- @u014546828
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
随着日冕仪对日冕物质抛射(CME)观测数据的不断积累,CME的自动检测与跟踪技术已被证明至关重要。卷积神经网络在图像分类、目标检测等计算机视觉任务中的卓越表现,促使我们将其应用于CME的检测与跟踪。我们开发了一种基于机器学习技术的CME自动检测与跟踪新工具——CAMEL(CME Automatic detection and tracking with MachinE Learning)。该系统由
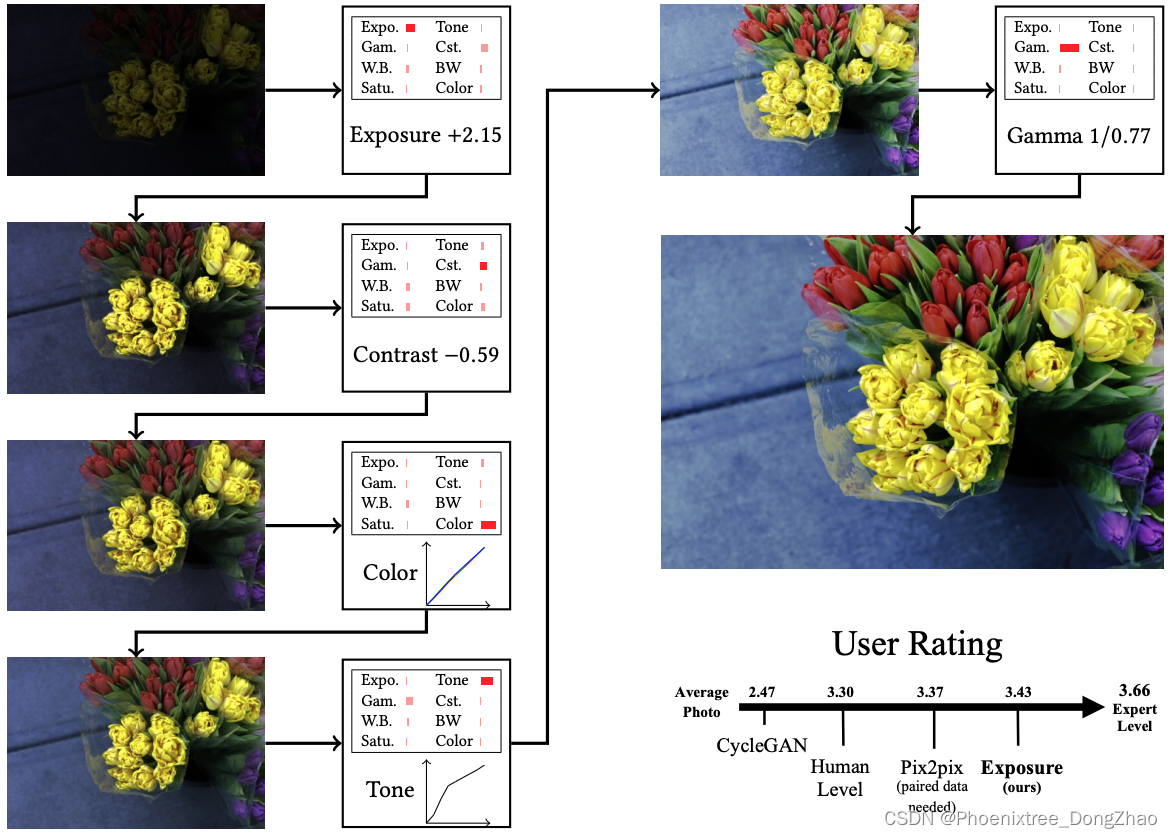
本文采用强化学习实现图像编辑,问题与方法契合度很高,因此是一个不错的思路。人为的图像编辑通常是采取不同操作[pdf]Fig. 1. Our method provides automatic and end-to-end processing of RAW photos, directly from linear RGB data captured by camera sensors to vis
