




- @weixin_42899627
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
对于传感器采集的数据,一般都需要一次误差标定,因为传感器测量会有误差噪声,就是对传感器采集的值进行直线拟合,也就是利用最小二乘法计算一条直线使得这些点到直线的距离最小(近似解)。也就是求解直线方程y = kx + b的k和b两个参数。
核心原则:Git 配置是持久的,.git文件夹包含了项目的所有 Git 信息。只要这个文件夹存在,就不需要重新初始化。用户信息存储在电脑的 Git 配置中,除非换电脑或重装系统,否则也不需要重新设置。是否提交了敏感信息(密码、API密钥)代码是否可以编译/运行。是否提交了不必要的文件。

本文总结了Git推送代码到GitHub时常见问题的完整解决方案。主要内容包括:1)SSH密钥认证失败的解决方法(生成密钥、配置代理、添加公钥);2)远程仓库冲突的处理(删除错误配置、添加正确SSH地址);3)分支同步问题的解决(使用rebase方式合并远程更改)。文章通过失败与成功案例对比,提供了从初始化仓库到成功推送的完整流程,特别强调了SSH认证和分支同步的关键步骤。最终解决方案可确保代码顺利

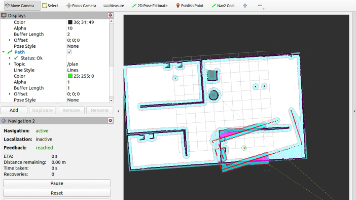
本文针对Nav2导航系统在转角、门口和目标点处出现位姿估计错误的问题,提出了两个关键解决方案:1) 修改行为树结构,在路径规划后增加路径平滑节点,通过Sequence节点将ComputePathToPose和SmoothPath操作封装在一起;2) 调整控制服务器参数,包括放宽最终对准阈值、降低角度误差惩罚强度、优化控制器输出限制等。实验表明,这些改进有效减少了机器人因大角度转弯导致的位姿估计偏差
video2imgs 函数视频转图片操作pick_imgs 函数对视频帧筛选,隔帧取样操作注意:两个代码是独立运行的,pick_imgs 的操作其实是可以合并在 video2imgs 函数里面的,这里的 pick_imgs 函数有点冗余了import cv2import numpy as npimport globimport shutilimport osdef video2imgs(vd_di
本文介绍了在Ubuntu系统下备份RDK X5镜像的完整流程。首先需要准备读卡器和SD卡(默认ext4格式),并将设备接入系统。关键步骤包括:1)创建挂载点并使用mount命令挂载SD卡;2)执行rdk-backup命令指定备份路径;3)系统自动生成以"rdk-年月日-时分.img"命名的镜像文件。操作过程中需注意SD卡的挂载位置,并确保相关依赖包已安装。备份完成后,镜像文件将

时间戳不同步:激光数据的时间戳(1764699052.365)比 TF 变换缓存中的最早数据还要早,导致 costmap 丢弃这些激光数据。实际观察到的现象:(实验中机器人一会停止,一会旋转偶尔乱走,但路径显示没变化)❌ 当前情况:激光数据被丢弃 → costmap不更新 → 障碍物检测失效。✅ 正常情况:激光数据 → 更新costmap → 障碍物检测。地图空洞:丢失的扫描数据导致地图不完整。雷
本人手机型号:SM-G7508Q手机放太久没有,一拿起来就突然要输 PIN 码,一脸懵逼电源键+音量键减+home键进入该页面(没啥卵用)解决方法:当时这个方法抱着试一试的态度,操作过程没有记录,但是我手机可以使用了,希望文章能有帮助参考链接:三星手机进入recovery模式教程(含双清教程)1.电源键+音量键加+home键(长按),进入recover界面,英文显示。(音量键进行上下选择,电源键进
本文总结了在编译nav2导航包时遇到的问题,主要包括下列参数:nav2_constrained_smoother包中prelast_dirnav_2d_utils库中valuebehavior_server中transform_toleranceinput_at_waypoint插件中timeoutnav2_smoother中transform_toleranceplanner_server中ex
1 行列式det(a)2 逆矩阵pinv(b)3 特征值与特征向量[x,y]=eig(d)x列是特征向量,y对角线元素是特征值4 基础解系B1=null(c,'r')B1列为基础解系5 极大线性无关组I=rref(e)I为矩阵最简式,显然可以看出第1、2、3列为极大线性无关组...