




- @u012863603
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
设计了重参数化的模块,将训练和推理解耦,并且设计了两个系列的整体网络结构和相应的缩放方法,可以适应不同的精度性能需求,结果显示在GPU上推理速度高于renset系列。PS:这个网络主要考虑的是提升GPU(不是移动端)的计算密度(计算量除以计算时间),追求高速度、省内存,较少关注参数量和理论计算量。在低算力设备上,可能不如 MobileNet 和 ShuffleNet 系列适用。主要借鉴了ACNet
linux 查看cuda、cudnn版本。以及推理变慢等原因的排查。
由于当前版本安装后,大家反应import nvcv cvcuda 失败,看官方文档,当前还不是很规范,特此记录当前版本的安装方法。
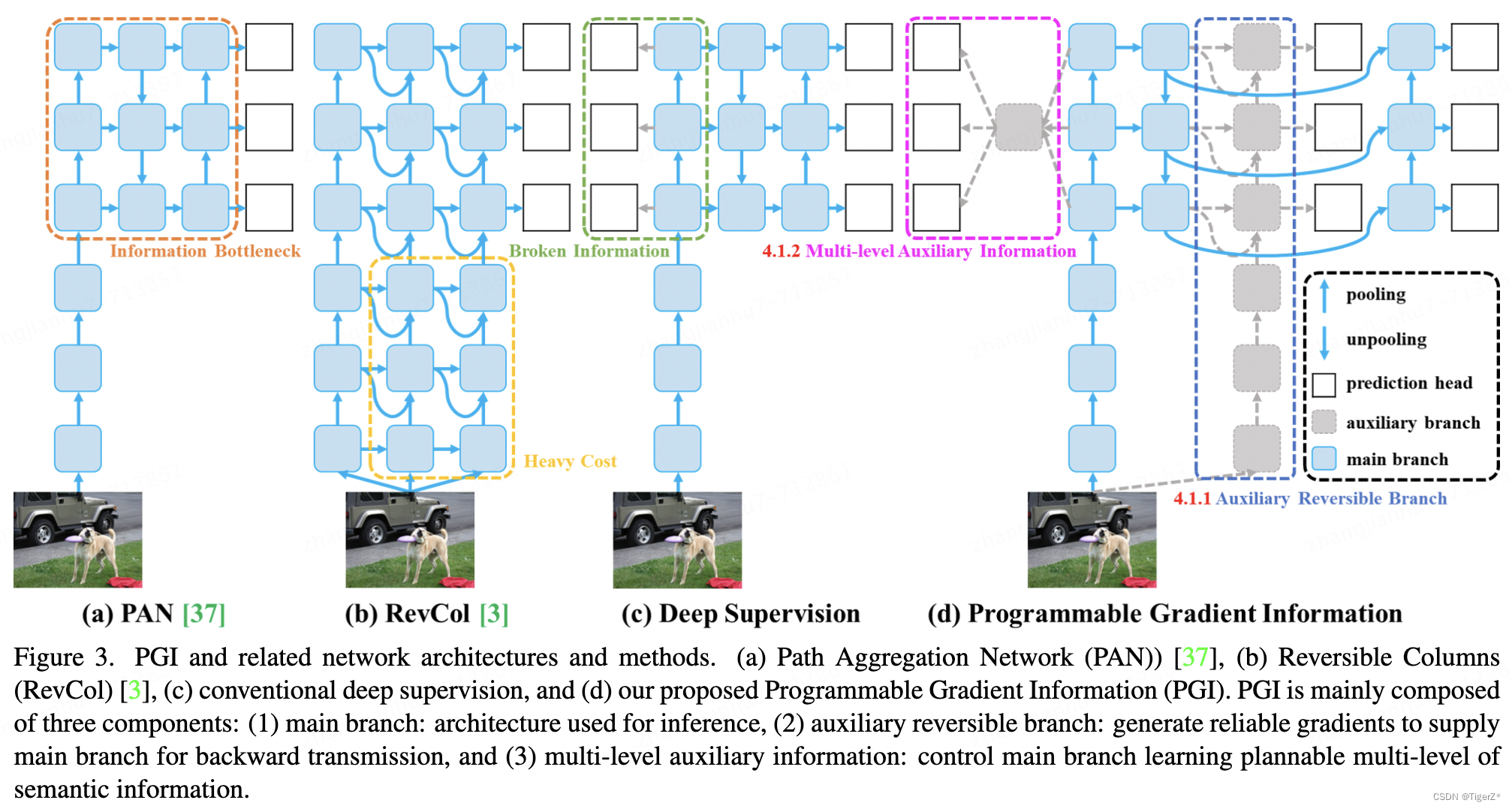
本文主要介绍了YOLOV9 算法的原理,并结合官方git 源码和其他人员的一些issue,更深层的尝试去探讨论文具体实现时的一些疑问。
主要记录使用NVIDIA GPU + pytorch + 检测系列模型的快速使用方式(包括:训练、测试、导出、量化),可以快速解决一些工业应用的问题,比如:无网、数据大需要改路径、需要记录不同实验结果等问题。

其实到了YOLOV5 基本创新点就不太多了,主要就是大家互相排列组合复用不同的网络模块、损失函数和样本匹配策略,V11支持多种视觉任务:物体检测、实例分割、图像分类、姿态估计和定向物体检测(OBB)。对比YOLOV8主要涉及到:*backbone 中的使用C2f模块 变为 c3k2 模块。*backbone 中的最后一层(sppf层)后增加了C2PSA模块。*head 解耦头中的分类检测头两个Co

本篇主要用于说明如何使用自己的训练数据,快速在YOLOV8 框架上进行训练。当前(20230116)官方文档和网上的资源主要都是在开源的数据集上进行测试,对于算法“小白”或者“老鸟”如何快速应用到自己的项目中,这个单纯看官方文档显得有点凌乱,因为YOLOV8 不再致力于做一个单纯算法,而是想要做一个一统(分类、检测、分割且多种模型)的框架。本文以检测为例。

1、主要贡献(优点)一阶段、快速、端到端训练*快速,pipline简单.*背景误检率低。*通用性强。YOLO对于艺术类作品中的物体检测同样适用。它对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法。2、主要思路通过全卷积网络,将输入图像映射为一个7*7*30 的张量,7*7是吧整个图像划为7*7个网格,每个网格设置2个预选框(训练可以理解为进化的思路),如下左图;30是每个位置的编码如下
场景:当我们使用YOLOV5训练模型时,官方的建议也是使用尽可能大的batch size这样BN更加的准确,训练速度也最快,但是当我们的batch size设置的过大会导致显卡内存溢出,而此时如果是多卡训练,很有可能出现长时间无法退出占用显存。解决方法:第一种:使用nvidia-smi,下方有对应的pid。可以使用kill命令杀掉进程,如下图,可以用如下命令:sudo kill -9 35346
yolov6 特性解读和完整的网络结构可视化。