




- @weixin_42437114
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文为《深度学习入门 基于Python的理论与实现》的部分读书笔记,也参考吴恩达深度学习视频代码以及图片均参考此书目录CNN网络整体结构卷积层CNN网络整体结构CNN 的层的连接顺序是“Convolution - ReLU - (Pooling)”(Pooling 层有时会被省略)。还需要注意的是,在上的CNN中,靠近输出的层中使用了之前的“Affine - ReLU”组合。此外,最后的输出层中使
本文为《深度学习入门 基于Python的理论与实现》的部分读书笔记代码以及图片均参考此书目录参数的更新SGD(stochastic gradient descent)介绍更多优化方法之前的预热指数加权平均(Exponentially weighted average)带偏差修正的指数加权平均(bias correction in exponentially weighted average)Mom
[Arxiv 2019] Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
参考:《昇腾AI处理器架构与编程——深入理解CANN技术原理及应用》目录背景昇腾AI处理器总览背景为了满足当今飞速发展的深度神经网络对芯片算力的需求,华为公司于2018年推出了昇腾系列AI处理器,可以对整型数或浮点数提供强大高效的乘加计算力。由于昇腾AI处理器具有强大的算力并且在硬件体系结构上对于深度神经网络进行了特殊的优化,从而使之能以极高的效率完成目前主流深度神经网络的前向计算,因此在智能终端
本文为《深度学习入门 基于Python的理论与实现》的部分读书笔记代码以及图片均参考此书目录复习感知机激活函数(activation function)sigmoid函数tanh函数ReLU(Rectified Linear Unit)函数神经网络的前向传播通过矩阵点积运算打包神经网络的运算引入符号各层间信号传递的实现输出层的设计softmax函数输出层的神经元数量批处理复习感知机之前介绍的朴素感
本文为《深度学习入门 基于Python的理论与实现》的部分读书笔记,也参考吴恩达深度学习视频代码以及图片均参考此书目录CNN网络整体结构卷积层CNN网络整体结构CNN 的层的连接顺序是“Convolution - ReLU - (Pooling)”(Pooling 层有时会被省略)。还需要注意的是,在上的CNN中,靠近输出的层中使用了之前的“Affine - ReLU”组合。此外,最后的输出层中使
本文为《深度学习入门 基于Python的理论与实现》的部分读书笔记代码以及图片均参考此书目录权重的初始值权重初始值可以设为0吗(随机生成初始值的重要性)观察权重初始值对隐藏层激活值分布的影响Xavier 初始值He初始值归一化输入(Normalizing inputs)Batch NormalizationBN层的正向传播BN层的反向传播基于计算图进行推导不借助计算图,直接推导代码实现权重的初始值
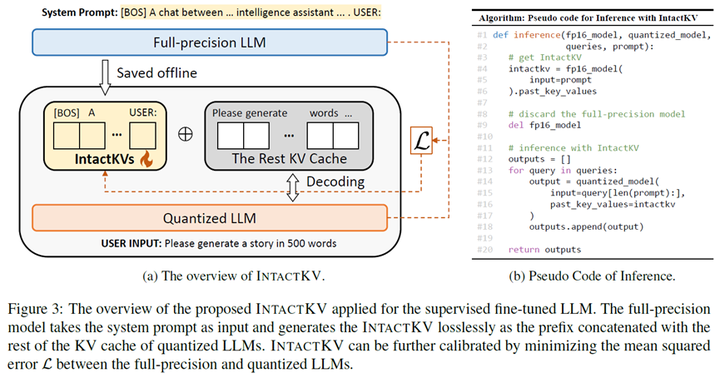
本文介绍我们针对大语言模型量化的工作 IntactKV,可以作为插件有效提升 GPTQ、AWQ、QuaRot 等现有主流量化方法效果。论文作者来自清华大学、华为诺亚、中科院自动化所和香港中文大学。论文代码已经开源,欢迎大家使用!
目录References加权平均Referencespaper: Two-Stream Convolutional Networks for Action Recognition in Videos双流网络论文逐段精读【论文精读】
目录马尔可夫链马尔可夫链的基本定义离散状态马尔可夫链 (Finite-State Markov Chains)转移概率矩阵状态分布平稳分布 (steady-state vector / equilibrium vector)平稳分布的定义平稳分布的存在性如何找到平稳分布?连续状态马尔可夫链马尔可夫链的简单应用语言模型马尔可夫链的性质不可约非周期正常返遍历定理可逆马尔可夫链参考文献马尔可夫链马尔可夫