香浓信息量这里以连续随机变量的情况为例。设为随机变量X的概率分布,即为随机变量在处的概率密度函数值,随机变量在处的香农信息量定义为:这时香农信息量的单位为比特,香农信息量用于刻画消除随机变量在处的不确定性所需的信息量的大小。如果非连续型随机变量,则为某一具体随机事件的概率。为什么是这么一个表达式呢?想具体了解的可以参考如下的讨论:知乎-香农的信息论究竟牛在哪里?香农信息量_weixinhum-CS
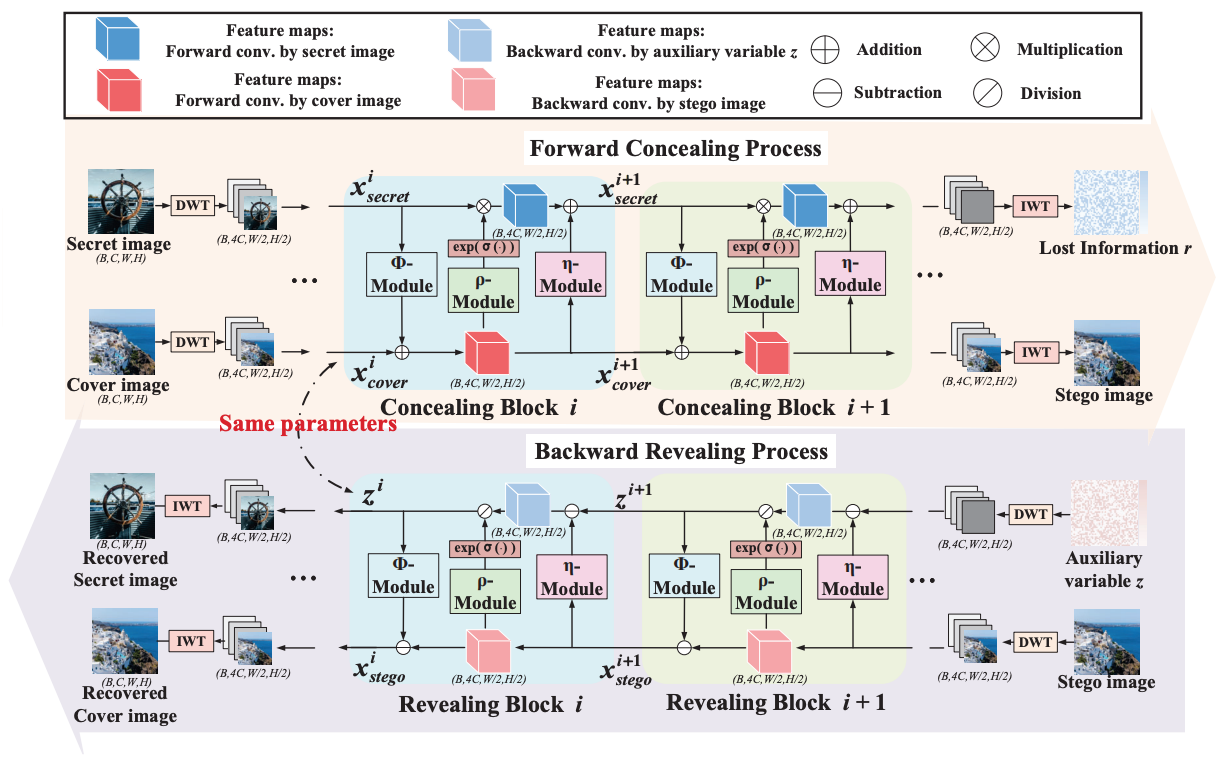
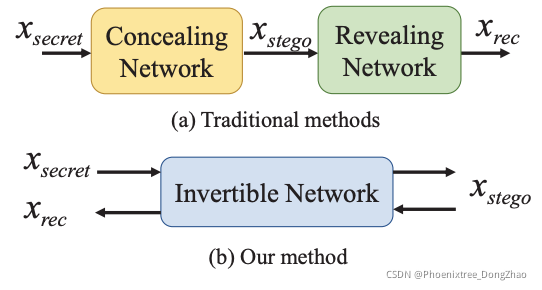
HiNet: Deep Image Hiding by Invertible Network[pdf] [github]Figure 1. The illustration of difference between our image hiding method and the traditional methods [5, 23, 32].AbstractImage hiding aims t
问题:刚安装的 Visio没有开发工具这一栏。如下图1.点击 “文件”,然后选择 “选项”:------>2.在弹出的选项窗口中,点击“高级”,然后右边一直拉到最下面,点击 “以开发人员模式运行”。最后确定。3.此时出现开发工具一栏。...
