- @u014665013
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文摘要: Claude Skill开发流程分为两个核心目录结构:Skill目录存放定义和源码,Workspace目录存放评估结果。完整工作流包含8个阶段:意图捕获、访谈调研、编写SKILL.md、设计测试用例、并行测试、评分聚合、迭代改进、触发优化和打包分发。每个阶段都有明确的目标、输入输出和文件关联,其中特别强调需求澄清的重要性,以及渐进式加载、主动触发描述等设计细节。流程注重从对话历史反向提

先贴几个站点,有时间再归纳一下,关于bert的实战,后面也会整理出来reference使用C++调用TensorFlow模型简单说明C++运行TensorFlow模型tensorflow/tensorflow
文章目录1.基于指数型的衰减1.1.exponential_decay1.2.piecewise_constant1.3.polynomial_decay1.4.natural_exp_decay1.5.inverse_time_decay2.基于余弦的衰减2.1.cosine_decay2.2.cosine_decay_restarts2.3.linear_cosine_decay2.4.noi
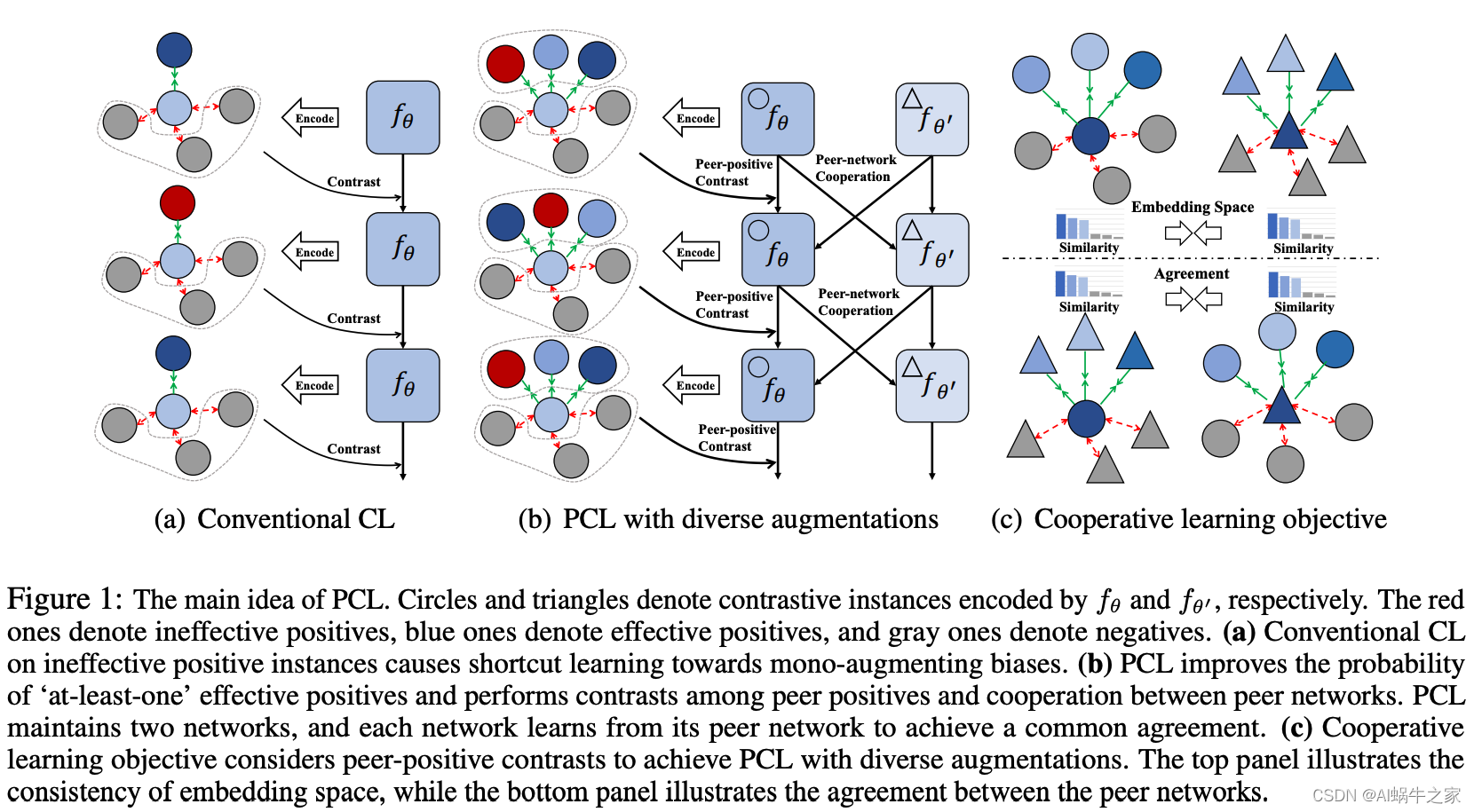
1. 自监督1.1.PCL: Peer-Contrastive Learning with Diverse Augmentations for Unsupervised Sentence Embeddings1.2.TRANS-ENCODER 自监督的Sentence Bi & Cross Encoder1.3.Mirror-Bert1.3.1.相关背景1.3.2.方法介绍1.4.Self-gui
文章目录1.基于指数型的衰减1.1.exponential_decay1.2.piecewise_constant1.3.polynomial_decay1.4.natural_exp_decay1.5.inverse_time_decay2.基于余弦的衰减2.1.cosine_decay2.2.cosine_decay_restarts2.3.linear_cosine_decay2.4.noi
首次验证了纯强化学习在 LLM 中显著增强推理能力的可行性(DeepSeek-R1-Zero),即无需预先的 SFT 数据,仅通过 RL 即可激励模型学会长链推理和反思等能力。提出了多阶段训练策略(冷启动->RL->SFT->全场景 RL),有效兼顾准确率与可读性,产出 DeepSeek-R1,性能比肩 OpenAI-o1-1217。展示了知识蒸馏在提升小模型推理能力方面的潜力,并开源多个大小不一

