




- @weixin_42479327
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
FasterRCNN tensorflow-keras源码解读提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加例如:第一章 Python 机器学习入门之pandas的使用提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录FasterRCNN tensorflow-keras源码解读前言一、pandas是什么?二、使用步骤1.引入库2.读入数据总结前言faste
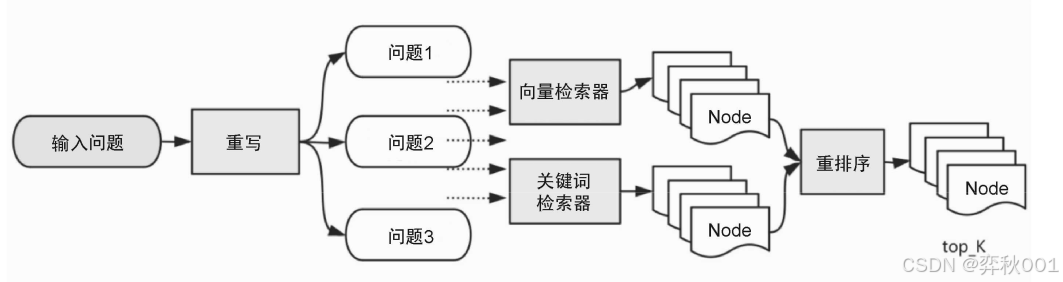
融合检索器是通过多个不同的检索方法进行检索,并对检索的结果使用 RRF 算法(或其他算法)重排序后输出,它可以组合多个不同的输入问题或者不同类型索引的检索结果,以弥补单个索引在检索精确性上的不足。在后端后端 Agent 模块中,通过两级的 Agent 之间的配合,结合底层的 RAG 查询引擎来完成更复杂的知识型任务。(一)中描述的架构,top agents也可归类为一种检索前优化,即对检索工具进行
记录一下工作中进行多机多卡部署qwen2.5-vl多模态大模型踩过的坑第一个天坑就是官方提供的镜像qwenllm/qwenvl:2.5-cu121有问题,在titan显卡会抛出cuda error:no kernel image is availabe for execution on the device. 这是cuda内核与GPU不兼容的问题,可是手动制作的其他cuda12镜像就能跑。

查询引擎可以通过()的方式一步构建完成,但若要实现更复杂的RAG流程,则需要我们精准控制query_engine的内部细节,这里我们手动构建一个。2.1 自定义响应器通俗地说,查询引擎=检索器+响应器,检索器可灵活操作的代码不多,这里仅构建响应器# 自定义响应器"根据以下上下文信息:\n""使用中文回答以下问题\n ""问题: {query_str}\n""答案: "self,) -> None:

目前为止,我们提到了很多次物理块的概念,到底什么是块呢?首先来看下物理块block(在块管理器BlockSpaceManager中使用)self,) -> None:# 该物理块在对应设备上的全局block索引号# 每个block槽位数量(默认16)# 在prefix caching场景下使用,其他场景值为-1# 该物理块的hash值是由多少个前置token计算而来的,非prefix cachin

你有没有遇到过这种情况,某天,你老板(**调度**)来到你面前,跟你(**running**)说,亲,你的工作饱和吗(**最大吞吐量**),要不要给你再来点?我想你肯定没遇到过。真实的情况是,老板会直接把工作甩你脸上,工作不饱和你就干吧,没时间干(**gpu资源不足或处理数量超出阈值**)就先积压起来(watiing or swapped),有时间再搞。

