- @weixin_42782643
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
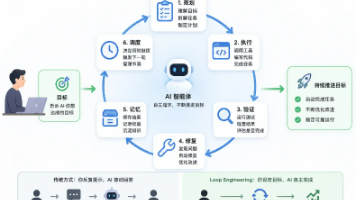
Loop Engineering 刷屏,你焦虑了吗?别急,本文用最直白的方式拆解:它不过是“自动循环 + 自动验证”,核心就两件事——怎么启动、怎么验证。其余 Skills、MCP 全是旧瓶新酒。读完这篇,你也能从容应对领导的新要求,不被概念带偏。
6个GitHub项目带你从“用好”到“手撸”Claude Code:前两个激活多智能体协作,效率翻倍;后四个从零手写到源码分析,搞懂原理。无论你是重度用户还是想自建代码智能体,这条学习路径都为你准备好

大模型之后,智能体成了程序员的必修课。可OpenClaw四十万行代码,谁看了不腿软?只调LangAPI却不懂原理,终究是空中楼阁。本文精选6个GitHub项目,从百行极简实现到工业级框架,帮你搭一条缓坡,真正搞懂Agent的思考、行动与进化。按顺序学下来,你也能从使用者变成构建者。
大模型之后,智能体成了程序员的必修课。可OpenClaw四十万行代码,谁看了不腿软?只调LangAPI却不懂原理,终究是空中楼阁。本文精选6个GitHub项目,从百行极简实现到工业级框架,帮你搭一条缓坡,真正搞懂Agent的思考、行动与进化。按顺序学下来,你也能从使用者变成构建者。
本期内容聚焦大模型评测的实战落地,介绍了 EvalScope 工具,演示了三种评测典型场景,深入讲解了 BLEU和 ROUGE两大评测指标,分享了如何用裁判模型实现自动化、可量化的质量评估。

本文系统介绍了大模型评测的必要性和常用方法。评测是验证模型效果的关键环节,可避免主观判断的偏差,为模型选型和迭代提供客观依据。评测方法主要包括人工评测、数据集评测和大模型自动化评测三种,各有适用场景。文章详细列举了典型评测数据集,如MMLU(通用知识)、GSM8K(数学推理)、HumanEval(代码生成)等,并推荐使用EvalScope工具进行标准化评测。通过科学评测可全面评估模型能力,确保模型

本篇文章分享了从 RAG 到 GraphRAG 再到 Agentic RAG的检索技术的精进历史,同时指明RAG始终困在“临时翻书、问完即忘”的循环的痛点。LLM Wiki 的出现,将范式从“检索”扭转为“编译”——知识不再止于向量碎片,而是沉淀为一张持续生长的结构化理解之网。就像编译器让源码可执行,LLM Wiki 让资料可理解、可关联、可积累,让知识真正“属于”你。每一次摄入都在为下一次理解铺
本期内容系统性地分享了 DeepAgents 流式输出的核心路径,并对 `stream_mode` 的几种模式进行了横向拆解与对比。从架构层面的命名空间路由,到 `updates`、`messages`、`custom` 三大粒度模式的实战,再到生产级的多模式组合——每个环节都配有可运行的代码示例,希望大家能真正掌握这套流式体系。
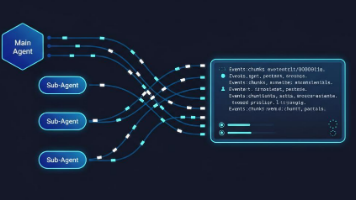
本期全面解析了DeepAgents中的Agent Skill机制。DeepAgents通过`SkillsMiddleware`与`FileSystemMiddleware`的协同,完整实现了Skills的发现、激活与执行流程。本文从Skills快速回顾入手,剖析了工程实现的四个核心步骤(发现、注入、渐进加载、执行),并通过两个实战案例(基础技能识别与文档处理Skill)展示了具体接入方法。合理使用

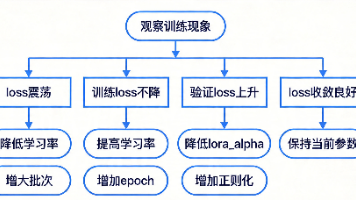
本文分享了大模型训练中的参数调整方法,从读懂训练日志、识别典型问题,到核心参数的调整方法论,再到不同场景下的调参策略,最后给出了一套标准的调参流程。调参是一门实践性很强的技能,需要在实际训练中不断积累经验。希望本文能够帮助大家建立起系统的调参思维,从"盲目试错"走向"有的放矢"。