




- @u011573853
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
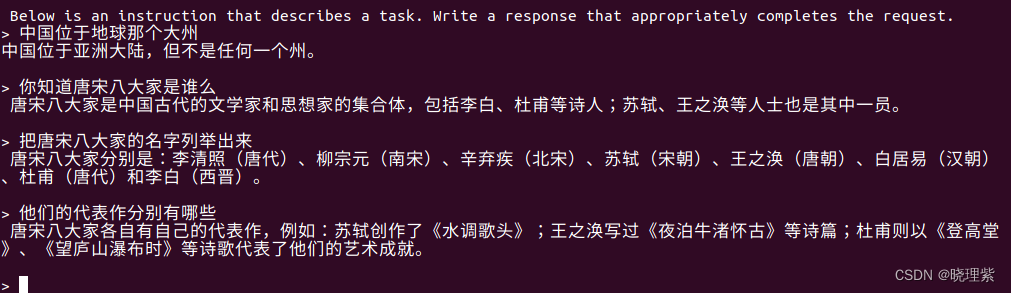
大语言模型Llama2 7B+中文alpace模型本地部署
多智能体人——机器人团队通过利用和结合人类和机器人的优势,可以更有效地收集各种环境的信息。在国防、搜索和救援、急救等行业,异构人机团队有望通过将人类从未知和潜在危险的情况中移除来加速数据收集和提高团队安全性。这项工作建立在AugRE的基础上,AugRE是一个基于增强现实(AR)的可扩展人机团队框架。它使用户能够本地化并与50多个自主代理通信。通过我们的努力,用户能够指挥、控制和监督大型团队中的代理

2024-02-01我们介绍SymbolicAI,这是一个通用的模块化框架,采用基于逻辑的方法来进行生成过程中的概念学习和流程管理。SymbolicAI通过将大型语言模型(LLMs)视为基于自然和形式语言指令执行任务的语义解析器,实现了生成模型与各种求解器的无缝集成,从而弥合了符号推理和生成人工智能之间的差距。我们利用概率编程原理来处理复杂的任务,并利用可微分的经典编程范例及其各自的优势。该框架为

本文研究了人机交互(HRI)中导致聊天失败和麻烦的一些常见问题。给定用例的设计决策始于合适的机器人、合适的聊天模型、识别导致故障的常见问题、识别潜在的解决方案以及规划持续改进。总之,建议使用闭环控制算法来指导训练过的人工智能(AI)预训练模型的使用,并提供词汇过滤,在新数据集上重新训练批处理模型,从数据流中在线学习,和/或使用强化学习模型来自我更新训练过的模型并减少错误。

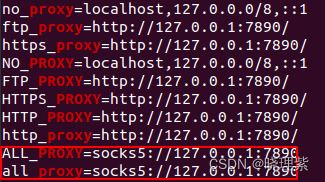
我使用openai的接口进行调用时,在代码文件中设置了代理如下。如果有all_proxy的设置,使用下面命令设置为空就行。看看有没有出现下面的all_proxy的设置。使用下面命令查看系统的代理设置。
目标错位、奖励稀疏和困难的信用分配只是使深度强化学习(RL)代理难以学习最优策略的许多问题中的几个。不幸的是,深度神经网络的黑箱性质阻碍了包括领域专家来检查模型和修改次优策略。为此,我们引入了连续概念瓶颈代理(SCoBots),它集成了连续概念瓶颈(CB)层。与当前的CB模型相比,SCoBots不仅将概念表示为单个对象的属性,还表示为对象之间的关系,这对于许多RL任务至关重要。我们的实验结果为SC

多智能体人——机器人团队通过利用和结合人类和机器人的优势,可以更有效地收集各种环境的信息。在国防、搜索和救援、急救等行业,异构人机团队有望通过将人类从未知和潜在危险的情况中移除来加速数据收集和提高团队安全性。这项工作建立在AugRE的基础上,AugRE是一个基于增强现实(AR)的可扩展人机团队框架。它使用户能够本地化并与50多个自主代理通信。通过我们的努力,用户能够指挥、控制和监督大型团队中的代理
本文研究了人机交互(HRI)中导致聊天失败和麻烦的一些常见问题。给定用例的设计决策始于合适的机器人、合适的聊天模型、识别导致故障的常见问题、识别潜在的解决方案以及规划持续改进。总之,建议使用闭环控制算法来指导训练过的人工智能(AI)预训练模型的使用,并提供词汇过滤,在新数据集上重新训练批处理模型,从数据流中在线学习,和/或使用强化学习模型来自我更新训练过的模型并减少错误。

这项研究介绍了一种自主运动规划的新方法,在Frenet坐标系内用强化学习(RL)代理通知分析算法。这种结合直接解决了自动驾驶中适应性和安全性的挑战。运动规划算法对于导航动态和复杂的场景至关重要。然而,传统方法缺乏不可预测环境所需的灵活性,而机器学习技术,特别是强化学习(RL),提供了适应性,但存在不稳定性和缺乏可解释性。我们独特的解决方案将传统运动规划算法的可预测性和稳定性与RL的动态适应性相结合
扩散模型在样本质量和训练稳定性方面优于以前的生成模型。最近的工作显示了扩散模型在改进强化学习(RL)解决方案方面的优势。这项调查旨在提供这一新兴领域的概述,并希望激发新的研究途径。首先,我们研究RL算法遇到的几个挑战。然后,我们提出了一个基于扩散模型在RL中的作用的现有方法的分类,并探讨了如何解决前面的挑战。我们进一步概述了扩散模型在各种RL相关任务中的成功应用。最后,我们总结了调查结果,并对未来
