




- @weixin_41973200
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
通过在提示词中多给一些准确案例,实现结果精准推理。比如在以下system_prompt中,多给一些EXAMPLE,出结果。","""
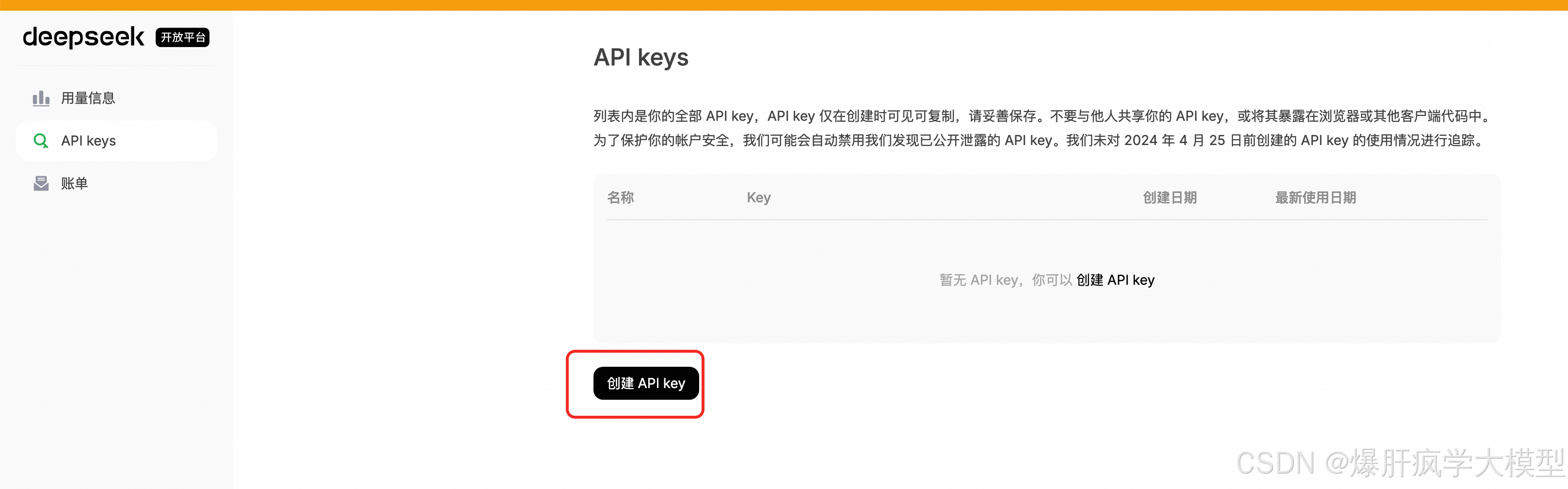
拉取镜像发生报错,告知磁盘没有空间了。但是电脑上挂载的磁盘在/scratch还有一个t,于是决定移动下docker数据存储的位置。

在服务器编辑文件时可以使用sudo去进行文件编辑,但是vscode连接服务器由于没有sudo导致无法进行编辑。
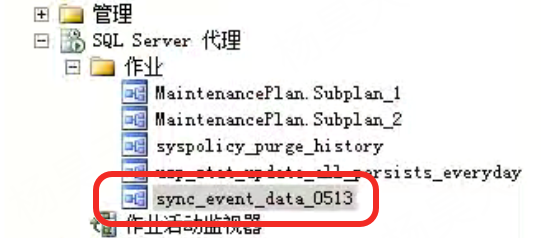
数据需要定期迁移,数据存在于客户政务外网下,从旧数据库迁移到新数据库中,且要求能够定时增量同步。注意:源数据库所在服务器为windows服务器,目标数据库所在服务器为linux服务器。源数据库所在windows服务器可以连接到目标数据库,但目标数据库无法连接到源数据库。
在服务器编辑文件时可以使用sudo去进行文件编辑,但是vscode连接服务器由于没有sudo导致无法进行编辑。
通过在提示词中多给一些准确案例,实现结果精准推理。比如在以下system_prompt中,多给一些EXAMPLE,出结果。","""
通过在提示词中多给一些准确案例,实现结果精准推理。比如在以下system_prompt中,多给一些EXAMPLE,出结果。","""
数据需要定期迁移,数据存在于客户政务外网下,从旧数据库迁移到新数据库中,且要求能够定时增量同步。注意:源数据库所在服务器为windows服务器,目标数据库所在服务器为linux服务器。源数据库所在windows服务器可以连接到目标数据库,但目标数据库无法连接到源数据库。
2.https://www.jianshu.com/p/96988c3bebe6(以后可以借鉴的远程桌面Linux — Gui与Xvfb的使用)1.https://blog.csdn.net/weixin_33708432/article/details/91536037(我使用的)因为用的是linux远程服务器,是没有图形界面的,所以为了解决这个问题,进行以下方式处理。用ssh -X root@

通过在提示词中多给一些准确案例,实现结果精准推理。比如在以下system_prompt中,多给一些EXAMPLE,出结果。","""