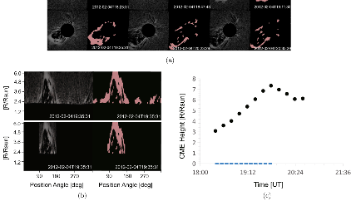
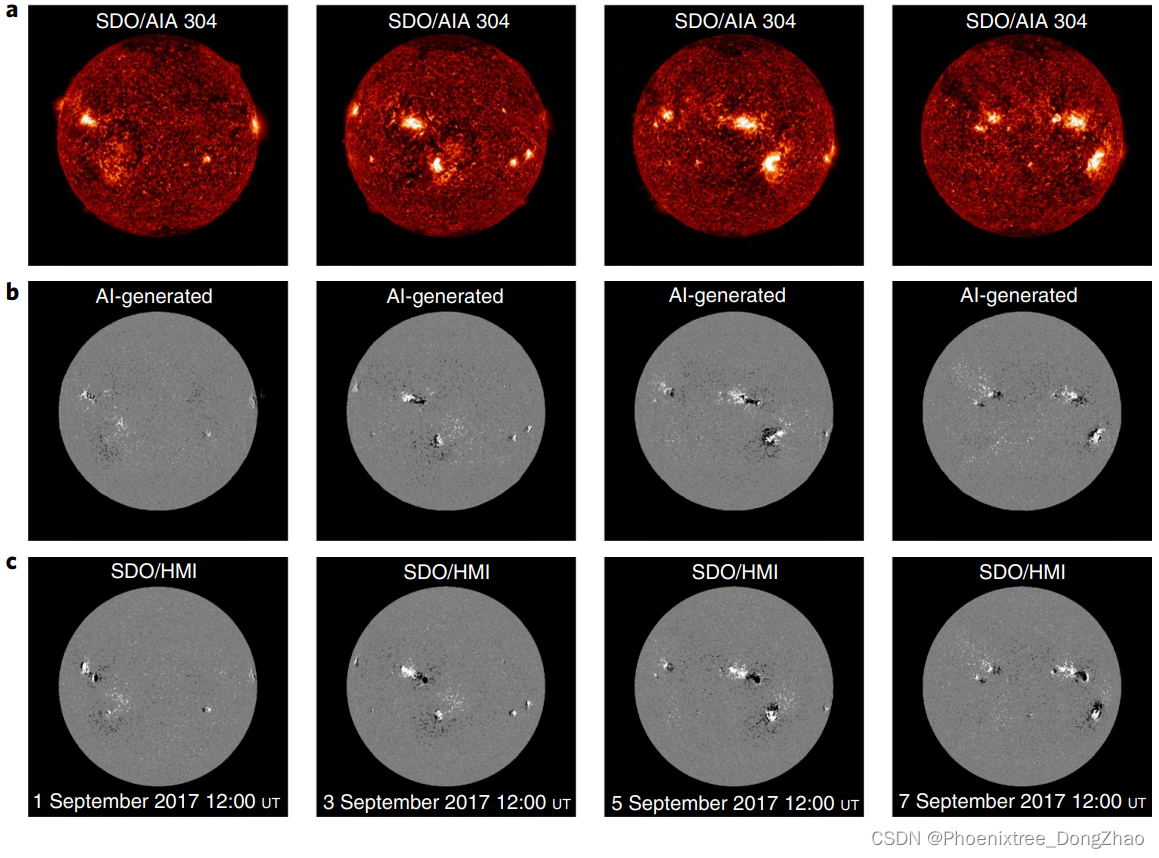
Solar magnetograms are important for studying solar activity and predicting space weather disturbances1 . Farside magnetograms can be constructed from local helioseismology without any farside data2-4
为了解决糖尿病护理中存在的差距,我们开发了一种创新的系统DeepDR-LLM,它将一个LLM模块和一个基于图像的DL模块结合在一起,提供全面的初级糖尿病护理和DR筛查方法。糖尿病视网膜病变(DR)是最常见的糖尿病特定并发症,影响30-40%的患有糖尿病的人群11,12,13,并且仍然是经济活跃、工作年龄成人失明的主要原因11,14,15。然而,在低资源环境下,由于基础设施、人力资源和可持续性具有成

突然心血来潮,想到卡尔曼滤波器是否能和深度学习结合。于是从谷歌学术上搜了一下,发现现在这方面的工作还没有太多结合。ICLR 2020 出现一篇Kalman Filter Is All You Need 的文章,但目前从开源的审稿意见来看,凶多吉少。其余的,大部分出自于一个Guy Revach 学者(团队)。Kalman Filter Is All You Need: Optimization Wo
BiFuse: Monocular 360◦ Depth Estimation via Bi-Projection Fusion[paper] [github] [project]AbstractDepth estimation from a monocular 360◦ image is an emerging problem that gains popularity due to the a
2019 iccvHiding Video in Audio via Reversible Generative ModelsHyukryul Yang,Hao Ouyang,Vladlen Koltun,Qifeng Chen[pdf][bibtex]Back2021 cvprArtFlow: Unbiased Image Style Transfer via Reversible Neural