




- @u013343616
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
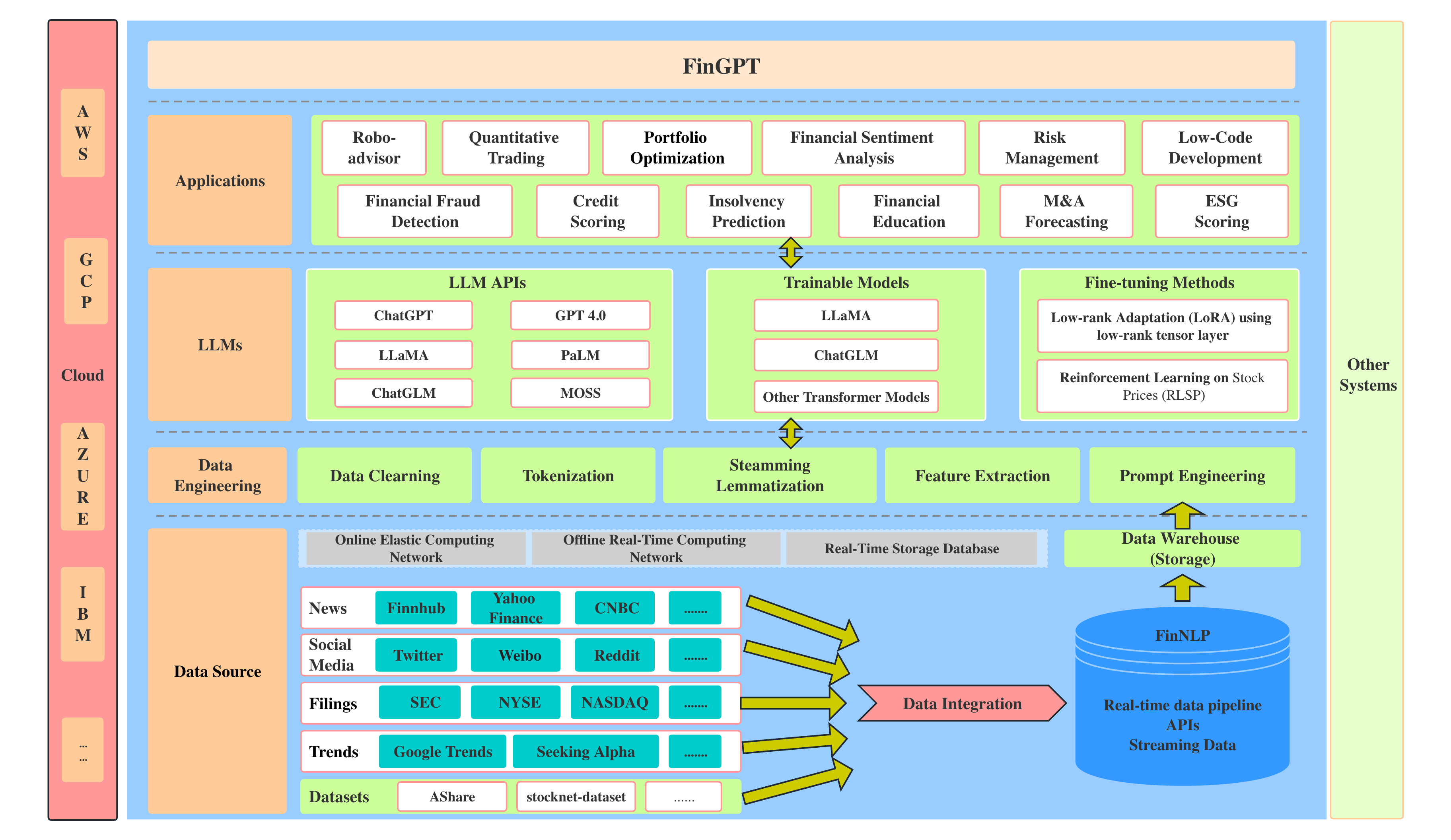
FinGPT是一个开源的金融语言模型(LLMs),由FinNLP项目提供。这个项目让对金融领域的自然语言处理(NLP)感兴趣的人们有了一个可以自由尝试的平台,并提供了一个与专有模型相比更容易获取的金融数据。FinGPT使用RLHF方法进行个性化的金融语言建模,这与BloombergGPT的方法不同。它采用了一种轻量级的低秩适应技术,使得微调模型变得更简单和经济。FinGPT项目为金融领域的自然语言
postman 分预条件脚本 pre-reuqest-script 和结果预期判断脚本 tests前置脚本//构建请求const SendRequest = {url: "localhost:8068/erpWeb/usercenter/session/userLogin",method: "POST",//请求方法header: 'Content-Type: application/json',
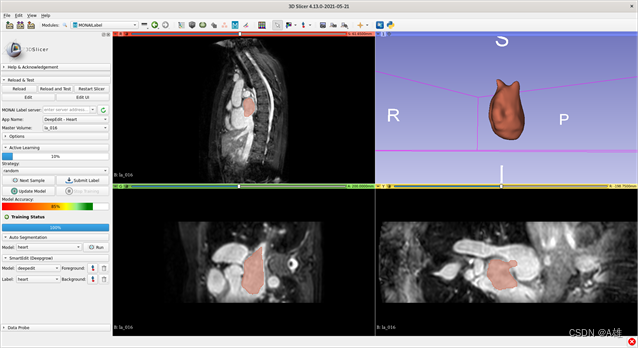
一套开源、免费的协作框架,旨在加速医学成像领域的研究和临床协作。目标是通过构建一个强大的软件框架来加快创新和临床转化的步伐,该框架有利于几乎各个级别的医学成像、深度学习研究和部署。MONAI利用 3D Slicer 和 DeepEdit 算法来注释您的图像并创建您的 AI 注释模型。MONAI Core 拥有两种最先进的基于变压器的特定于医学成像的架构。
自然语言处理(Natural Language Processing, NLP)是计算机科学中的一个重要分支,旨在让机器能够理解、处理人类语言。

