- @u012374012
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
beginthreadex() 和 _endthreadex() 是 C运行时库(CRT) 提供的线程管理函数,用于创建和终止线程,并自动初始化与C运行时相关的资源(如线程局部存储、errno 等)。1. 线程是在thread对象被定义的时候开始执行的,而不是在调用join()函数时才执行的,调用join()函数只是阻塞等待线程结束并回收资源。过小的栈可能导致栈溢出,过大会浪费

你在写prompt时候,是不是总觉得大模型它不听话。要么答非所问、要么一堆废话。扒开思考过程仔细阅读时而觉得它聪明绝顶,时而又觉得它愚蠢至极。明明已经对了怎么又推理到错的地方去了,明明在提示词中提醒过了不要这么思考它怎么就瞎想了。这也许就是每一个Prompt Engineer的困扰。怎么能让模型按照要求去思考。长提示词到底应该怎么写,有没有方法可以一次命中,找到那个终极的提示词。答案是否定的,一篇
SAM3 通过文本提示进行图像分割的流程清晰且高效,主要包括模型初始化、图像预处理、文本提示设置、模型推理和结果可视化等步骤。这种基于文本提示的分割方式大大提升了交互性和实用性,使得用户可以通过简单的文本描述来精确分割感兴趣的图像区域。

传统目标检测器(如DINO、Grounding DINO)在定位精度上表现出色,但缺乏复杂语言理解能力;而多模态大语言模型(MLLM)虽然具备强语言理解能力,却在精细视觉定位上存在低召回率、坐标漂移和重复预测等问题。针对这一矛盾,本文提出了Rex-Omni——一个3B参数的MLLM模型,通过三大核心设计实现了高精度定位与强语言理解的统一:1)采用量化相对坐标表示,将坐标映射为1000个特殊toke

在此之前,我们已成功利用Docker与Ollama框架,在内网环境中部署了Qwen2模型。下面我们再来看一下使用Docker与vLLM框架部署Qwen2模型。

过去十年间,人工智能领域的大模型取得了飞跃式的发展。从最初的词向量表示,到能够Few-Shot(少样本)学习的千亿参数模型,再到多模态、可调用工具的最新模型,每一阶段的技术创新都推动着AI能力的里程碑式提升。本文将以通俗易懂的方式,通过研究25篇经典论文,沿时间顺序梳理大模型技术演进的关键节点,总结每个阶段具有代表性的经典工作及其里程碑意义。在深度学习兴起之前,计算机对单词的表示通常是“独热编码”

以下是 YOLOv8 训练实例分割任务的,包含「数据集准备→配置文件编写→训练代码→验证→推理→结果可视化」全流程,兼顾命令行和 Python 脚本两种方式,适配自定义数据集场景。
传统目标检测器(如DINO、Grounding DINO)在定位精度上表现出色,但缺乏复杂语言理解能力;而多模态大语言模型(MLLM)虽然具备强语言理解能力,却在精细视觉定位上存在低召回率、坐标漂移和重复预测等问题。针对这一矛盾,本文提出了Rex-Omni——一个3B参数的MLLM模型,通过三大核心设计实现了高精度定位与强语言理解的统一:1)采用量化相对坐标表示,将坐标映射为1000个特殊toke
视觉语言模型(Visual-Language Models, VLMs)是一种融合视觉信息与语言信息的多模态人工智能模型。它旨在通过同时处理图像、视频等视觉数据以及文本、语音等语言数据,实现对复杂场景的深度理解和生成。这种模型的核心在于打破视觉与语言之间的模态壁垒,使机器能够像人类一样综合运用视觉和语言能力来完成各种任务。在人工智能的发展历程中,视觉和语言一直是两个相对独立的研究领域。计算机视觉专
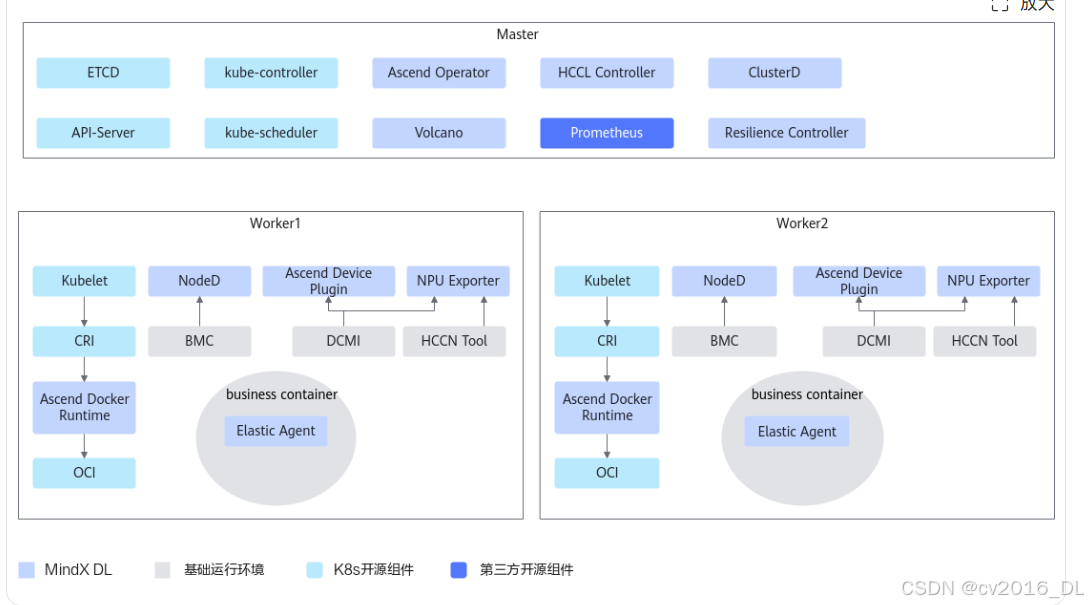
近日,LMDeploy 基于其强大的 PytorchEngine,增加了对华为昇腾设备的支持。这样一来,在华为昇腾上使用 LDMeploy 的方法与在英伟达 GPU 上使用 PytorchEngine 后端的方法几乎相同。因此,我们将在本期内容中为大家带来在华为昇腾设备上使用 LMDeploy 的方法。