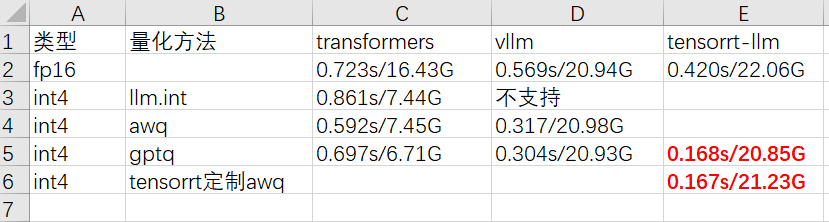
准备部署lora微调好的语言大模型,有tensorrt-llm和vllm两种加速策略可选,而量化策略也有llm.int8,gptq,awq可用, 怎样的组合才能获得最佳精度与速度呢,这是个值得探讨的问题,本文以llama-factory训练的qwen-7b的lora模型为基准,探究这几个组合对性能的影响。大模型的效果评估是件很难做的事,尤其是对文本生成类的lora模型,比较简单的办法是把生成文本与
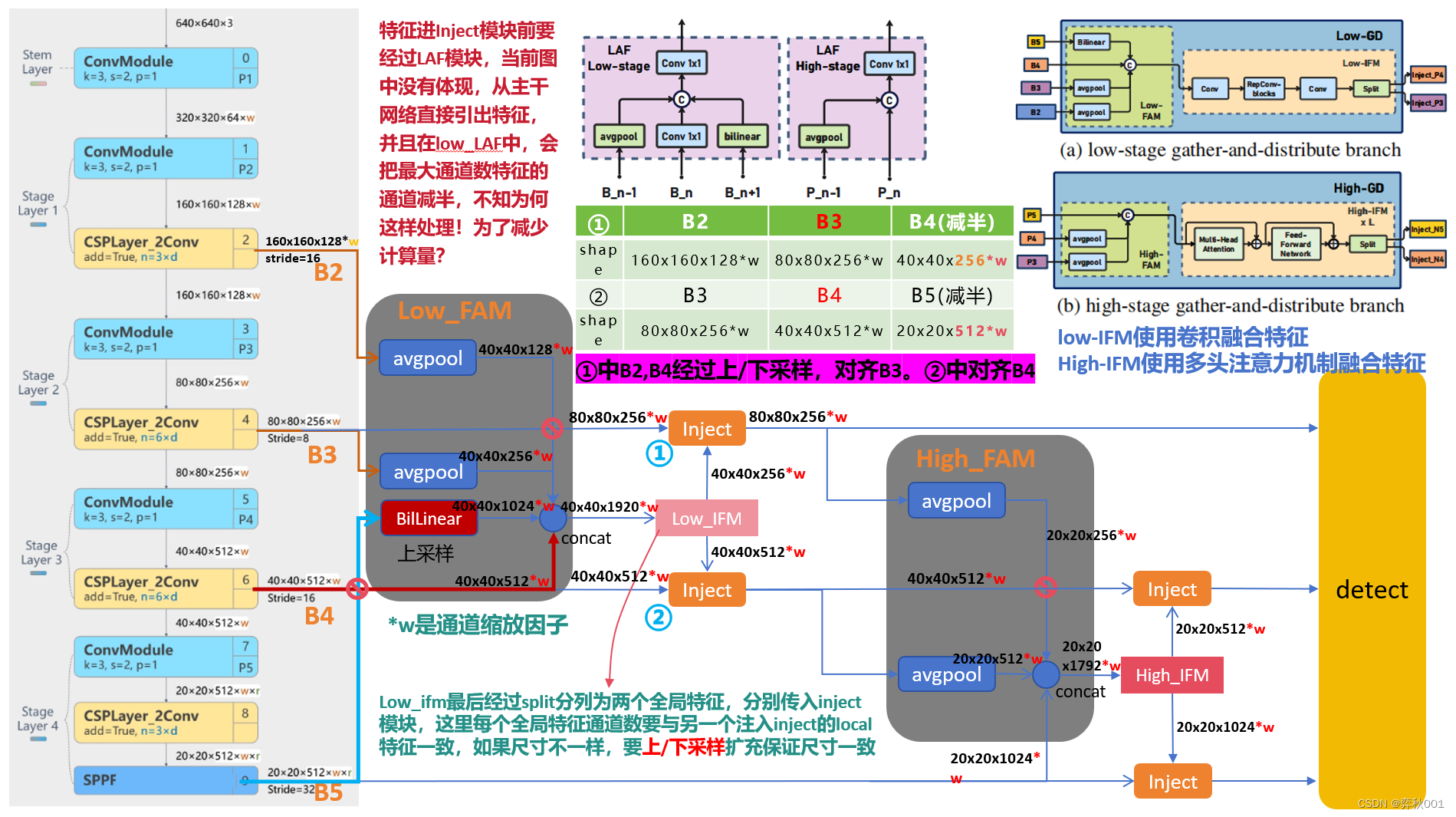
