




- @u011864458
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
过去几十年,中产阶级被视为现代社会稳定的基石,是经济增长的受益者与推动者。然而,近年来,从中国到美国,这一群体正经历前所未有的信心崩塌与生存危机。股市与楼市的“双杀”、产业转型的阵痛、人工智能的威胁,以及政策调整的冲击,共同构成了全球中产阶级的衰退图景。本文通过分析经济数据、社会结构理论及政策效应,揭示中产阶级危机的本质,并探讨其可能的出路。

摘要: 《2005:我在硅谷种AI》第8集聚焦AI模型可解释性。数学教授克劳森质疑神经网络将其手写"7"误判为"1",引发对"黑箱"AI的信任危机。主角陆眠团队开发了首层权重可视化技术,通过Matlab代码展示神经元学习的笔画特征,并创建决策热力图(Grad-CAM雏形)。本集探讨了"可解释性应是AI设计的内置天窗而非后门&qu

摘要 本文提出"创作即认知"理论框架,探讨叙事创作如何促进深度学习专业知识的内化与重构。研究突破传统"学习-应用"模式,建立"学习-解释-创造"三阶段认知深化模型,系统分析五个核心机制:解释性强迫实现原理性洞察、多视角压力测试强化知识稳固性、叙事逻辑重塑知识结构、隐喻锚定促进直觉理解、情感附着提升记忆效能。研究表明,针对复杂技术(如扩散模

几乎每一位AI从业者在初学阶段都接触过这样一种说法:“AI要解决的问题,最终都可以归结为四种基本范式——分类、回归、聚类和时序。” 这个论断常常出现在教材的导论章节,被奉为理解机器学习的入门钥匙。它简洁、易于记忆,给初学者一种似乎已经掌握了全局的错觉。然而,随着技术的飞速发展,特别是大语言模型、扩散模型和自监督学习的崛起,这个“四范式”分类法已经暴露出根本性的缺陷。它不仅混淆了不同维度的概念,更严
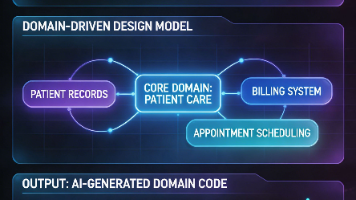
在生成式 AI 广泛介入软件开发之后,关于领域驱动设计(Domain-Driven Design, DDD)是否仍然必要的争论重新浮现。本文并不把 DDD 仅仅视为“微服务时代的遗产”,而是将其重构为一种面向复杂性的认知与建模方法:它通过统一语言、限界上下文、实体、值对象、聚合、领域事件等概念,将模糊业务知识转化为可讨论、可约束、可验证的结构化表述。本文采用规范分析与文献综述相结合的方法,以 Er
摘要:《词汇奥术师》**讲述语言学博士生林辰穿越异界,发现魔法与英语词汇存在神秘关联。首集中,他凭借精准发音念出"void"一词,意外使退婚契约失效。通过解读异界文字与现代英语的对应关系,林辰意识到自己可能掌握独特的语言魔法能力。故事巧妙融合语言学知识与奇幻元素,展现词汇的力量如何改变命运轨迹。核心词汇如void(无效)、vertigo(眩晕)等既推动剧情,又保留考研英语的学术

2025年,顶级渗透测试专家林轩,在测试量子加密系统时遭遇时空异常,意识坠回2010年——一个Wi-Fi仍普遍使用WEP加密、Windows XP系统漏洞百出的原始网络时代。他发现自己成了21岁濒死的同名大学生,身无分文,却背负着未来十五年完整的Kali Linux黑客兵器库与安全知识。在这个毫无防备的时代,他的每一次入侵都像用激光剑切开纸门,但危险也随之而来:神秘的黑客组织、来自未来的异常信号、

《硅基狂潮》是一部融合技术与商业的史诗作品,以GPU发展史为主线,讲述芯片创业的传奇故事。主角林风意外穿越回1993年,从亿万富翁变成失业工程师,在个人电脑寒冬中重新开始。作品通过真实的技术细节与产业规律,展现了一场颠覆性的芯片革命。从固定功能芯片到可编程架构的构想,林风将凭借超前视野,在硅谷寒冬中点燃技术创新的火种。这部作品既是技术创业者的启示录,也是对芯片行业黄金时代的深情回望。

crawl4ai-api 技术分析与问题解决指南 crawl4ai-api是一款结合异步爬虫与本地大语言模型(LLM)的工具,其主要特点包括:1)基于FastAPI的异步高效爬取能力;2)集成Ollama本地大模型实现智能内容提取;3)容器化部署简化环境配置。核心架构由API服务层、任务管理器、异步爬虫引擎和LLM提取引擎组成,支持从动态渲染页面提取结构化数据。 常见问题解决方案:1)环境搭建需确
摘要:《1990:种下那棵不落叶的树》以Linux开源系统为灵感,讲述程序员叶知秋穿越回1990年,在北大机房从零开始编写操作系统的故事。首集《玉兰与引导扇区》展现他与图书管理员沈书影的相遇,两人围绕计算机启动原理展开技术对话,通过512字节的引导扇区程序,折射出早期计算机开发的艰辛与理想。作品融合科技与人文,以“树”为意象,传递知识自由与技术创新精神。