深度搜索系列再前期的一些ReAct、Self Refine、CoT-SC相关偏向Prompt工程之后,近期的SFT尤其是RL相关方法工作很多,最近打算对深度搜索近期工作整体整理一下(Search-R1、Search-O1、R1-Searcher、R1-Searcher++、SimpleDeepSearcher名字是真的像啊)。另外人大的相关工作占据了半壁江山~

**Qwen3发了什么?**- 发布了密集型和专家混合(Mixture-of-Experts, MoE)模型,参数数量从 0.6 亿到 235 亿不等,以满足不同下游应用的需求。- 将两种不同的运行模式——思考模式和非思考模式——整合到单一模型中。这允许用户在这些模式之间切换。集成了思考预算机制,为用户提供了对模型在任务执行过程中推理长度的细粒度控制。**训练里面的核心亮点是什么?**训练过程:-

由于Linux下没有gets函数,所以提示函数警告 warning: the `gets' function is dangerous and should not be used.用fgets代替就行了。函数算在头文件:#include函数原型: int fgetc(FILE *stream); char *fgets(cha
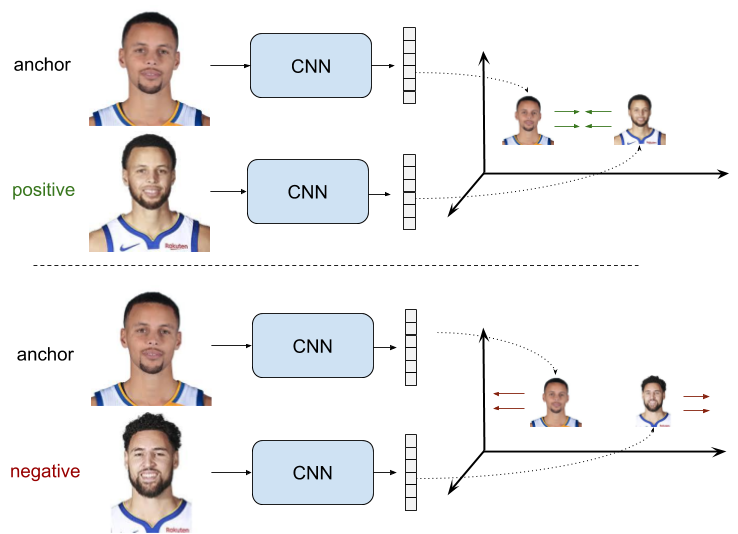
Ranking Loss被用于很多领域和神经网络任务中(如 Siamese Nets 或 Triplet Nets),这也是它为什么拥有 Contrastive Loss、Margin Loss、Hinge Loss 或 Triplet Loss 等这么多名字的原因。1.Ranking Loss 函数:度量学习像 Cross-Entropy Loss 或 Mean Squear Error Los