Gold-Yolo是华为诺亚方舟实验室2023年发布的工作,主要优化检测模型的neck模块。论文上展示的效果挺棒的, 打算引入到yolov8中,替换原有的neck层.目标检测模型一般都是分成3个部分,backbone,neck,head,其中neck部分,主要是类似fpn的结构,将不同层级的特征进行融合。
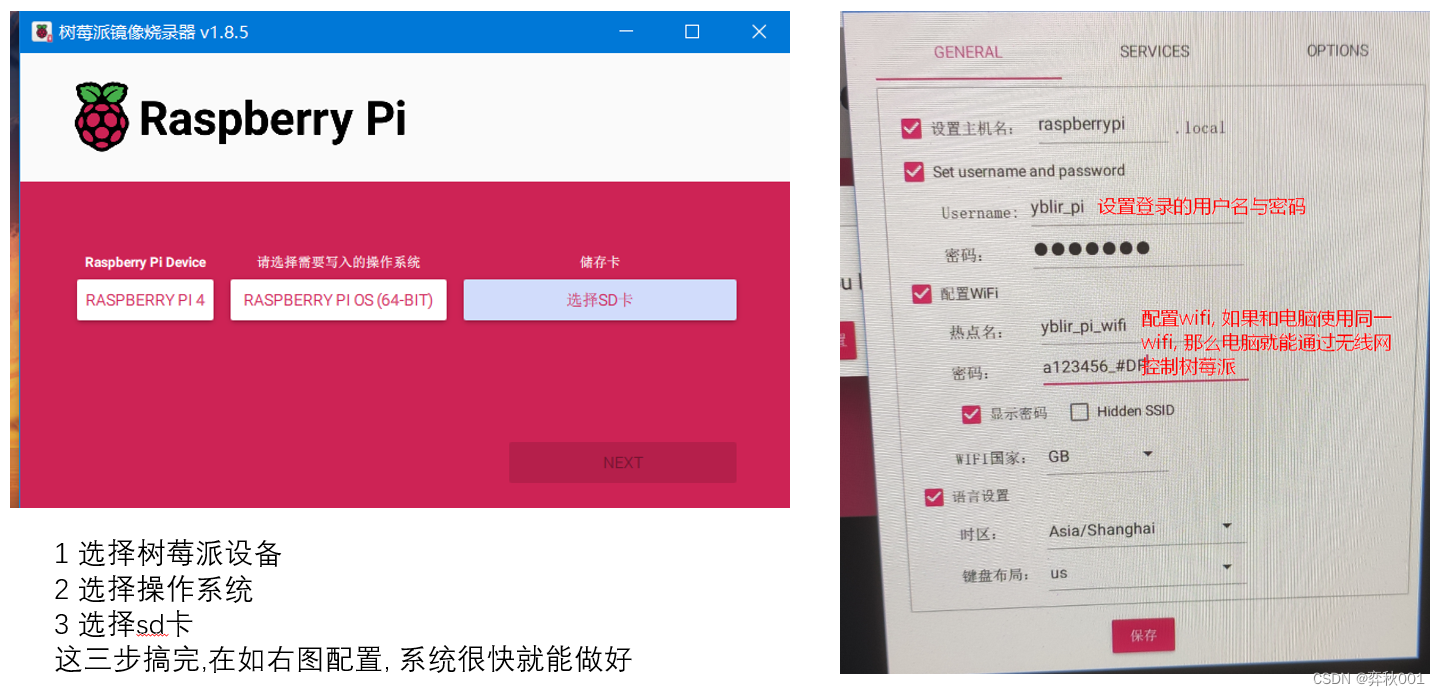
从咸鱼淘了一个树莓派4/4G设备,测试一下TVM优化的yolov8模型在嵌入式端的推理速度.
想在服务器上用vllm部署qwen2.5-vl, 然后使用gradio页面在本地调试,官方代码给了两条命令,列出的request body体结构, 不过要与gradio连用, 还需要重新组织代码。
