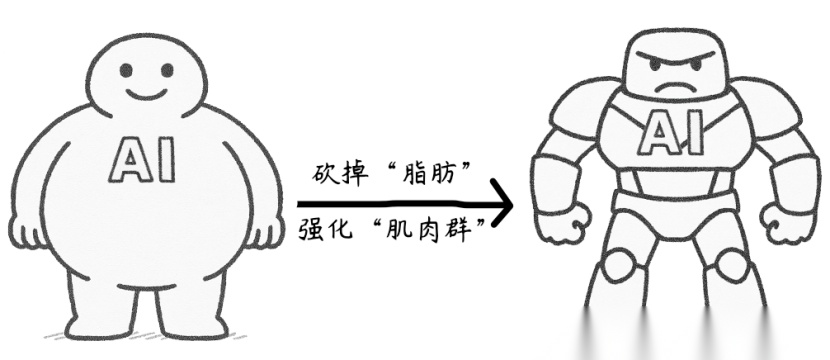
那么,模型如何成功瘦身?
知识蒸馏:健身私教“划重点”
- 私教(大模型)划重点:大模型从海量训练数据中提炼出“核心健身动作”(高频规律、关键特征);
- 学员(小模型)精准跟练:小模型只学习大模型总结的精华,不学冗长细节,少走弯路。
剪枝:减少“无用热量”
营养规划师(剪枝技术)会分析每个参数的“营养元素”(贡献度),剔除掉“无用热量”,保留“必需营养”。就像盆栽去掉枯叶,让养分集中到开花的枝条上。
- 某权重参数对预测结果仅影响 0.01% →标记为“无用热量”;
- 某偏置参数决定模型基础态度→标记为“必需营养”。
量化:“轻食”代替“大餐”
大厨(量化技术)帮助调整食谱,用更轻、更健康的食物来代替高热量大餐。
- 降低模型中的高精度浮点数(如32位浮点数 FP32)转换为低精度整数(如8位整数 INT8 或4位整数 INT4)。
- 本质是以较低的推理精度损失,达到减少模型尺寸、内存消耗和加快推理速度的目的。
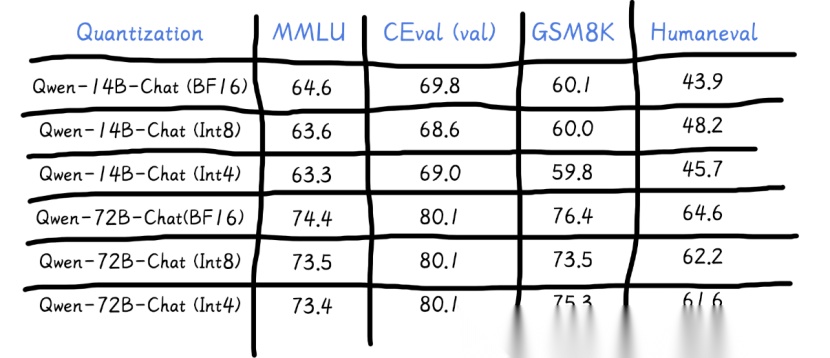
通义千问模型量化后性能对比
关键提醒:瘦身≠挨饿,避免过度压缩。
- 底线原则:保留核心能力,如医疗模型必须精准识别癌症指标,不可为压缩牺牲准确性;
- 动态调整:定期“体检”(性能测试),如发现模型准确率下降等,需“回炉优化”;
- 场景适配:通用大模型可保留一定“脂肪”(参数冗余)用于泛化;专用模型需“极致瘦身”,确保在算力受限场景下仍能保持高实时性。

未来趋势:“小而美”与“大而强”并存
- 大企业继续探索参数极限,但更关注数据质量和算法优化。
- 中小企业转向“小而精” 的模型,以轻量架构 + 深度适配实现性价比突围。
简言之,大模型的 “成人世界”,没有单纯的 “好坏”,只有利弊的 “权衡”!模型需在性能、成本、部署难度间找到平衡点,而非盲目追求参数数量。
等,需“回炉优化”;
- 场景适配:通用大模型可保留一定“脂肪”(参数冗余)用于泛化;专用模型需“极致瘦身”,确保在算力受限场景下仍能保持高实时性。
[外链图片转存中…(img-ciKrnU0A-1758538828427)]
未来趋势:“小而美”与“大而强”并存
- 大企业继续探索参数极限,但更关注数据质量和算法优化。
- 中小企业转向“小而精” 的模型,以轻量架构 + 深度适配实现性价比突围。
简言之,大模型的 “成人世界”,没有单纯的 “好坏”,只有利弊的 “权衡”!模型需在性能、成本、部署难度间找到平衡点,而非盲目追求参数数量。
最终,正如人类智慧源于860亿神经元的连接,AI的智能就藏在那一个个看似枯燥的数字参数里。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐

 17
17 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)