




- @weixin_39326879
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
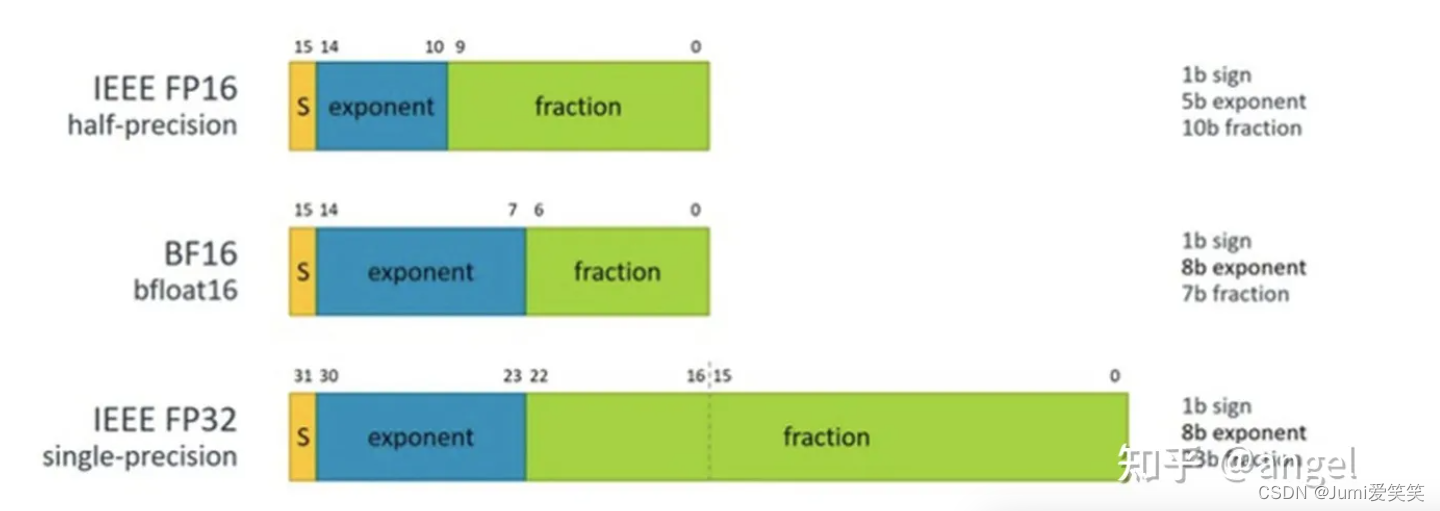
符号位表示数的正负,指数位用于表示数的指数部分,尾数位用于表示数的尾数部分。线性层和卷积层,本质上都是线性操作,卷积层相当于共享参数的线性操作,但是self-attention是高阶的非线性操作,ResNet是由齐次运算堆叠而成,关注局部区域,而transformer是由非齐次运算堆叠而成,关注更大区域和更高的语义,齐次和非齐次运算的雅可比矩阵有非常不同的特性,会导致不同的优化难度;雅可比矩阵的连
https://wizardforcel.gitbooks.io/learn-dl-with-pytorch-liaoxingyu/content/2.3.html
vscode debug
原文地址:https://chenhsuanlin.bitbucket.io/3D-point-cloud-generation/paper.pdf摘要:对于3D物体的重建,信息主要丰富在表面。本文的目的在于以密集点云的形式表示3D模型,这边文章讲的就是用2D图像如何生成3D模型。2D图像也是从3D的世界投影来的,从3D到2D必然是缺少了很多信息的,所以单一视角的2D图像是不可能恢复出3D模...
1.AlexnetAlexnet是2012年发表的,是在imageNet 1000种分类上做图片分类的在该文中提出了dropout的概念Top1和Top5的错误率分别是37%和17%。其网络架构非常简单,包含8层—5个卷积层+3个全连接层。强调了relu激活的好处,计算速度比sigmoid快多了,由下面这幅图可以看出来:下降到0.25的错误率所需要的迭代次数,使用relu要快多了同时这里还应用了归
1.AlexnetAlexnet是2012年发表的,是在imageNet 1000种分类上做图片分类的在该文中提出了dropout的概念Top1和Top5的错误率分别是37%和17%。其网络架构非常简单,包含8层—5个卷积层+3个全连接层。强调了relu激活的好处,计算速度比sigmoid快多了,由下面这幅图可以看出来:下降到0.25的错误率所需要的迭代次数,使用relu要快多了同时这里还应用了归
强化学习是一种学习方式,跟监督学习、无监督学习并列的学习方式,需要跟环境进行交互,然后更新参数。强化学习是一种通过跟环境交互获取反馈、更新参数的学习方式,目前主要用在游戏中,强化学习算法的思路非常简单,以游戏为例,如果在游戏中采取某种策略可以取得较高的得分,那么就进一步「强化」这种策略,以期继续取得较好的结果。这种策略与日常生活中的各种「绩效奖励」非常类似。我们平时也常常用这样的策略来提高自己的游
前言普通相机环绕带有BCH码标识的目标物体拍摄大量图片也是可以构建3D模型的本文探讨基于深度相机拍摄的图片准备工作1.深度相机,并标定其内参和畸变2.BCH码图片(我的博客里面有图片可以下载)3.你的目标物体(注意不要带有反光的金属、或者透明的部分,因为会导致在深度图不准确)备注:还要记得查看一下深度相机的工作距离,了解一下它的性能,一般深度相机都是以相机本身为原点建立世界坐标系的,且离z轴越近精
https://www.mathworks.com/help/driving/examples/automate-ground-truth-labeling-of-lane-boundaries.htmlmatlab对一个车道线有一个自动标注的工具,预先定义好ROI的样式后,它使用算法先进行检测,然后认为查看哪些图片标注错了手工进行修正。...
1.arm\x86-64的区别指令集不一样2.arm架构上的conda要安装miniforge3.arm上的ubuntu的软件管理器是pacman,这个安装起来也有点麻烦,因为这个库有一些前置依赖库pkg-config;4.如果dockerfile里面的CMD和entrypoint什么都没写的,直接docker run起来的容器会很快退出,而且没有log,如果要在容器中停留比较久的话需要-it进入