postman 分预条件脚本 pre-reuqest-script 和结果预期判断脚本 tests前置脚本//构建请求const SendRequest = {url: "localhost:8068/erpWeb/usercenter/session/userLogin",method: "POST",//请求方法header: 'Content-Type: application/json',
大语言模型生成中的“幻觉率”问题,指的是模型生成的内容不准确或虚构的情况。幻觉率过高会导致错误信息的传播,特别是在一些需要高度准确性的任务中,例如法律、医学等领域。

BenTsao:[原名:华驼(HuaTuo)]: 基于中文医学知识的大语言模型指令微调本项目开源了经过中文医学指令精调/指令微调(Instruction-tuning) 的大语言模型集,包括LLaMA、Alpaca-Chinese、Bloom、活字模型等。我们基于医学知识图谱以及医学文献,结合ChatGPT API构建了中文医学指令微调数据集,并以此对各种基模型进行了指令微调,提高了基模型在医疗领

大语言模型生成中的“幻觉率”问题,指的是模型生成的内容不准确或虚构的情况。幻觉率过高会导致错误信息的传播,特别是在一些需要高度准确性的任务中,例如法律、医学等领域。
BenTsao:[原名:华驼(HuaTuo)]: 基于中文医学知识的大语言模型指令微调本项目开源了经过中文医学指令精调/指令微调(Instruction-tuning) 的大语言模型集,包括LLaMA、Alpaca-Chinese、Bloom、活字模型等。我们基于医学知识图谱以及医学文献,结合ChatGPT API构建了中文医学指令微调数据集,并以此对各种基模型进行了指令微调,提高了基模型在医疗领
token的来源是NLP和机器学习的术语,指的是文本中的基本单位。如果简单理解就是文字/词的个数,比如 hello world,就是2个tokens。又比如 我爱北京天安门,就是7个tokens,不同厂商的算法略有不同,可能会有子词单元。比如定义了一些专业术语,北京,可以把这个词组当作一个整体token,标点符号也算1个token,但空格一般不算。
