




- @weixin_42619619
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
近日,科学界迎来了一项重大突破,人工智能公司 Evolutionary Scale在《Science》杂志上发布了其最新的研究成果 — ESM3模型,在时空尺度缩放上该模型能够模拟超过5亿年的自然进化过程,为生命科学领域带来了前所未有的变革与机遇。可以说,ESM3的多模态能力在蛋白质研究领域尚属首次,通过这种多模态的分析和生成方式,科学家们能够更深入地理解、掌控蛋白质在序列、结构和功能之间的关系,
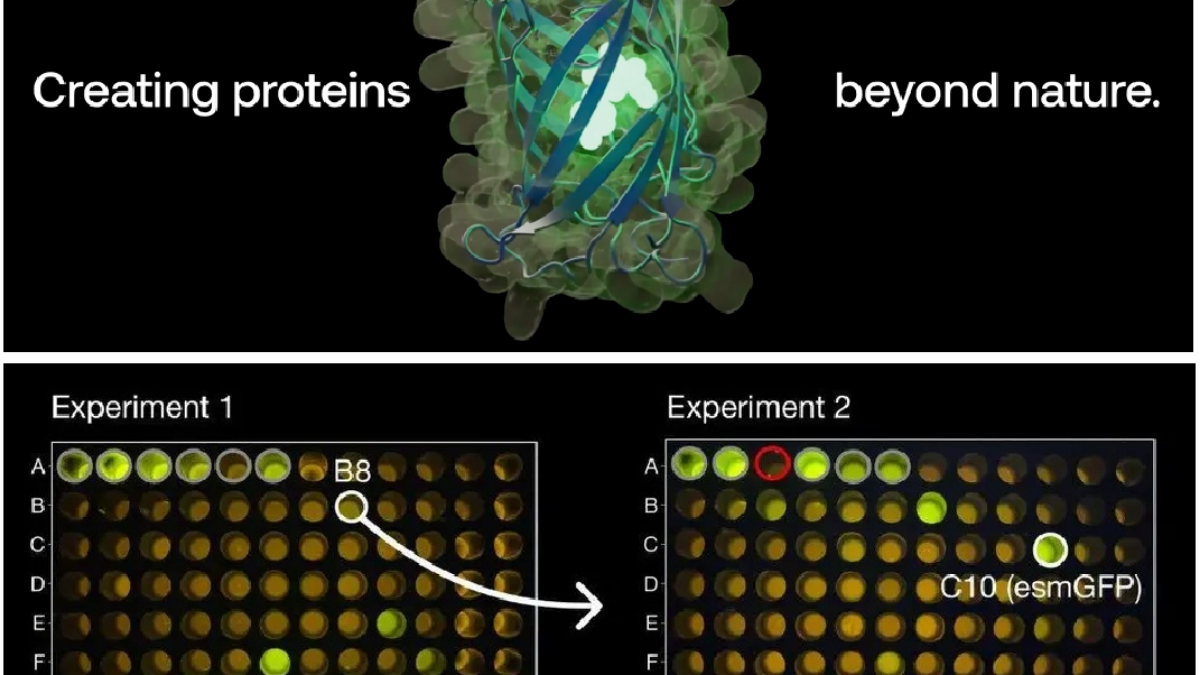
最近结合本职工作在尝试思考大模型在医疗场景的大规模alignment方面时,以及医疗领域的post-training的传统知识增强模式,直觉上似乎洞察到了一些不同以往的精细化知识增强的简单粗暴式知识增强范式的转变...这两种范式在转变过程中似乎在训练任务的构造,知识或模式的范围,目标反馈的形式上看似表面上有着很大不同,但其本质上也许是等同的。站在今天的视角来看,感觉一年前关于system2·慢思考

本篇系列内容的是建立于自己过去一年在以LLM为代表的AIGC快速发展浪潮中结合学术界与产业界创新与进展的一些碎片化思考并记录最终沉淀完成,在内容上,与不久前刚刚完稿的那篇10万字文章「融合RL与LLM思想,探寻世界模型以迈向AGI」间有着非常紧密的联系..

