




- @u012881331
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
RustFS 是基于 Rust 语言开发的高性能分布式对象存储系统,完全兼容 AWS S3 标准协议,主打私有化部署、低延迟、无GC抖动、商用友好 Apache 2.0 开源协议,是 MinIO 国产化替代方案。
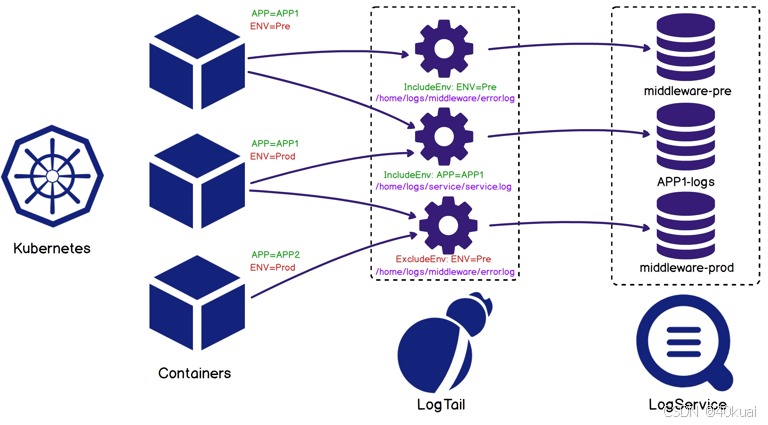
日志采集使用阿里云开源工具iLogtail,支持部署于物理机,虚拟机,Kubernetes等多种环境中来采集遥测数据,例如logs、traces和metrics。支持配置远程管理,支持以图形化、SDK、K8s Operator等方式进行配置管理,可轻松管理百万台机器的数据采集。支持多种Logs、Traces、Metrics数据采集,尤其对容器、Kubernetes环境支持非常友好。index的副本
Kubernetes Operator 是一种特定的应用控制器,通过 CRD(Custom Resource Definitions,自定义资源定义)扩展 Kubernetes API 的功能,可以用它来创建、配置和管理特定的有状态应用,而不需要直接去使用 Kubernetes 中最原始的一些资源对象。

通过一下脚本来对docker registery的历史镜像进行清理。优点:快速清理历史镜像。缺点:没有分页查询的功能。registry需要支持删除操作。storage:delete:enabled: true脚本调用registry接口对历史版本进行删除。import requestsfrom concurrent.futures import ThreadPoolExecutordef del_
第二次操作会覆盖第一次的结果,确保使用 Pod 自身的精确名称而非 Endpoint 关联的名称(两者通常相同,但在特殊配置下可能不同)。若 Endpoint 指向 Node 或其他资源,第一次操作会失败(正则不匹配),此时第二次操作可从 Pod 自身的元数据中获取名称。,确保在复杂的 Kubernetes 环境中,无论 Pod 以何种方式被发现,都能正确获取和设置关键标签。先通过 Endpoin
在elasticsearch 采集nginx日志分析的场景下发现,小于,于是才有了这边文章在 Nginx 中,和使用不同的系统时钟和精度机制来记录时间,这可能导致。功能特性:CLOCK_MONOTONIC_COARSE 是 Linux 系统的低精度单调时钟,提供毫秒级(默认 4ms 粒度)的时间记录,主要服务于高性能场景(如高频日志记录、网络请求处理)。
