- @uwvwko
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
它本质上是一个精确的、静态的流程图,规定了在何种条件下、以何种顺序执行哪些操作。
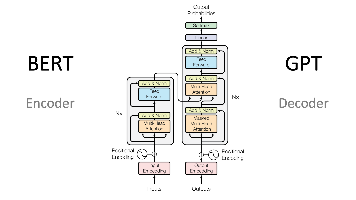
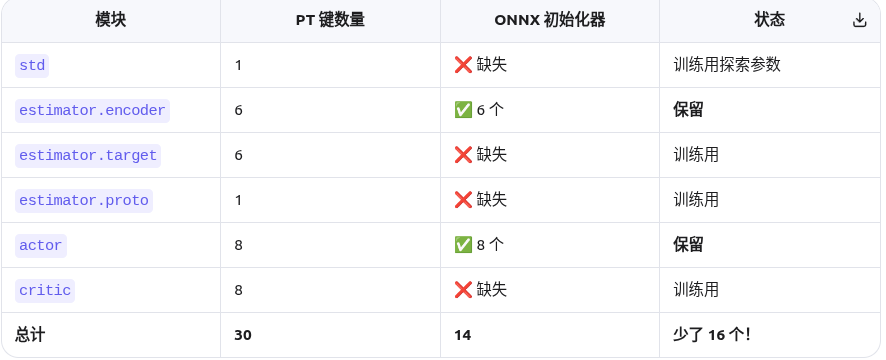
计算图可以理解为提前把整个网络的结构写好,这样用的时候就不用一行行解析python代码了,所以也实现了跨语言,速度也更快,当然,快不过onnx。经过前面的学习,我们大概都知道有这些不同的模型了,也知道一些他们的运用场景,然后我想再学习一下他们都是由什么组成的。因为我这里onnx是纯推理,而且由于HIMLoco的框架设计,就导致实际的onnx中的初始化器个数比pt的键值少。他的推理是比正常的pyto
我的同僚们修改代码,改项目什么的,雀氏有直接在云服务器运行openclaw让他自己去修,目前很多云部署是免费的(风口抢用户),然后服务器刚开始价格也比较低,但是,要知道,这东西最耗钱的是token,大量的token,各大公司或许网页让你免费用,但是接api可是要钱的啊(狗头)如图所示,这就是一个skill的具体的实现了,是的,就是一个SKILL.md,当然我并不是在说这个skill做的怎么怎么样,
本文介绍了使用YOLO模型进行水果目标检测的完整流程。首先配置fruit_data.yaml文件,指定训练集和验证集路径,设置3个检测类别(苹果、香蕉、橙子)。训练代码使用YOLOv11n预训练模型,设置50个epoch和640x640图像尺寸。对于数据标注,采用labelImg工具手动标注图像生成YOLO格式的txt文件,解决了工具运行时的类型错误问题。训练完成后,使用best.pt模型进行推理
原视频就是坤坤的视频我们的任务就是把篮球圈出。
原视频就是坤坤的视频我们的任务就是把篮球圈出。
将你的模型下载好,放入\ComfyUI\models\checkpoints,在网页端选择,并输入正反提示词,就可以开始生成你的第一张图了。在 Stable Diffusion 的世界里,图像不是直接在像素空间(我们看到的 RGB 图像)中生成的,而是在一个更抽象、更高效的。12.0 是一个偏高的值,适合要求严格遵循提示词的场景。○ 数值过低: AI 会更自由发挥,可能忽略提示词的关键内容(比如“
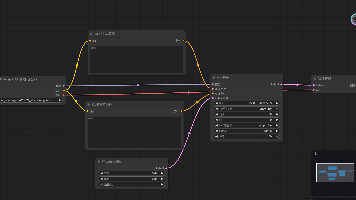
文档我是分开下的,直接一键下载docker拉不完全。
将你的模型下载好,放入\ComfyUI\models\checkpoints,在网页端选择,并输入正反提示词,就可以开始生成你的第一张图了。在 Stable Diffusion 的世界里,图像不是直接在像素空间(我们看到的 RGB 图像)中生成的,而是在一个更抽象、更高效的。12.0 是一个偏高的值,适合要求严格遵循提示词的场景。○ 数值过低: AI 会更自由发挥,可能忽略提示词的关键内容(比如“
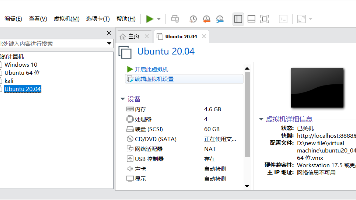
会进入到类似这个界面(每个人的电脑不一样,我这个根目录再sda5中,sda5又在sha2下,所以我要先挂2再挂5)然后sudo apt-get install gparted——安装工具。可以看到我们有20G的未分配空间,要求要挂载到/dev/sda5上。我们把它拉满(即之前/之后可用空间都为0),然后点击下方调整大小。同样的操作对/dev/sda5再进行一次。选择要扩容的虚拟机,点击编辑虚拟机设