虽然一种新的训练范式的成功与否离不开模型结构与算法的创新,当然除了在模型和方法的创新外,也需要更全局的洞察到真实世界中所映射的数据与认知模式的完整流形分布是否与上述“创新”是匹配的。未来,这一路径与未来RL的某种路径也许会更加创新性的耦合到一起,但技术上的挑战和理论上的复杂性可想而知,不过看到这篇论文中对技术方法的尝试以及理论的创新还是让人蛮兴奋的~感兴趣的大伙可以精读一下原论文,或者我们也可以随
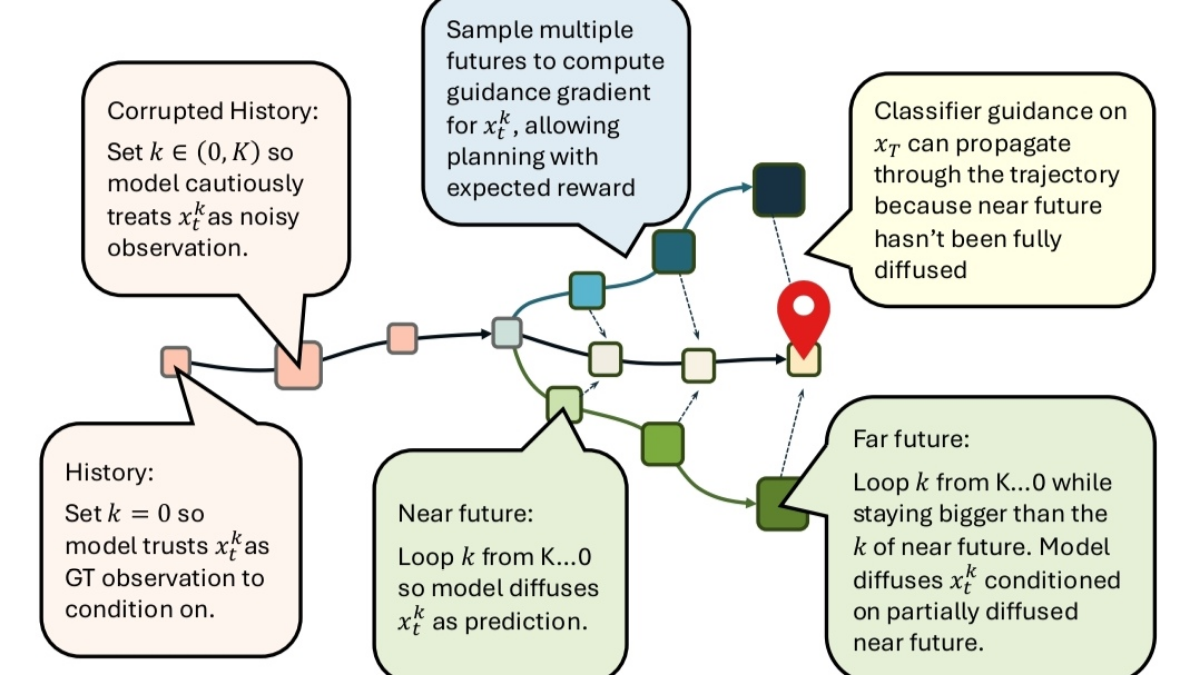
言归正传,随着近期OpenAI o1的发布以及test-time compute scaling law的袭来,对RL与LLM融合的思想范式被大家所认同和熟知,但我想当前我们对这一范式的探索也仅仅是冰山一角,不管是显式的对于复杂推理任务空间的持续探索策略与奖励反馈,还是对隐含在显式推理下模型对底层认知机理中的泛化与表征,包括推理框架在真实任务场景实践落地过程中工程与效率在平衡与优化上的诸多tric
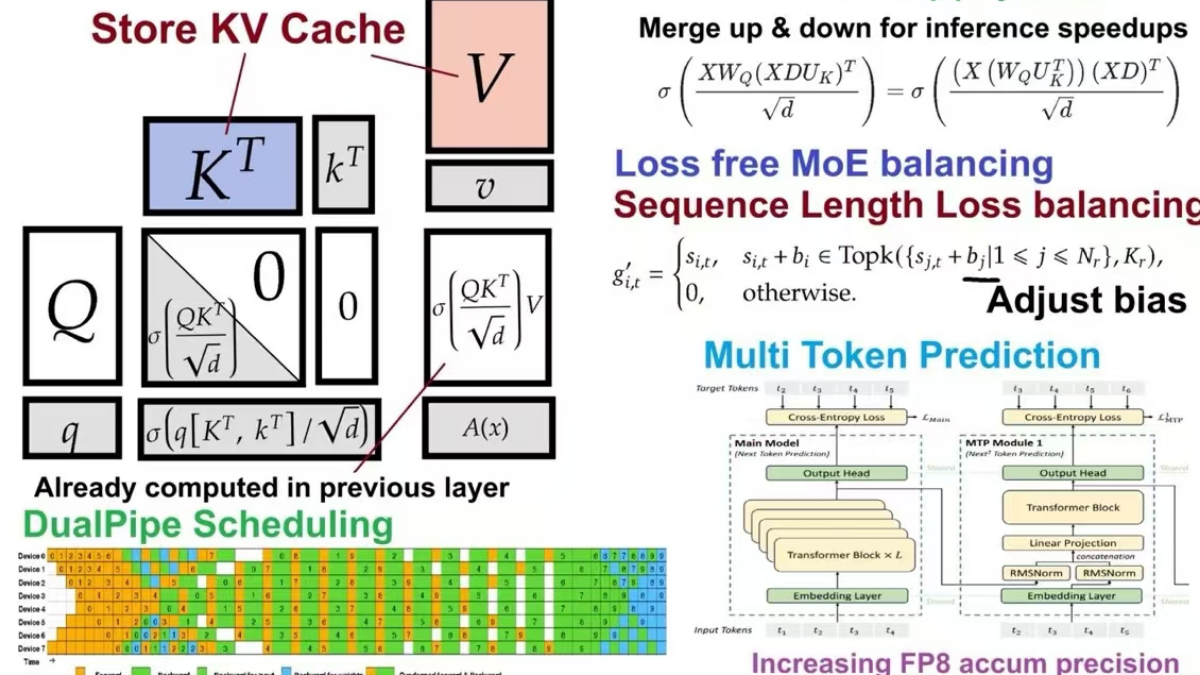
