




- @weixin_42932602
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在 Transformer 模型中,注意力机制的计算开销很大,尤其是当序列长度和模型规模增加时。Group Query Attention (GQA) 是一种改进的注意力机制,旨在。的方式,减少了计算量,同时尽量保留了模型的表达能力。这样,既减少了计算量,又保留了不同注意力头的多样性。

Layer Norm 对每个样本在特征维度上进行归一化,计算均值和方差,并对输入进行缩放和平移。
内容概要:这份文档旨在为学习者提供吴恩达《机器学习》课程中第二周的学习内容概述,重点介绍了多个变量的线性回归问题。该课程涵盖了线性回归模型的基本原理、多元线性回归的概念以及相关的数学推导和实践案例。学习者将通过本周的学习,掌握多个变量的线性回归模型的建立和应用,以及如何利用梯度下降等算法进行模型训练和优化。适合人群:对机器学习和线性回归模型感兴趣的学习者,特别是想深入理解多元线性回归的学生或从业者
7-25 删除重复字符 (20 分)本题要求编写程序,将给定字符串去掉重复的字符后,按照字符ASCII码顺序从小到大排序后输出。输入格式:输入是一个以回车结束的非空字符串(少于80个字符)。输出格式:输出去重排序后的结果字符串。输入样例:ad2f3adjfeainzzzv输出样例:23adefijnvz思路:1:排序方法2:...
块循环矩阵是一种特殊的矩阵形式,其中矩阵是由张量。

KV Cache通过缓存中间结果,优化了Transformer模型的推理过程,提升了生成任务的效率,尤其在处理长序列时效果显著。KV Cache主要用于自注意力(Self-Attention)中,而不是交叉注意力(Cross-Attention)KV Cache 主要用于自注意力,而不是交叉注意力。在自注意力中,KV Cache 通过缓存之前 token 的 K 和 V,避免重复计算,从而提高推理
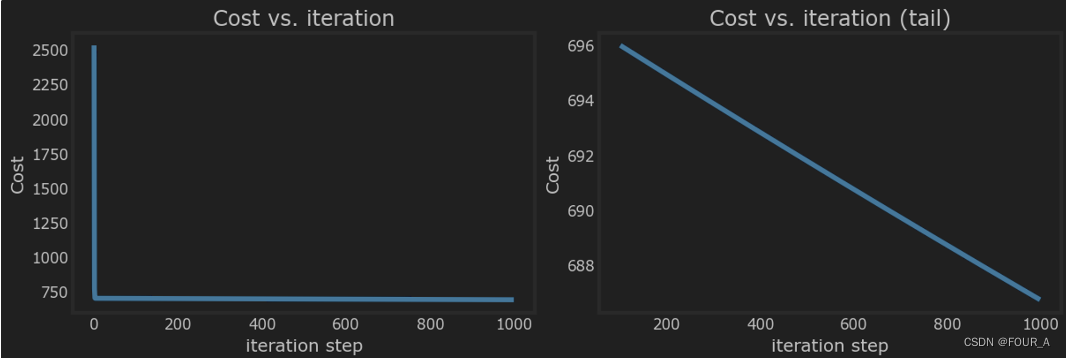
线性回归建立了一个模型,建立了特征和目标之间的关系。在上面的示例中,特征是房屋大小,目标是房屋价格。对于简单线性回归,模型有两个参数∗w∗*w*∗w∗和∗b∗*b*∗b∗,它们的值使用训练数据进行“拟合”。一旦确定了模型的参数,就可以使用模型对新的数据进行预测。成本方程提供了一个衡量预测值与训练数据匹配程度的指标。最小化成本可以提供wwwbbb的最佳值。

我们想用一个已经学会英语的模型,通过中文数据继续训练它,同时用分词器把中文句子拆成小单元,让模型更容易理解中文。

在这里,我们不会实现一个 BPE 分词器(但 Andrej Karpathy 有一个非常简洁的实现)。BPE(Byte Pair Encoding,字节对编码)是一种数据压缩算法,也被用于自然语言处理中的分词方法。它通过逐步将常见的字符或子词组合成更长的词元(tokens),从而有效地表示文本中的词汇。:首先,将所有词汇表中的单词分解为单个字符或符号。例如,单词 “hello” 会被表示为。:接下

7-25 删除重复字符 (20 分)本题要求编写程序,将给定字符串去掉重复的字符后,按照字符ASCII码顺序从小到大排序后输出。输入格式:输入是一个以回车结束的非空字符串(少于80个字符)。输出格式:输出去重排序后的结果字符串。输入样例:ad2f3adjfeainzzzv输出样例:23adefijnvz思路:1:排序方法2:...