这个点子在保证了多头注意力的灵活性的同时,也有效化解了大部分存储与计算开销。DeepSeek v3的亮点绝不仅仅是“Float8”或“超长上下文”这么简单,而是贯穿了从数值精度、注意力机制、MoE路由到大规模分布式训练的一整套系统性革新,仿佛在宣示一个更激进、更大胆、更工程化的时代正在到来。虽然这种“模型自我生成训练集”的方式难免引发对数据多样性和真实性的担忧,但如果他们能在实践中验证合成数据并没
篇文章于2023年底尝试挖掘并探寻以ChatGPT为代表的LLMs和以AlphaGO/AlphaZero及当下AlphaDev为代表的Alpha系列之间的AR和RL思想的背后底层理论及形式上的统一,同时尝试基于去年OpenAI暴露出的project Q*可能的关于推理过程学习再到系统①(快)思考与系统②(慢)思考的形式化统一的延展性思考,以展望当下面向未来AGI路径可行性...正如前几日AI一姐李

这个点子在保证了多头注意力的灵活性的同时,也有效化解了大部分存储与计算开销。DeepSeek v3的亮点绝不仅仅是“Float8”或“超长上下文”这么简单,而是贯穿了从数值精度、注意力机制、MoE路由到大规模分布式训练的一整套系统性革新,仿佛在宣示一个更激进、更大胆、更工程化的时代正在到来。虽然这种“模型自我生成训练集”的方式难免引发对数据多样性和真实性的担忧,但如果他们能在实践中验证合成数据并没